基于Fabric+IPFS大规模数据上链方案
更多区块链技术与应用分类:
区块链应用 区块链开发
以太坊 | Fabric | BCOS | 密码技术 | 共识算法 | 比特币 | 其他链
通证经济 | 传统金融场景 | 去中心化金融 | 防伪溯源 | 数据共享 | 可信存证
第一章 系统综述
区块链是创造信任的机器,但是数据存储与读取的效率十分低下,两者不可兼得的情况下,一种新的方式,既弥补区块链的效率,又能利用其“信任”与“不可篡改”特性。该方案使用区块链+分布式存储。
Fabric简介、适用场景:Hyperledger Fabric的出现是对传统区块链模型的一种革新,在某种程度上允许创建授权和非授权的区块链,Hyperledger还通过提供一个针对身份识别,可审计、隐私安全和健壮的模型,使得缩短计算周期、提高规模效率和响应各个行业的应用需求成为可能。
IPFS简介、适用场景:分布式存储。
Fabric+IPFS优点、适用场景:无需全部数据上链即可产生信任。
本系统以后台服务开发为核心,作为链接客户端、IPFS及Fabric区块链的服务部件,如图1所示。当大量数据需要可靠实时地存储,并且在未来需要得到验证时,必须将数据以某种形式存入区块链。而传统区块链系统为了“安全”而牺牲“效率”,因此其数据存储的容量与速率非常低下,因此不能存放大规模数据。基于这种考虑,我们可以利用区块链+分布式存储的方式解决大规模数据上链的问题,将原始数据存于类似IPFS等分布式系统中,并将源文件的地址存储于区块链永久保存,用户可以通过区块链上文件的地址信息随时去获取这些数据。同时为了保证IPFS上数据不被篡改,必须将文件的指纹(Hash算法结果)也一并存入区块链,这样用户可以将得到的链上数据进行验证,以确定数据的完整性与可靠性。
