- C++智能指针如何解决内存泄露问题.
1.shared_ptr共享的智能指针
std::shared_ptr使用引用计数,每一个shared_ptr的拷贝都指向相同的内存。在最后一个shared_ptr析构的时候,内存才会被释放。
可以通过构造函数、std_make_shared辅助函数和reset方法来初始化shared_ptr:
// 构造函数初始化
std::shared_ptrp ( new int(1) ) ;
std::shared_ptrp2 = p ;
// 对于一个未初始化的智能指针,可以通过reset方法来初始化。
std::shared_ptrptr; ptr.reset ( new int (1) ) ;
if (ptr) {cout << “ptr is not null.\n” ; }
不能将一个原始指针直接赋值给一个智能指针:
std::shared_ptrp = new int(1) ;// 编译报错,不允许直接赋值
获取原始指针:

通过get方法来返回原始指针
std::shared_ptrptr ( new int(1) ) ;
int * p =ptr.get () ;
指针删除器:
智能指针初始化可以指定删除器
void DeleteIntPtr ( int * p ) {
delete p ;
}
std::shared_ptrp ( new int , DeleteIntPtr ) ;
当p的引用技术为0时,自动调用删除器来释放对象的内存。删除器也可以是一个lambda表达式,例如
std::shared_ptrp ( new int , [](int * p){delete p} ) ;
注意事项:
(1).不要用一个原始指针初始化多个shared_ptr。
(2).不要再函数实参中创建shared_ptr,在调用函数之前先定义以及初始化它。
(3).不要将this指针作为shared_ptr返回出来。
(4).要避免循环引用。
2.unique_ptr 独占的智能指针
unique_ptr是一个独占的智能指针,他不允许其他的智能指针共享其内部的指针,不允许通过赋值将一个unique_ptr赋值给另外一个unique_ptr。
unique_ptr不允许复制,但可以通过函数返回给其他的unique_ptr,还可以通过std::move来转移到其他的unique_ptr,这样它本身就不再拥有原来指针的所有权了。
如果希望只有一个智能指针管理资源或管理数组就用unique_ptr,如果希望多个智能指针管理同一个资源就用shared_ptr。
3.weak_ptr弱引用的智能指针
弱引用的智能指针weak_ptr是用来监视shared_ptr的,不会使引用计数加一,它不管理shared_ptr内部的指针,主要是为了监视shared_ptr的生命周期,更像是shared_ptr的一个助手。
weak_ptr没有重载运算符*和->,因为它不共享指针,不能操作资源,主要是为了通过shared_ptr获得资源的监测权,它的构造不会增加引用计数,它的析构不会减少引用计数,纯粹只是作为一个旁观者来监视shared_ptr中关离得资源是否存在。
weak_ptr还可以用来返回this指针和解决循环引用的问题。
- linux中软连接和硬链接的区别.
