文章目录
Redis
前言
由于前面进行的压力测试,分析获取首页信息的吞吐量是非常低的,对于此,我们对逻辑进行了优化,将多次查询数据库改为一次查询,然后在java逻辑中拼凑自己想要的数据,然后又进行了压力测试,吞吐量虽然有所提升,但是还是不满意,后来又对数据库字段加了索引,吞吐量也有所提升,但变化不大,接下来如果还想优化的话,可以从缓存方面进行优化,首页的东西基本上是读多写少的,为了迎合这个业务场景,可以采用加缓存的方案。
将部分数据放入缓存中,加速访问,而DB承担数据落盘的工作
首先我们需要考虑哪些数据需要放到缓存当中:
- 即时性、数据一致性要求不高的,比如物流、商品分类、商品列表等这些都适合加缓存并加一个失效时间(根据数据更新频率来定)
- 访问量大且更新频率不高的数据,也就是我们常说的读多写少的场景,就比如,后台发布商品,买家5分钟才看到这个消息也是可以接受的
对于那些即时性、数据一致性要求高的或者经常更新的数据,那就去数据库中查吧!
加入缓存的逻辑
我们先来梳理一下加入缓存的逻辑
- 首先,我们加入缓存的内容是什么?如果整个项目都是用java实现的,那么我们可以直接采用jdk序列化之后存入到redis当中,但是在一个大项目,我们要考虑到跨平台兼容、跨语言等各种问题,所以采用json串的形式存入,因为json是跨语言、跨平台兼容的
- 存的逻辑就是,先将对象转成json串,存到redis当中,取的逻辑就是将从redis当中获取的信息再逆转过来,这就是序列化与反序列化的过程。
在使用redis的时候有小插曲
在完成基本的逻辑的时候,我进行了压力测试,出现了一个堆外内存溢出异常,具体原因如下:
- SpringBoot 2.0以后默认使用lettuce作为redis客户端,它底层使用netty进行了网络通信
- lettuce的bug导致堆外内存溢出,当我将jvm启动参数 -Xmx调大之后发现,还是没有解决问题,迟早还是会出现异常,因为堆外内存溢出并不堆内内存,而是堆外内存,那可以通过 -Dio.netty.maxDirectMemory进行设置,但是会发现,异常还是会出现,它的作用只是去调大内存了,而并不是从根上解决
- 解决方案:(1)、升级Lettuce客户端 (2) 切换使用Jedis;我采用的是第二种方案
到此为止,就觉得缓存就这样就可以了吗?答案当然是否定的,在高并发情况下,如果仅仅是这样的操作,那就会带来一系列的问题!
比如:缓存穿透、缓存雪崩、缓存击穿,接下来说一下我在项目中是怎么解决的
缓存常见问题及我在项目中的解决方案
先来解释下概念:
- 缓存穿透:它是去查询一个缓存中没有并且数据库中也没有的数据,被不法分子恶意攻击的,去查询一个根本不存在的数据,突然向数据库打过来十几万的请求,那肯定会崩的
- 缓存雪崩:这个是针对在缓存中一批key在同一时刻过期,而十几万的并发请求都是来请求这些数据的,那么就会将请求打到数据库中,造成数据库宕机,这也就是雪崩效应
- 缓存击穿:针对缓存中某一极度热点的key在某一时刻过期,这是打来十几万的并发请求,都去请求数据库,造成数据库宕机
解决方案:
- 缓存穿透:(我采取的方案是缓存一个空值并设置短暂的过期时间)
- 通过缓存一个空值,并且加一个过期时间
- 通过布隆过滤器,挡住根本不存在的数据,但这种方案会存在一定的误判
- 缓存雪崩:
- 应对大量key在同一时间过期,我们可以采取在设置过期时间的时候加上一个随机值来应对
- 缓存击穿:
- 通过加锁来实现,当大量请求打过来的时候,采用加锁的方式,让某一个线程去数据库中查,然后将查出来的数据放入到缓存中
来看看我的代码:
//去数据库中查的业务逻辑
private Map<String, List<Catelog2Vo>> getDataFromDb() {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
String catalogJson = stringRedisTemplate.opsForValue().get("catalogJson");
if (!StringUtils.isEmpty(catalogJson)) {
//缓存不为空直接返回
Map<String, List<Catelog2Vo>> result = JSON.parseObject(catalogJson, new TypeReference<Map<String, List<Catelog2Vo>>>() {
});
return result;
}
System.out.println("查询了数据库");
/**
* 将数据库的多次查询变为一次
*/
List<CategoryEntity> selectList = this.baseMapper.selectList(null);
//1、查出所有分类
//1、1)查出所有一级分类