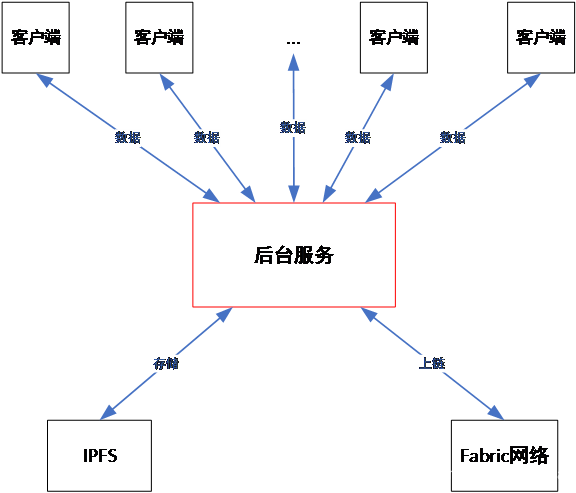
图1-后台服务架构
后台服务采用nodejs编写,总体功能可分为两部分:
- 数据存储:后台可将数据打包成块并向IPFS发送,所有数据存储在IPFS上,然后将IPFS上文件存储地址以及文件指纹存在Fabric区块链网络上,这样可公开验证数据。
- 数据查询:客户端可以通过查询内容的方式,即基于内容检索得到Fabric以及IPFS上具体信息。
1.3 运行环境
-
硬件支持:
- 本后台服务需要Fabric区块链网络以及IPFS节点的支持。
- Fabric若以伪集群的方式运行,则推荐配置为四核cpu内存8G,操作系统centos7 /Windows10配置或以上。
- IPFS运行单节点,推荐配置为单核cpu内存2G操作系统centos7 /Windows10配置或以上。
- Nodejs服务推荐配置为双核cpu内存2G操作系统centos7 /Windows10配置或以上。
-
软件支持:
- go-ipfs version: 0.4.18
- nodejs version: 8.1.0
- go version :go1.9.2 windows/amd64
- docke version: 18.09.2
- docker-compose version: 1.23.2