原理上,硬链接和源文件的inode节点号相同,两者互为硬链接。软连接和源文件的inode节点号不同,进而指向的block也不同,软连接block中存放了源文件的路径名。
实际上,硬链接和源文件是同一份文件,而软连接是独立的文件,类似于快捷方式,存储着源文件的位置信息便于指向。
使用限制上,不能对目录创建硬链接,不能对不同文件系统创建硬链接,不能对不存在的文件创建硬链接;可以对目录创建软连接,可以跨文件系统创建软连接,可以
对不存在的文件创建软连接。
- TCP的拥塞控制机制是什么?请简单说说
我们知道TCP通过一个定时器(timer)采样了RTT并计算RTO,但是,如果网络上的延时突然增加,那么,TCP对这个事做出的应对只有重传数据,然而重传会导致网络的负担更重,于是会导致更大的延迟以及更多的丢包,这就导致了恶性循环,最终形成“网络风暴” —— TCP的拥塞控制机制就是用于应对这种情况。
首先需要了解一个概念,为了在发送端调节所要发送的数据量,定义了一个“拥塞窗口”(Congestion Window),在发送数据时,将拥塞窗口的大小与接收端ack的窗口大小做比较,取较小者作为发送数据量的上限。
拥塞控制主要是四个算法:
1.慢启动:意思是刚刚加入网络的连接,一点一点地提速,不要一上来就把路占满。
连接建好的开始先初始化cwnd = 1,表明可以传一个MSS大小的数据。
每当收到一个ACK,cwnd++; 呈线性上升
每当过了一个RTT,cwnd = cwnd*2; 呈指数让升
阈值ssthresh(slow start threshold),是一个上限,当cwnd >= ssthresh时,就会进入“拥塞避免算法”
2.拥塞避免:当拥塞窗口 cwnd 达到一个阈值时,窗口大小不再呈指数上升,而是以线性上升,避免增长过快导致网络拥塞。
每当收到一个ACK,cwnd = cwnd + 1/cwnd
每当过了一个RTT,cwnd = cwnd + 1
拥塞发生:当发生丢包进行数据包重传时,表示网络已经拥塞。分两种情况进行处理:
等到RTO超时,重传数据包
sshthresh = cwnd /2
cwnd 重置为 1
3.进入慢启动过程
在收到3个duplicate ACK时就开启重传,而不用等到RTO超时
sshthresh = cwnd = cwnd /2
进入快速恢复算法——Fast Recovery
4.快速恢复:至少收到了3个Duplicated Acks,说明网络也不那么糟糕,可以快速恢复。
cwnd = sshthresh + 3 * MSS (3的意思是确认有3个数据包被收到了)
重传Duplicated ACKs指定的数据包
如果再收到 duplicated Acks,那么cwnd = cwnd +1
如果收到了新的Ack,那么,cwnd = sshthresh ,然后就进入了拥塞避免的算法了。
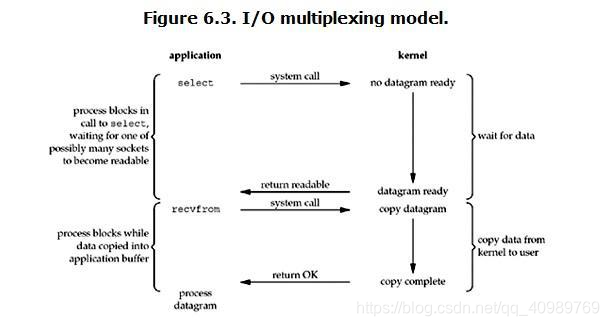
- 如何理解IO多路复用的三种机制Select,Poll,Epoll?
1.Select
首先先分析一下select函数
int select(
int maxfdp1,
fd_set *readset,
fd_set *writeset,
fd_set *exceptset,
const struct timeval *timeout
);
【参数说明】
int maxfdp1 指定待测试的文件描述字个数,它的值是待测试的最大描述字加1。
fd_set *readset , fd_set *writeset , fd_set *exceptset
fd_set可以理解为一个集合,这个集合中存放的是文件描述符(file descriptor),即 文件句柄。中间的三个参数指定我们要让内核测试读、写和异常条件的文件描述符集合。 如果对某一个的条件不感兴趣,就可以把它设为空指针。
const struct timeval *timeout timeout告知内核等待所指定文件描述符集合中的任 何一个就绪可花多少时间。其timeval结构用于指定这段时间的秒数和微秒数。
【返回值】
int 若有就绪描述符返回其数目,若超时则为0,若出错则为-1
select运行机制
select()的机制中提供一种fd_set的数据结构,实际上是一个long类型的数组,每一 个数组元素都能与一打开的文件句柄(不管是Socket句柄,还是其他文件或命名管道或 设备句柄)建立联系,建立联系的工作由程序员完成,当调用select()时,由内核根 据IO状态修改fd_set的内容,由此来通知执行了select()的进程哪一Socket或文件 可读。
从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还 多了添加监视socket,以及调用select函数的额外操作,效率更差。但是,使用select 以后最大的优势是用户可以在一个线程内同时处理多个socket的IO请求。用户可以注 册多个socket,然后不断地调用select读取被激活的socket,即可达到在同一个线程 内同时处理多个IO请求的目的。而在同步阻塞模型中,必须通过多线程的方式才能达 到这个目的。
select机制的问题
每次调用select,都需要把fd_set集合从用户态拷贝到内核态,如果fd_set集合很 大时,那这个开销也很大
同时每次调用select都需要在内核遍历传递进来的所有fd_set,如果fd_set集合很 大时,那这个开销也很大
为了减少数据拷贝带来的性能损坏,内核对被监控的fd_set集合大小做了限制,并且 这个是通过宏控制的,大小不可改变(限制为1024).