List<CategoryEntity> level1Categorys = getParent_cid(selectList, 0L);
//封装数据
Map<String, List<Catelog2Vo>> parentCid = level1Categorys.stream().collect(Collectors.toMap(k -> k.getCatId().toString(), v -> {
//1、每一个的一级分类,查到这个一级分类的二级分类
List<CategoryEntity> categoryEntities = getParent_cid(selectList, v.getCatId());
//2、封装上面的结果
List<Catelog2Vo> catelog2Vos = null;
if (categoryEntities != null) {
catelog2Vos = categoryEntities.stream().map(l2 -> {
Catelog2Vo catelog2Vo = new Catelog2Vo(v.getCatId().toString(), null, l2.getCatId().toString(), l2.getName().toString());
//1、找当前二级分类的三级分类封装成vo
List<CategoryEntity> level3Catelog = getParent_cid(selectList, l2.getCatId());
if (level3Catelog != null) {
List<Catelog2Vo.Category3Vo> category3Vos = level3Catelog.stream().map(l3 -> {
//2、封装成指定格式
Catelog2Vo.Category3Vo category3Vo = new Catelog2Vo.Category3Vo(l2.getCatId().toString(), l3.getCatId().toString(), l3.getName());
return category3Vo;
}).collect(Collectors.toList());
catelog2Vo.setCatalog3List(category3Vos);
}
return catelog2Vo;
}).collect(Collectors.toList());
}
return catelog2Vos;
}));
//3、将查到的数据放入缓存,将对象转为json
String valueJson = JSON.toJSONString(parentCid);
stringRedisTemplate.opsForValue().set("catalogJson", valueJson, 1, TimeUnit.DAYS);
return parentCid;
}
/**
* 从数据库查询并封装数据::本地锁
* @return
*/
public Map<String, List<Catelog2Vo>> getCatalogJsonFromDbWithLocalLock() {
// //如果缓存中有就用缓存的
// Map<String, List<Catelog2Vo>> catalogJson = (Map<String, List<Catelog2Vo>>) cache.get("catalogJson");
// if (cache.get("catalogJson") == null) {
// //调用业务
// //返回数据又放入缓存
// }
//只要是同一把锁,就能锁住这个锁的所有线程
//1、synchronized (this):SpringBoot所有的组件在容器中都是单例的。
//TODO 本地锁:synchronized,JUC(Lock),在分布式情况下,想要锁住所有,必须使用分布式锁
synchronized (this) {
//得到锁以后,我们应该再去缓存中确定一次,如果没有才需要继续查询
return getDataFromDb();
}
}
看到上面的代码,是不是觉得设置一下本地锁就没什么问题了?如果是单体应用的话是完全ok的,但是对于分布式项目,还是有一部分问题的,我来画幅图给大家看一下:
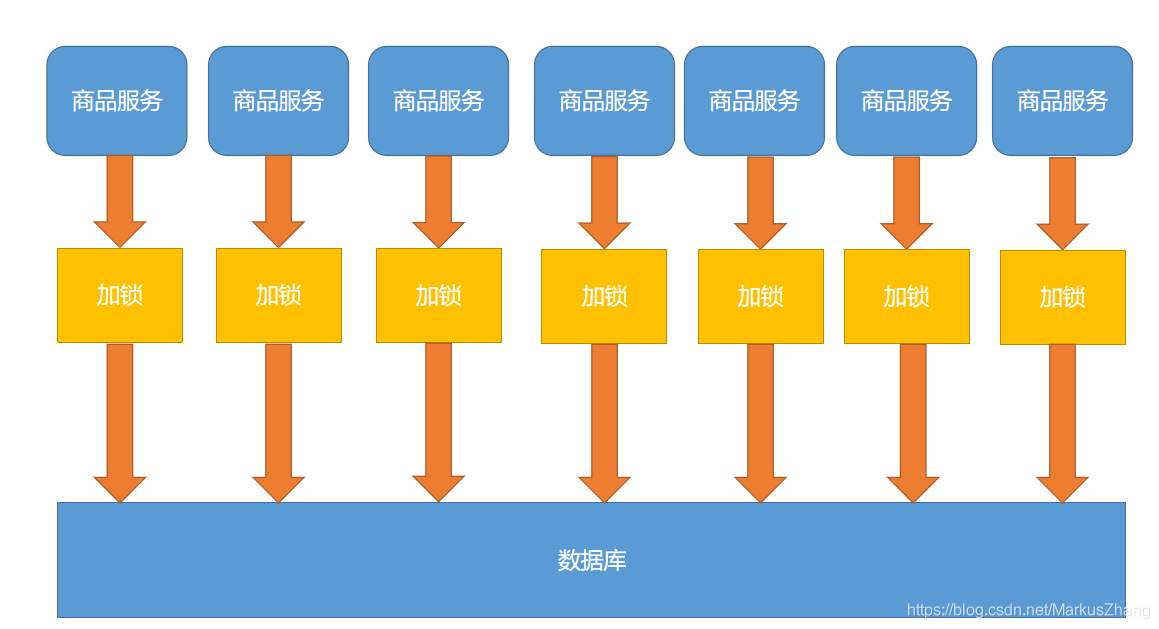
我们的项目是一个分布式集群项目,当然一个服务肯定有很多台服务器,假设我们打过来10万的请求,经过负载均衡打到各台服务器的请求是1万请求,同时判断缓存中没有,那么每台服务器都会将一条请求打到数据库中。如果服务器少的话,也还是ok的,但是对于我们的初衷是不符的,我们只想去数据库中查一次,后来的请求都会被转到redis当中。那么我们可以采用分布式锁来解决!