- Hyperledger Fabric version: 1.1.0
- ipfs version: 0.4.18
第二章 功能详述
2.1 软件功能流程图
该后台软件主要处理大规模数据上链,因此重在数据存储和数据查询两部分逻辑,整个流程图如图2所示。当数据存储时,后台服务不断收到来自客户端的数据时,每接受一条数据需要先判断是否是正确的传输格式,并统计该客户端发送数据条数。每个不同的客户端有唯一ID,数据以ID作为索引键值,故以“天”为单位进行数据块打包,即一天的数据作为一个独立数据块,这样方便管理和查询。在达到预定义区块大小(一日的数据量)时对客户端数据进行分块打包,每次打包完块后立即存入IPFS,并获取IPFS存储块的地址。然后,将该数据块的IPFS地址以及文件指纹存入Fabric区块链进行保存。
当数据查询时,客户端发起请求获取原始数据,服务启动Fabric链,然后查询链码是否存在该ID、日期下的IPFS地址信息,若不存在,这说明不存在数据,否则继续查询IPFS。根据IPFS上对应数据块文件的Hash地址从IPFS上拿到原始数据,并可以利用Fabric上文件指纹与IPFS上原始数据进行比对验证,若两者一致则可以确定该数据块未被篡改。

图2-软件流程图
2.2 功能设计详细描述
1 数据存储
数据存储功能实现流程图如图3所示,下面是详细步骤:
(1) 客户端通过http-post方式以特定数据格式(Json)向后台服务发送数据
该后端服务会记录每一个连接的客户端处发来数据数目,并更新其数据文件指纹,当达到预设值时,进行打包操作,并使用流的方式向IPFS发送数据。