2.Poll
poll的机制与select类似,与select在本质上没有多大差别,管理多个描述符也是 进行轮询,根据描述符的状态进行处理,但是poll没有最大文件描述符数量的限制。 也就是说,poll只解决了上面的问题3,并没有解决问题1,2的性能开销问题。
下面是pll的函数原型:
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
typedef struct pollfd {
int fd; // 需要被检测或选择的文件描述符
short events; // 对文件描述符fd上感兴趣的事件
short revents; // 文件描述符fd上当前实际发生的事件
} pollfd_t;
poll改变了文件描述符集合的描述方式,使用了pollfd结构而不是select的fd_set 结构,使得poll支持的文件描述符集合限制远大于select的1024
【参数说明】
struct pollfd *fds fds是一个struct pollfd类型的数组,用于存放需要检测其状 态的socket描述符,并且调用poll函数之后fds数组不会被清空;一个pollfd结构 体表示一个被监视的文件描述符,通过传递fds指示 poll() 监视多个文件描述符。其 中,结构体的events域是监视该文件描述符的事件掩码,由用户来设置这个域,结构 体的revents域是文件描述符的操作结果事件掩码,内核在调用返回时设置这个域
nfds_t nfds 记录数组fds中描述符的总数量
【返回值】
int 函数返回fds集合中就绪的读、写,或出错的描述符数量,返回0表示超时,返回 -1表示出错;
Epoll
epoll在Linux2.6内核正式提出,是基于事件驱动的I/O方式,相对于select来说, epoll没有描述符个数限制,使用一个文件描述符管理多个描述符,将用户关心的文件 描述符的事件存放到内核的一个事件表中,这样在用户空间和内核空间的copy只需一 次。
Linux中提供的epoll相关函数如下:
int epoll_create(int size);
int epoll_ctl(
int epfd,
int op, int fd,
struct epoll_event *event
);
int epoll_wait(
int epfd,
struct epoll_event * events,
int maxevents,
int timeout
);
1).epoll_create 函数创建一个epoll句柄,参数size表明内核要监听的描述符数量。 调用成功时返回一个epoll句柄描述符,失败时返回-1。
2).epoll_ctl 函数注册要监听的事件类型。四个参数解释如下:
epfd 表示epoll句柄
op 表示fd操作类型,有如下3种
EPOLL_CTL_ADD 注册新的fd到epfd中
EPOLL_CTL_MOD 修改已注册的fd的监听事件
EPOLL_CTL_DEL 从epfd中删除一个fd
fd 是要监听的描述符
event 表示要监听的事件
epoll_event 结构体定义如下:
struct epoll_event {
__uint32_t events; /* Epoll events */
epoll_data_t data; /* User data variable */
};
typedef union epoll_data {
void *ptr;
int fd;
__uint32_t u32;
__uint64_t u64;
} epoll_data_t;
3). epoll_wait 函数等待事件的就绪,成功时返回就绪的事件数目,调用失败时返回 -1,等待超时返回 0。
⑴epfd 是epoll句柄