分布式锁是怎么设计的呢?来画幅图来更好的理解
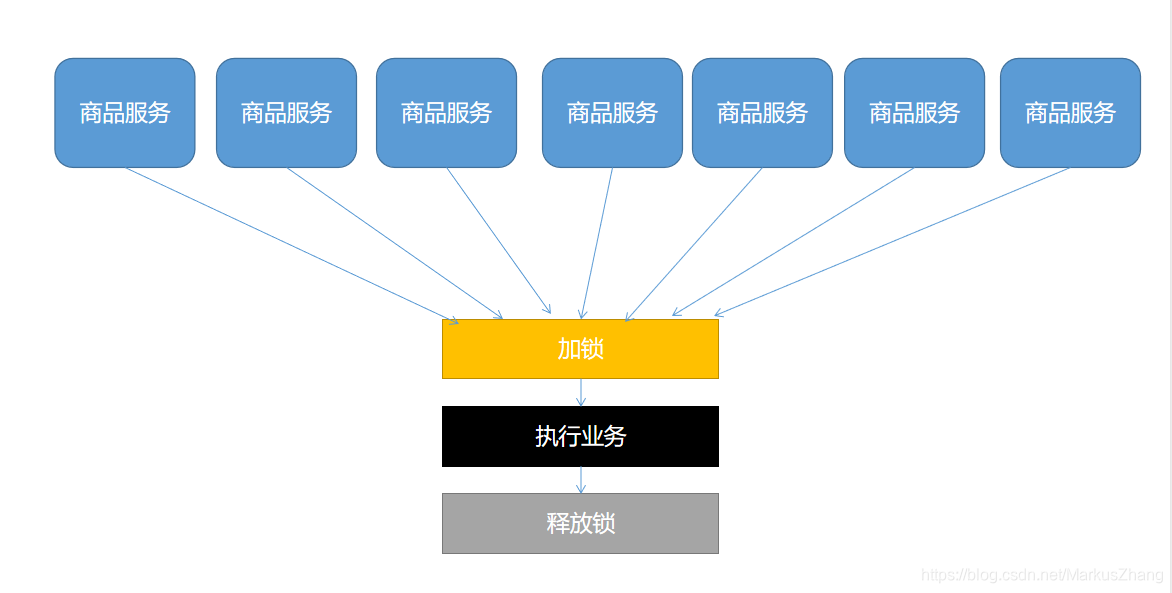
通俗点讲就是:我们可以去同一个地方“占坑”,如果占到,就执行逻辑。否则就必须等待,直到释放锁。占锁可以到redis,也可以到数据库,可以去任何大家都能访问的地方,等待可以采用自旋的方式。
我的方案是去redis中占锁,它是一个天然实现分布式锁的产品,配合它的指令可以实现分布式锁
set key value ex|px nx|xx;
// 我们可以采用这个指令:
set key value ex nx;
// 也就是当这个键不存在的是设置锁
怎么来实现这个分布式锁呢?