(2) 数据块存储在IPFS上,然后返回存储地址
(3) 后台服务将先前计算的文件指纹与IPFS文件存储地址组合且生成新的一条上链数据,然后通过调用Fabric链码将信息存储在Peer节点账本上。
(4) Fabric向服务端返回本次存储交易的Hash值。
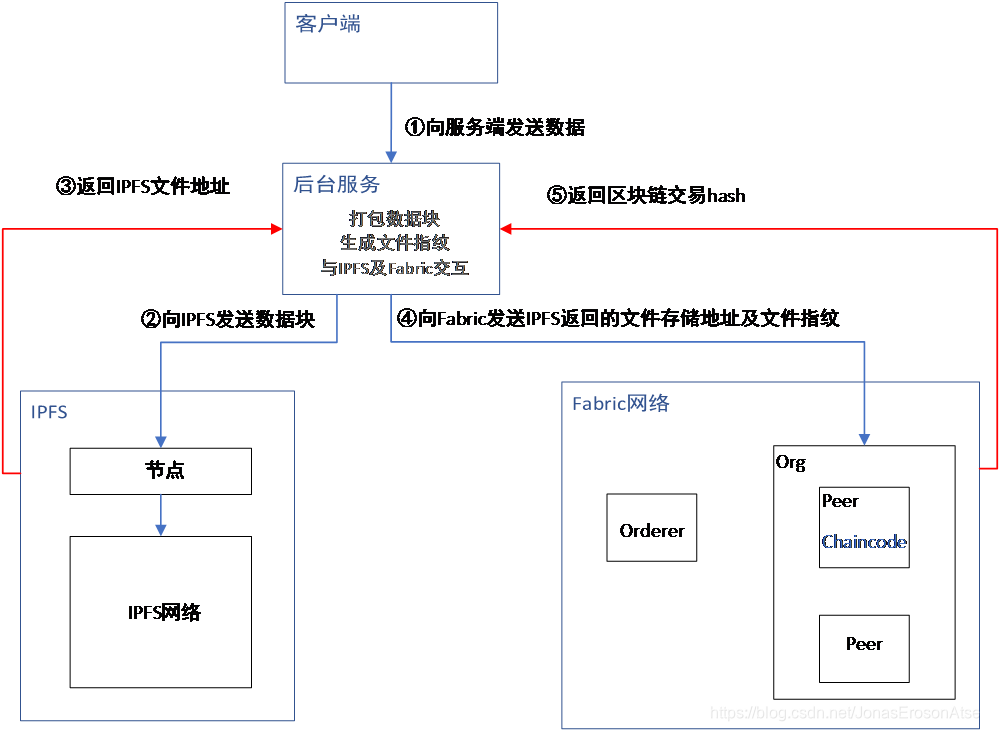 图3 数据存储功能实现流程图
图3 数据存储功能实现流程图
2 数据查询
数据查询功能实现流程图如图4所示,下面是详细步骤:
(1) 客户端通过唯一ID值和日期等内容查询相关信息,通过http-get方式向服务后台请求数据。例如请求url:http://localhost:60003/querydata?obdid=X7777-S6665&date=2019-4-3 ,是用户查询的接口,意思是ID为X7777-S6665日期为2019-4-3这天的该日数据块。
(2) 后台将会自动启动Fabric链码容器,执行链码中相应的查询方法。
(3) Fabric将匹配正确的数据(包含IPFS文件存储地址以及文件指纹)返回。例如如下信息:
{“obdid”:“X7777-S6665”,“dataDate”:“2019-4-3”,“ipfsAddr”:“QmfQJujeYWgX2Fn15nSLY7xApG7qQo3imz9S3UVxRcRiTi”,“fileFingerprint”:“21358B2F61C5B5DDD515F7046765BA43E8B643DCE26985BFD45A1BD02E9201A8”}
