什么?SpringBoot项目启动报循环依赖异常
今天,我启动项目项目报循环依赖异常了,为了说明我这里简化了。
我的代码是这样(模拟)的
@Component
public class TestA {
@Autowired
private TestB testB;
@Async("taskExecutor")
public TestB getTestB(){
return testB;
}
}
@Component
public class TestB {
@Autowired
private TestA testA;
public void testTrans() {
testA.getTestA();
System.out.println("testTrans线程名称:" + Thread.currentThread().getName());
}
}
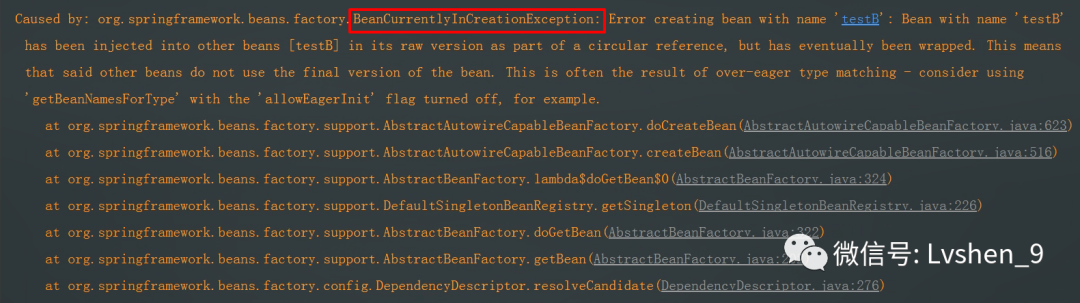
这里是TestA调用了TestB,TestB里面又调用了TestA。是一个典型的循环依赖场景,但是我们知道Spring对于循环依赖问题是做了处理的。但是这里为什么会报错?
![]()
循环依赖关联
为此我们来分析下Spring是如何解决循环依赖问题的。
循环依赖出现场景
我们来看看哪些情况属于循环依赖。
对象M的创建依赖S的创建,并且S的创建又依赖M的创建。