⑵events 表示从内核得到的就绪事件集合
⑶maxevents 告诉内核events的大小
⑷timeout 表示等待的超时事件
epoll是Linux内核为处理大批量文件描述符而作了改进的poll,是Linux下多路复用 IO接口select/poll的增强版本,它能显著提高程序在大量并发连接中只有少量活跃 的情况下的系统CPU利用率。原因就是获取事件的时候,它无须遍历整个被侦听的描述 符集,只要遍历那些被内核IO事件异步唤醒而加入Ready队列的描述符集合就行了。
epoll除了提供select/poll那种IO事件的水平触发(Level Triggered)外,还提供 了边缘触发(Edge Triggered),这就使得用户空间程序有可能缓存IO状态,减少 epoll_wait/epoll_pwait的调用,提高应用程序效率。
⑴水平触发(LT):默认工作模式,即当epoll_wait检测到某描述符事件就绪并 通知应用程序时,应用程序可以不立即处理该事件;下次调用epoll_wait时,会 再次通知此事件
⑵边缘触发(ET): 当epoll_wait检测到某描述符事件就绪并通知应用程序时, 应用程序必须立即处理该事件。如果不处理,下次调用epoll_wait时,不会再次 通知此事件。(直到你做了某些操作导致该描述符变成未就绪状态了,也就是说边 缘触发只在状态由未就绪变为就绪时只通知一次)。
LT和ET原本应该是用于脉冲信号的,可能用它来解释更加形象。Level和Edge指的就 是触发点,Level为只要处于水平,那么就一直触发,而Edge则为上升沿和下降沿的 时候触发。比如:0->1 就是Edge,1->1 就是Level。
ET模式很大程度上减少了epoll事件的触发次数,因此效率比LT模式下高。
- linux内核调度详细说一下
1.1、调度策略
定义位于linux/include/uapi/linux/sched.h中
SCHED_NORMAL:普通的分时进程,使用的fair_sched_class调度类
SCHED_FIFO:先进先出的实时进程。当调用程序把CPU分配给进程的时候,它把该进程描述符保留在运行队列链表的当前位置。此调度策略的进程一旦使用CPU则一直运行。如果没有其他可运行的更高优先级实时进程,进程就继续使用CPU,想用多久就用多久,即使还有其他具有相同优先级的实时进程处于可运行状态。使用的是rt_sched_class调度类。
SCHED_RR:时间片轮转的实时进程。当调度程序把CPU分配给进程的时候,它把该进程的描述符放在运行队列链表的末尾。这种策略保证对所有具有相同优先级的SCHED_RR实时进程进行公平分配CPU时间,使用的rt_sched_class调度类
SCHED_BATCH:是SCHED_NORMAL的分化版本。采用分时策略,根据动态优先级,分配CPU资源。在有实时进程的时候,实时进程优先调度。但针对吞吐量优化,除了不能抢占外与常规进程一样,允许任务运行更长时间,更好使用高速缓存,适合于成批处理的工作,使用的fair_shed_class调度类
SCHED_IDLE:优先级最低,在系统空闲时运行,使用的是idle_sched_class调度类,给0号进程使用
SCHED_DEADLINE:新支持的实时进程调度策略,针对突发型计算,并且对延迟和完成时间敏感的任务使用,基于EDF(earliest deadline first),使用的是dl_sched_class调度类。
1.2、调度触发
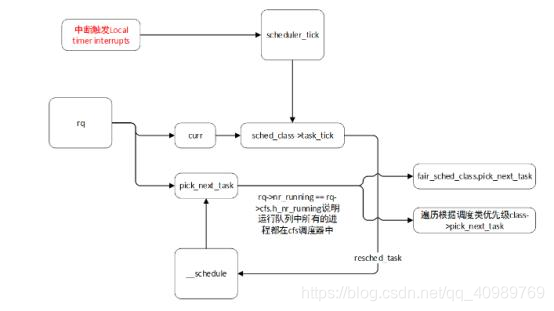