(4) 后台通过Fabric数据中的IPFS文件存储地址去查询IPFS网络,并返回匹配的整个数据块。
(5) IPFS根据Hash地址返回对应的整个数据块的文件信息,随后在服务端可以进行对文件的验证,以检验存储数据是否被篡改。
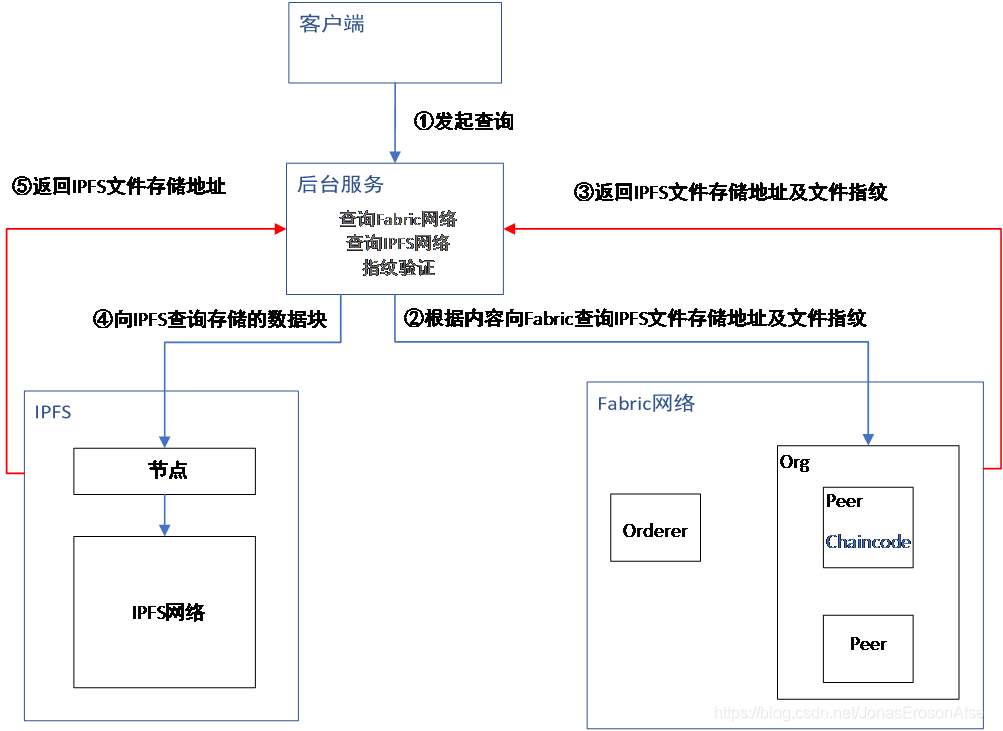
图4 数据查询功能实现流程图
2.3 存储结构
(1) Fabric账本结构
Fabric账本结构指的是Fabric网络中相应通道中Peer节点存储数据的格式,如图5所示。Fabric以<k,v>键值对的形式存储及查询数据,因此唯一ID作为主“键”,所有信息存于该键下(采用Json嵌套格式)。这样,每个ID下存储所有该ID相关的所有信息。当查询时,使用唯一ID值便可查出所有该ID下的值。
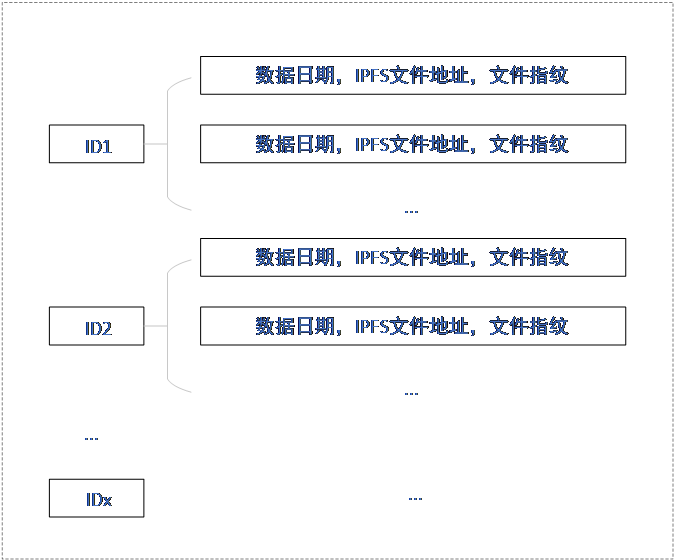
图5 Fabric账本结构
(2) IPFS存储结构:
IPFS中存储所有源数据的数据块,数据块存储没有顺序,只是每个数据块与hash地址的关系一一对应,如图6所示。而hash地址与具体信息的映射关系存储于Fabric区块链中。
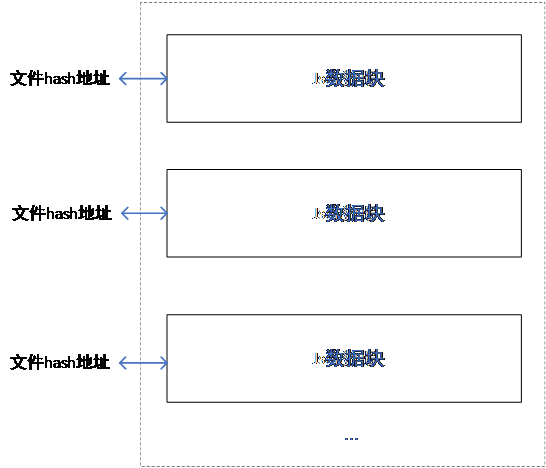
图6 IPFS存储结构
第三章 运行说明
3.1 运行说明
(1)客户端上传数据
用户通过http-post方式向服务后台传输Json数据,新客户端向服务端不断发送数据,启动模拟数据服务(每秒向后台发送一次数据),以车辆obd数据上链为例,打印日志如图7所示:
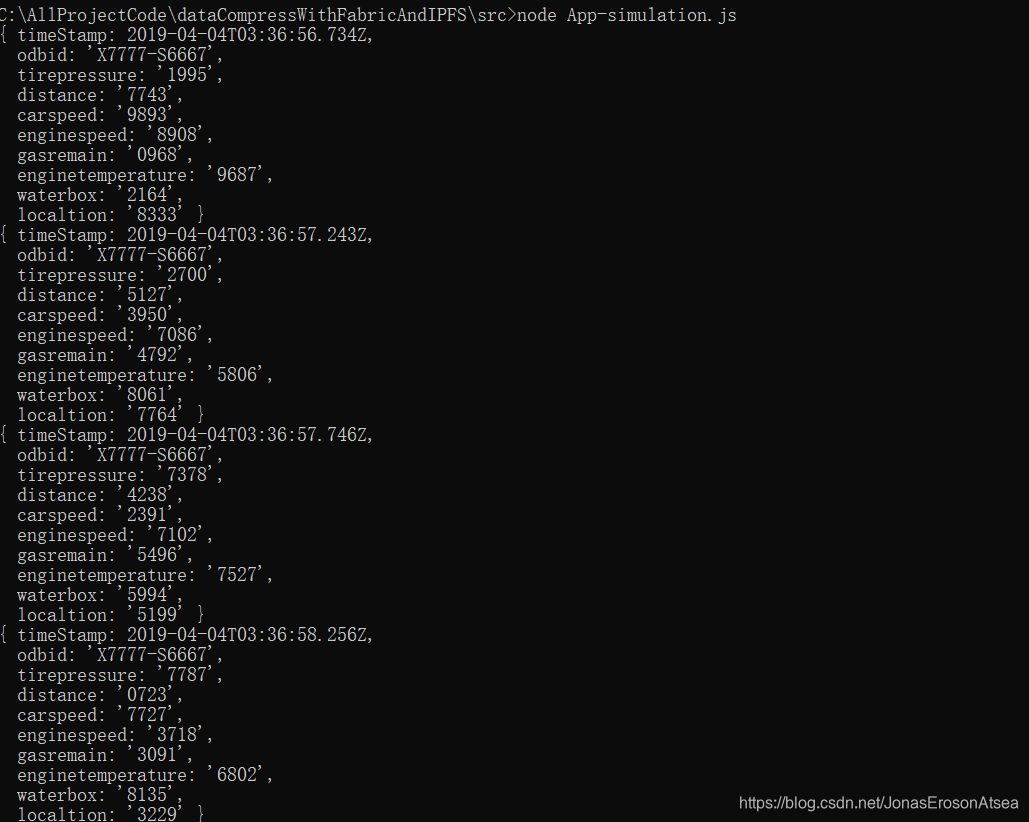
图7 模拟数据发送日志
(2) 后端接受数据并处理
后台系统网络全部启动完毕之后(Fabric网络启动,IPFS启动),使用命令运行nodejs后台程序:node server.js
当数据块打包完成时,后台日志如图8所示:
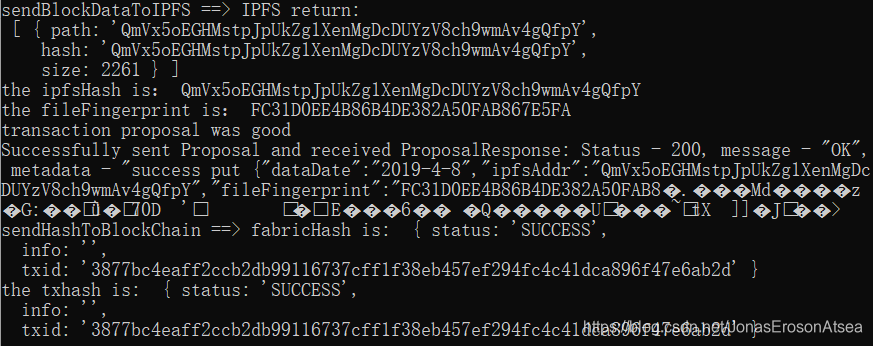
图8 后台服务打包区块时日志
(3) 客户端查询/验证数据
查询fabric区块链网络上相关数据:通过唯一ID(obdid)以及日期来查询fabric上文件存储记录,可以得到IPFS上文件存储地址ipfsAddr,文件的指纹哈希fileFingerprint。http-get获取数据结果如图9所示:
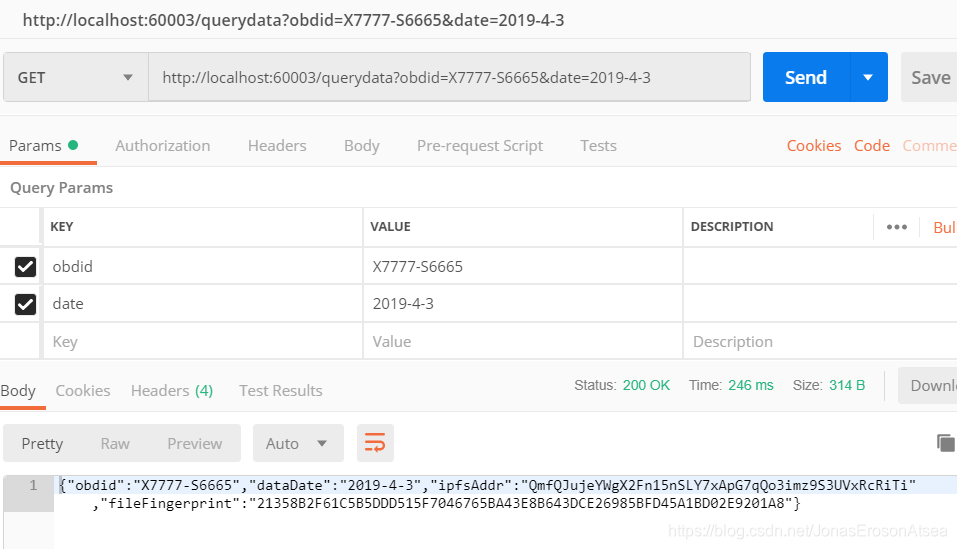
图9 用户通过内容获取Fabric数据
查询IPFS上相关数据:将ipfsAddr作为http-post的参数传给服务器,通过该ipfsAddr可以再次查询到IPFS上整个数据块,如图10所示。客户端可以对整个数据块进行指纹验证,计算数据块指纹与fileFingerprint参数比较,若一致,则证明数据完整未被篡改。
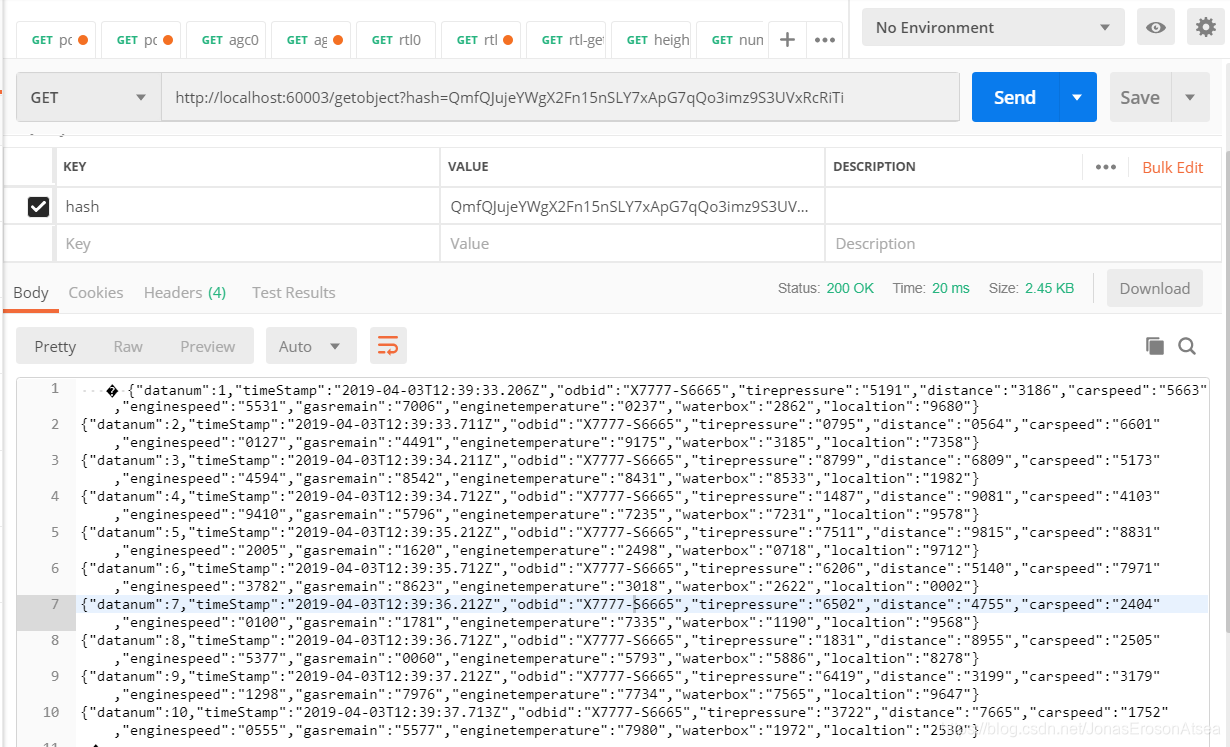
图10 用户通过Hash获取IPFS数据
代码库可进行验证测试:
https://github.com/wanghaoyi1/dataCompressWithFabricAndIPFS.git