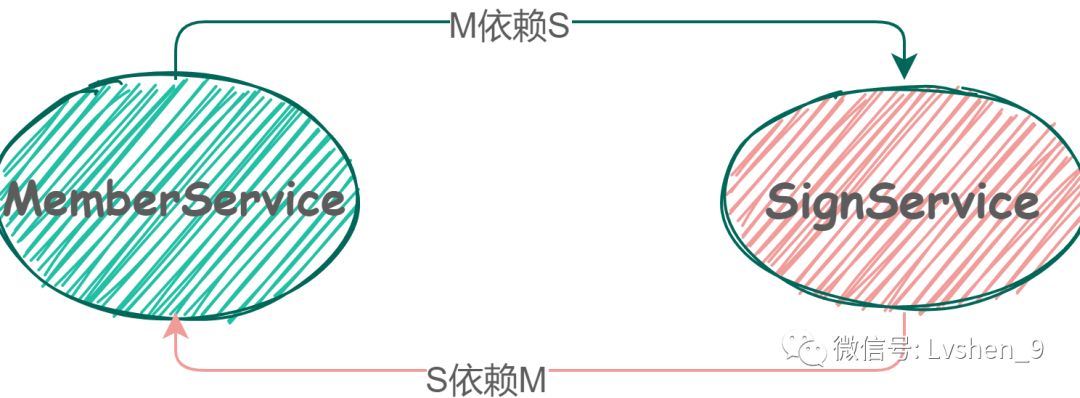
循环依赖定义1
对象M的创建依赖S的创建,S的创建依赖O的创建,O的创建依赖M的创建。这样也形成了一个闭环。
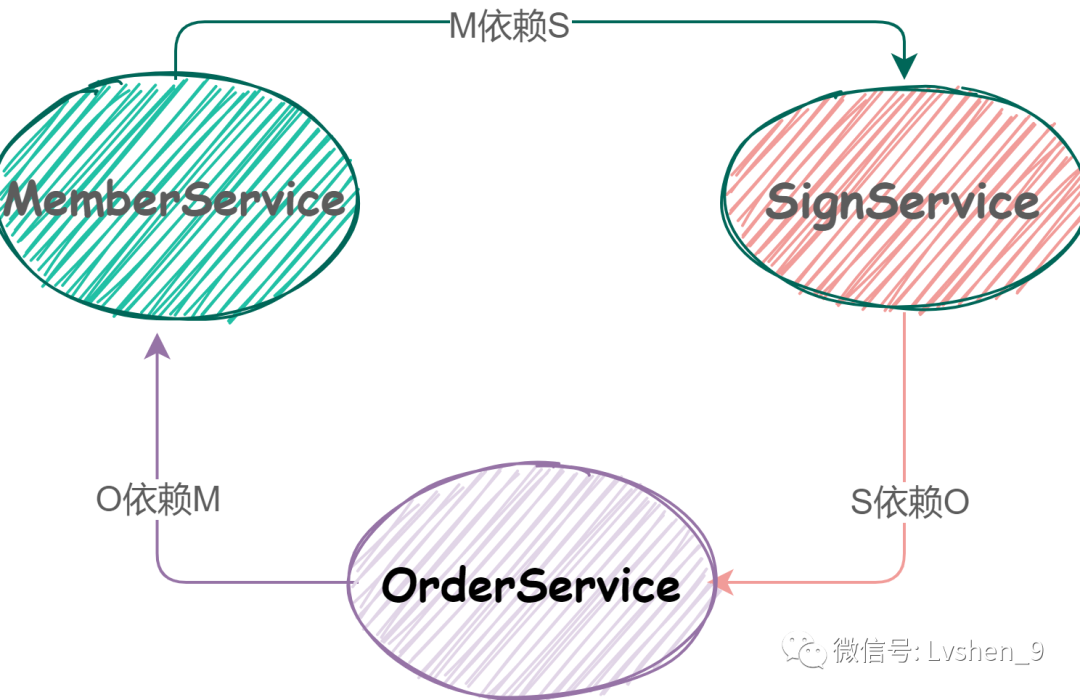
循环依赖定义2
还有自己依赖自己的。
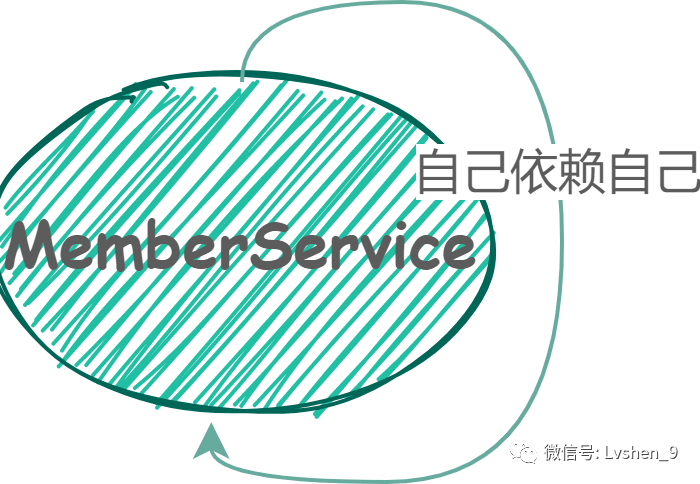
循环依赖定义3
Bean实例化流程
我们来看看Spring容器如何获取bean流程的。
首先进入getBean()方法,里面调用了doGetBean()方法。
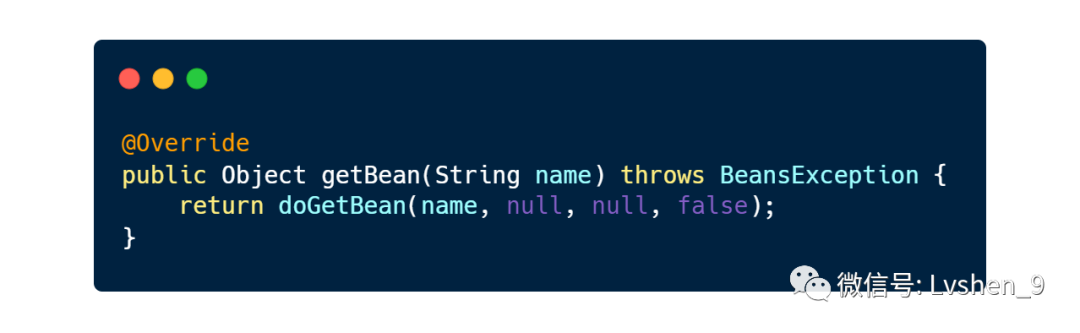
doGetBean()方法中,调用了getSingleton()方法,用于获取sharedInstance实例。
![]()
getSingleton()方法如下:
![]()
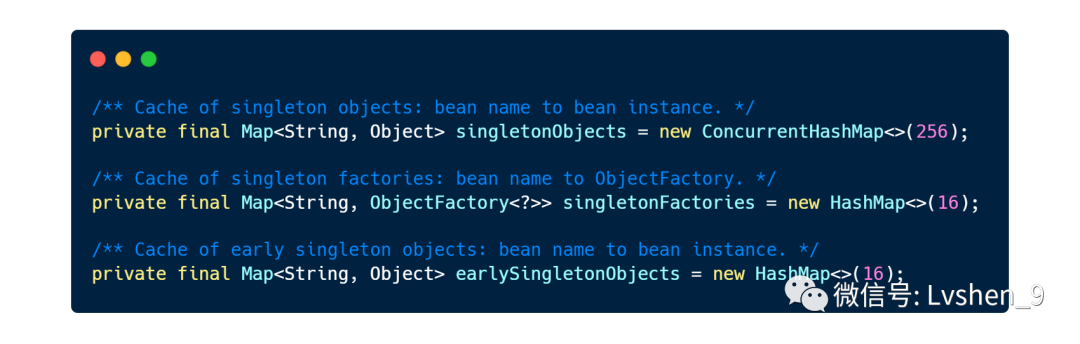
这个方法主要是从缓存中获取bean的单例,这里会判断,如果当前待获取的单列存在循环依赖,就会从其他缓存里面获取。我们先来看看bean实例主要从哪几个缓存里面获取。
“”
singletonObjects
earlySingletonObjects
singletonFactories
缓存的数据结构为map:
那么这几个缓存是做什么用的呢?