调度的触发主要有两种方式,一种是本地定时中断触发调用scheduler_tick函数,然后使用当前运行进程的调度类中的task_tick,另外一种则是主动调用schedule,不管是哪一种最终都会调用到__schedule函数,该函数调用pick_netx_task,通过rq->nr_running ==rq->cfs.h_nr_running判断出如果当前运行队列中的进程都在cfs调度器中,则直接调用cfs的调度类(内核代码里面这一判断使用了likely说明大部分情况都是满足该条件的)。如果运行队列不都在cfs中,则通过优先级stop_sched_class->dl_sched_class->rt_sched_class->fair_sched_class->idle_sched_class遍历选出下一个需要运行的进程。然后进程任务切换。
处于TASK_RUNNING状态的进程才会被进程调度器选择,其他状态不会进入调度器。系统发生调度的时机如下:
à调用cond_resched()时
à显式调用schedule()时
à从中断上下文返回时
当内核开启抢占时,会多出几个调度时机如下:
à在系统调用或者中断上下文中调用preemt_enable()时(多次调用系统只会在最后一次调用时会调度)
à在中断上下文中,从中断处理函数返回到可抢占的上下文时
2、CFS调度
该部分代码位于linux/kernel/sched/fair.c中
定义了const struct sched_classfair_sched_class,这个是CFS的调度类定义的对象。其中基本包含了CFS调度的所有实现。
CFS实现三个调度策略:
1> SCHED_NORMAL这个调度策略是被常规任务使用
2> SCHED_BATCH 这个策略不像常规的任务那样频繁的抢占,以牺牲交互性为代价下,因而允许任务运行更长的时间以更好的利用缓存,这种策略适合批处理
3> SCHED_IDLE 这是nice值甚至比19还弱,但是为了避免陷入优先级导致问题,这个问题将会死锁这个调度器,因而这不是一个真正空闲定时调度器
CFS调度类:
n enqueue_task(…) 当任务进入runnable状态,这个回调将把这个任务的调度实体(entity)放入红黑树并且增加nr_running变量的值
n dequeue_task(…) 当任务不再是runnable状态,这个回调将会把这个任务的调度实体从红黑树中取出,并且减少nr_running变量的值
n yield_task(…) 除非compat_yield sysctl是打开的,这个回调函数基本上就是一个dequeue后跟一个enqueue,这那种情况下,他将任务的调度实体放入红黑树的最右端
n check_preempt_curr(…) 这个回调函数是检查一个任务进入runnable状态是否应该抢占当前运行的任务
n pick_next_task(…) 这个回调函数选出下一个最合适运行的任务
n set_curr_task(…) 当任务改变他的调度类或者改变他的任务组,将调用该回调函数
n task_tick(…) 这个回调函数大多数是被time tick调用。他可能引起进程切换。这就驱动了运行时抢占
2.1、CFS调度
Tcik 中断,主要会更新调度信息,然后调整当前进程在红黑树中的位置。调整完成以后如果当前进程不再是最左边的叶子,就标记为Need_resched标志,中断返回时就会调用scheduler()完成切换、否则当前进程继续占用CPU。从这里可以看出CFS抛弃了传统时间片概念。Tick中断只需要更新红黑树。
红黑树键值即为vruntime,该值通过调用update_curr函数进行更新。这个值为64位的变量,会一直递增,__enqueue_entity中会将vruntime作为键值将要入队的实体插入到红黑树中。__pick_first_entity会将红黑树中最左侧即vruntime最小的实体取出。
- 如何计算struct占用的内存?
1.每个成员按其类型大小和指定对齐参数n中较小的一个进行对齐
2.确定的对齐参数必须能够整除起始地址(或偏移量)
3.偏移地址和成员占用大小均需对齐
4.结构体成员的对齐参数为其所有成员使用的对齐参数的最大值
5.结构体总长度必须为所有对齐参数的整数倍
#include<stdio.h>
struct test
{
char a;
int b;
float c;
};
int main(void)
{
printf(“char=%d\n”,sizeof(char));
printf(“int=%d\n”,sizeof(int));
printf(“float=%d\n”,sizeof(float));
printf(“struct test=%d\n”,sizeof(struct test));
return 0;
}
执行结果为1,4,4,12
占用内存空间的计算过程:
对齐参数为4。假设结构体的起始地址为0x0
a 的类型为char,因此所占内存空间大小为1个字节,小于对齐参数4,所以选择1为对齐数,而地址0x0能够被1整除,所以0x0为a的起始地址,占用空间大小为1个字节;
b 的类型为 int ,所占内存空间大小为4个字节,与对齐参数相同,因此4为对齐数,0x1不能被4整除,因此不能作为b的起始地址,依次往下推,只能选用0x4作为b 的起始地址,因此中间会空出3个字节的空余空间;
c的类型为float,占用4个字节,因此4为对齐数,0x8能被4整除,所以c的起始地址为0x8
因此整个结构体占用的内存大小为12字节。
- mysql为什么要使用B+树作为索引呢?
b树的特点:
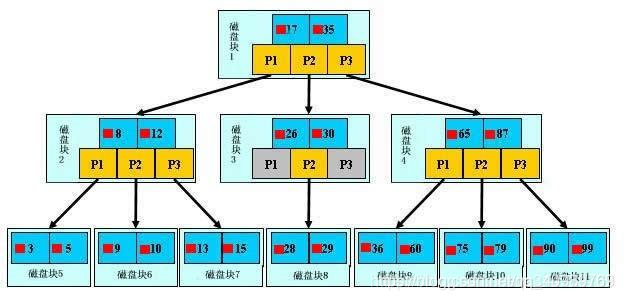
一个M阶的b树具有如下几个特征: (如下图M=3)(下文的关键字可以理解为 有效数据,而不是单纯的索引)
定义任意非叶子结点最多只有M个儿子,且M>2;
根结点的儿子数为[2, M];
除根结点以外的非叶子结点的儿子数为[M/2, M],向上取整; (儿子数:[2,3])
非叶子结点的关键字个数=儿子数-1;(关键字=2)
所有叶子结点位于同一层;
k个关键字把节点拆成k+1段,分别指向k+1个儿子,同时满足查找树的大小关系。(k=2)
有关b树的一些特性,注意与后面的b+树区分:
关键字集合分布在整颗树中;
任何一个关键字出现且只出现在一个结点中;
搜索有可能在非叶子结点结束;
其搜索性能等价于在关键字全集内做一次二分查找;
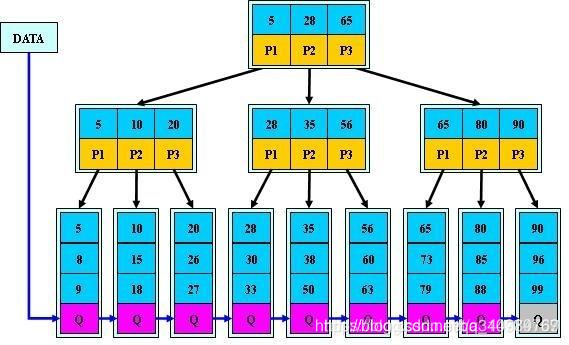
b+树,是b树的一种变体,查询性能更好。m阶的b+树的特征:
有n棵子树的非叶子结点中含有n个关键字(b树是n-1个),这些关键字不保存数据,只用来索引,所有数据都保存在叶子节点(b树是每个关键字都保存数据)。
所有的叶子结点中包含了全部关键字的信息,及指向含这些关键字记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
所有的非叶子结点可以看成是索引部分,结点中仅含其子树中的最大(或最小)关键字。
通常在b+树上有两个头指针,一个指向根结点,一个指向关键字最小的叶子结点。
同一个数字会在不同节点中重复出现,根节点的最大元素就是b+树的最大元素。
选用B+树作为数据库的索引结构的原因有
B+树的中间节点不保存数据,是纯索引,但是B树的中间节点是保存数据和索引的,相对来说,B+树磁盘页能容纳更多节点元素,更“矮胖”;
B+树查询必须查找到叶子节点,B树只要匹配到即可不用管元素位置,因此b+树查找更稳定(并不慢);
对于范围查找来说,B+树只需遍历叶子节点链表即可,B树却需要重复地中序遍历,在项目中范围查找又很是常见的
增删文件(节点)时,效率更高,因为B+树的叶子节点包含所有关键字,并以有序的链表结构存储,这样可很好提高增删效率。
- 请解释下为什么鹿晗发布恋情的时候,微博系统会崩溃,如何解决?