首先我们要了解bean初始化经历的步骤

bean初始化
singletonObjects:完全初始化的对象都存入次map中
earlySingletonObjects:早期实例化对象,就是这个对象在内存中已经开辟了空间,但是并未填充里面的属性。这个缓存就是二级缓存,用于解决循环依赖。
singletonFactories:在属性填充之后,初始化之前。如果允许提前曝光,会将实例化的bean添加到此缓存 中,这里就是我们说的三级缓存。
那么,是如何从缓存里面获取实例的?
-
先从
singletonObjects获取实例,singletonObjects中的实例都是准备好的 bean 实例,可以直接使用; -
如果发现取出的实例为null或者正在创建中,就去二级缓存中获取;
-
如果二级缓存中没有,从三级缓存中获取;
-
如果三级缓存中有,将其移动到二级缓存中;
-
如果三级缓存没有,直接返回null。
Object sharedInstance = getSingleton(beanName);
当三级缓存返回null,也就是sharedInstance值为null。这时会创建bean。
创建bean的方法如下:
createBean(beanName, mbd, args);
createBean()方法调用了如下方法
Object beanInstance = doCreateBean(beanName, mbdToUse, args);
里面会执行
instanceWrapper = createBeanInstance(beanName, mbd, args);
接下来调用addSingletonFactory,将bean添加到singletonFactories 缓存(三级缓存)。
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
接下来再执行populateBean()
populateBean(beanName, mbd, instanceWrapper);
populateBean()主要是向早期bean中填充属性,如果发现bean A在填充属性时需要依赖bean B,会创建B对象。这时发现B在填充属性值时有需要依赖A,就会从三级缓存中获取还未填充属性值的bean A。这时就可以把 A 对象的原始引用注入 B 对象(并将其移动到二级缓存)来解决循环依赖问题。这时候 getObject() 方法就算执行结束了,返回完全实例化的 bean。