鹿晗首先是一个明星,流量明星。粉丝量众多,所以,他已公布恋情,瞬间的流量很大。但是我们要注意到,这里面有一个问题。就是这个瞬间流量增大,增的不仅是浏览量。如果仅仅是阅读,我们只需把鹿晗的这条微博放入 Redis 缓存,以微博技术,不可能挂得了的吧。
这个之所以微博挂掉,是因为这个时间段,转发 + 评论量非常的大,并不是只有阅读量大。
另外针对明星的微博,会有一个消息推送功能。第一时间热点数据,只要你联的有网,都能够收到推送。
最后总结如下:
-
获取微博通过 pull 方式还是 push 方式
-
发布微博的频率要远小于阅读微博
-
流量明星的发微博,和普通博主要区分对待,比如在 sharding的时候,也要考虑这个因素
9.求任意一颗二叉树最长路径长度
样例:如下所示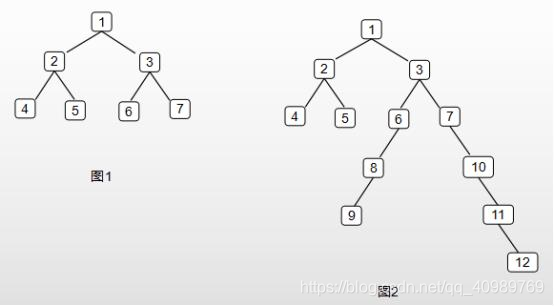
最新字节跳动社招精选面试题及参考答案
图1树的最长路径长度为4,图2的最长路径长度为7,图1最长路径经过根节点,顶点为1,图2不经过,顶点为3
思路:
树中任意两个节点之间,连接起来的路径最长。方法就是求出每个节点的左子树和右子树的高度,两者相加就是当前节点的最长路径,然后比较每个节点的最长路径,最大的就是结果
实现方法:
定义一个静态变量MaxLength记录每一步最大长度,采取前序遍历来遍历每一个节点,在遍历过程中,对当前节点的最长路径进行比较,对于每一个节点最长路径求法,先求出它左子树和右子树的高度(节点数最多的路径),然后相加即为当前节点最长路径
static Integer MaxLength=0;//记录最长路径
//遍历整棵树,得到最长路径
public void getLength(TreeNode t){
if(t!=null){
MaxLength=Math.max(LengthTree(t),MaxLength);
getLength(t.lchild);
getLength(t.rchild);
}
}
//得到当前节点的最长路径
public int LengthTree(TreeNode t){
if (t==null)
return 0;
int left=heighTree(t.lchild);
int right=heighTree(t.rchild);
int CurMax=left+right;
return CurMax;
}
//求二叉树最大高度
public int heighTree(TreeNode t){
if (t==null)
return 0;
else
return Math.max(heighTree(t.lchild),heighTree(t.rchild))+1;
}
- redis中的网络IO有了解过吗,它是单线程的还是多线程的,为什么要用单线程。
redis 采用网络IO多路复用技术来保证在多连接的时候,系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路I/O
复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,所以采用单线程
由于篇幅有限,今天就分享到这里,需要更多大厂面试题可以加Q群563998835领取