最后将完全实例化好的bean对象存入一级缓存singletonObjects中。
我们来看看获取bean的流程图:
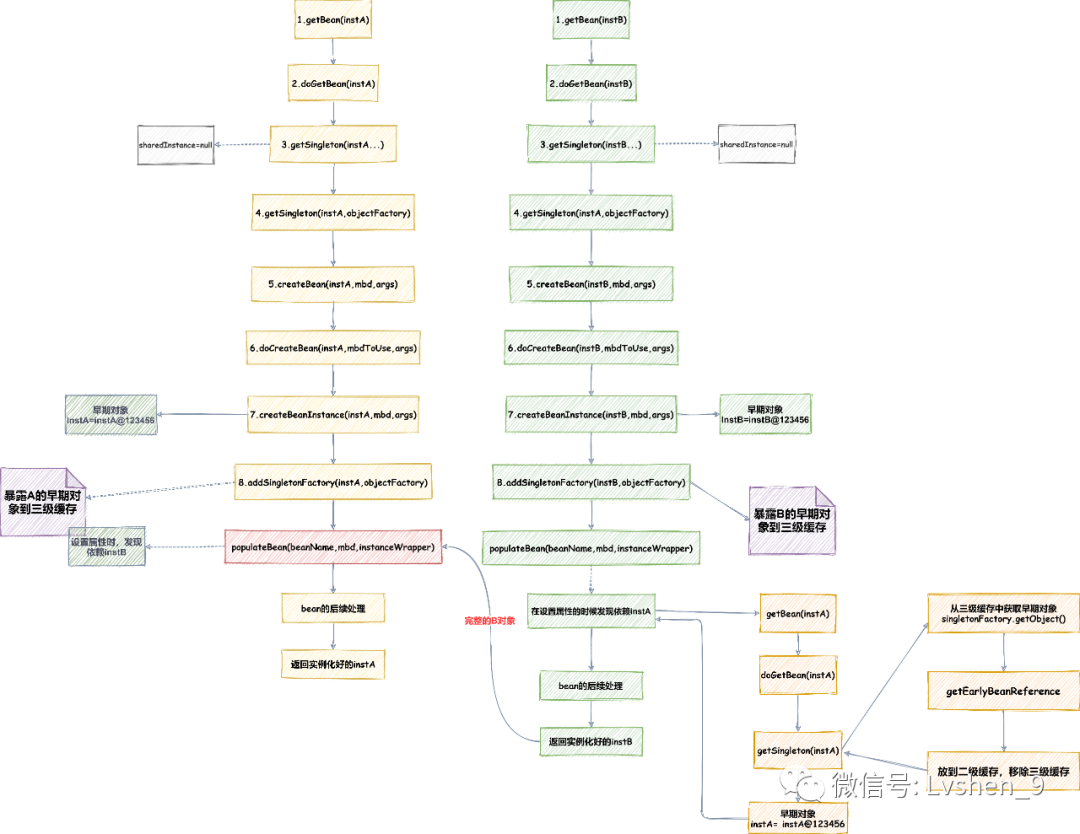
循环依赖解决图
从上面可知,出现循序环依赖时,会从三级缓存中获取早期曝光的bean,然后将其移动到二级缓存。
只用二级缓存可以解决循环依赖问题么
这时候你是不是有疑问,为什么需要三级缓存?二级缓存能否解决循环依赖问题呢?
我们来看这段代码
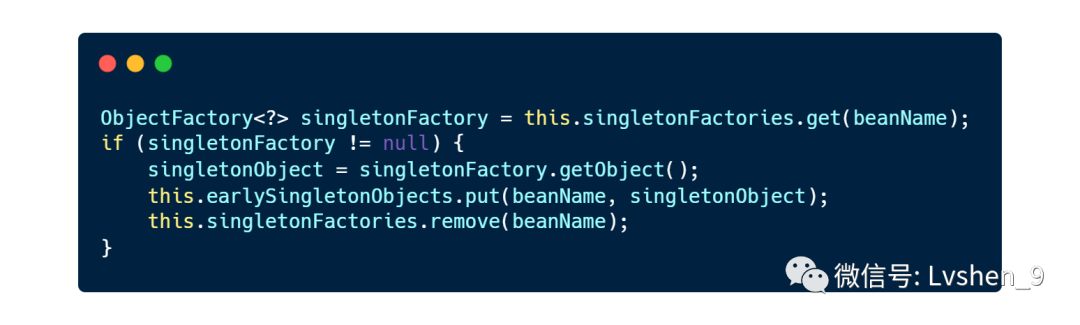
如果获取的对象是一个代理对象,这里的singletonFactory.getObject()会生成新的代理对象,为了保证只有一个代理对象,需要选用缓存来缓存代理对象。
那么回到文章开头的问题,标注了@Async注解的方法的bean,为什么Spring没有解决循环依赖问题。
实际上@Async的代理它默认并不支持你去循环引用,因为它并没有把代理对象的早期引用提供出来。@Async的代理对象不是在getEarlyBeanReference()中创建的,是在postProcessAfterInitialization创建的代理。
那么你可能有疑问@Transactional注解的实现不是和@Async样么,那会出现循环依赖问题么。答案是不会出现,因为@Transactional使用的是自动代理创建器AbstractAutoProxyCreator,它实现了getEarlyBeanReference()方法从而很好的对循环依赖提供了支持。
除了@Async,@Validated也会出现同样问题哦。
往期推荐
扫码二维码,获取更多精彩。或微信搜Lvshen_9,可后台回复获取资料
1.回复"java" 获取java电子书;
2.回复"python"获取python电子书;
3.回复"算法"获取算法电子书;
4.回复"大数据"获取大数据电子书;
5.回复"spring"获取SpringBoot的学习视频。
6.回复"面试"获取一线大厂面试资料
7.回复"进阶之路"获取Java进阶之路的思维导图
8.回复"手册"获取阿里巴巴Java开发手册(嵩山终极版)
9.回复"总结"获取Java后端面试经验总结PDF版
10.回复"Redis"获取Redis命令手册,和Redis专项面试习题(PDF)
11.回复"并发导图"获取Java并发编程思维导图(xmind终极版)另:点击【我的福利】有更多惊喜哦。