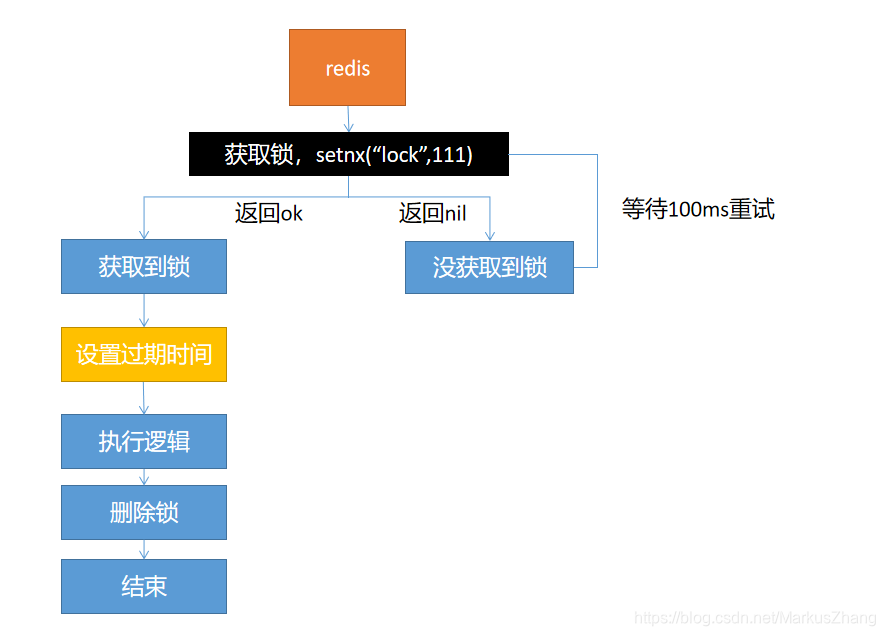
方案一:

这种设计方案,会出现一个问题:当线程获取到锁,然后执行完业务逻辑,准备去删除锁的时候,突然服务器宕机了,会导致这个锁一直存在,得不到释放,会造成死锁的情况。
解决方案就是:设置一个过期时间,即使服务器宕机不能手动释放,也可以过期自动释放
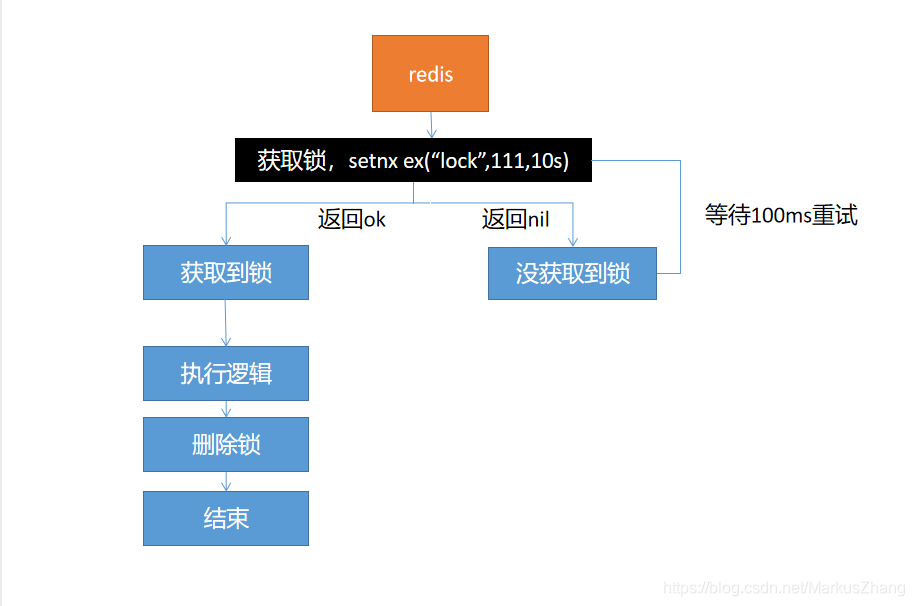
方案二:
解决了方案一的问题,不过,还会有问题,假如当我们获取到锁之后将要去设置过期时间的时候,这时候服务器宕机了,也会造成死锁情况。
解决方案:保证获取锁和设置过期时间是原子性的,setnx ex命令可以保证原子性
方案三:
这种方案解决了设置锁的原子性,但是在删除锁的时候,是应该直接删除的吗?当我们的业务执行时间很长的时候,这时候假定锁已经过期了,别的线程获得了锁,先前线程执行完业务之后,去删除锁,就会去删除别人的锁
解决方案:在设置锁的时候指定自己的UUID,执行完业务后,获取锁检查是否是自己之前设置的,如果是自己设置的,就删除,否则就跳过,在删除锁的时候也要保证原子性,为什么呢?假如我们获取到这个锁的确是我们自己之前设置的,但是在获取值到删除锁中间还是有一段时间,假如这段时间,锁失效了,别人获取到了锁,这时候我们还是会认为锁是自己的,会导致误删。
方案四:
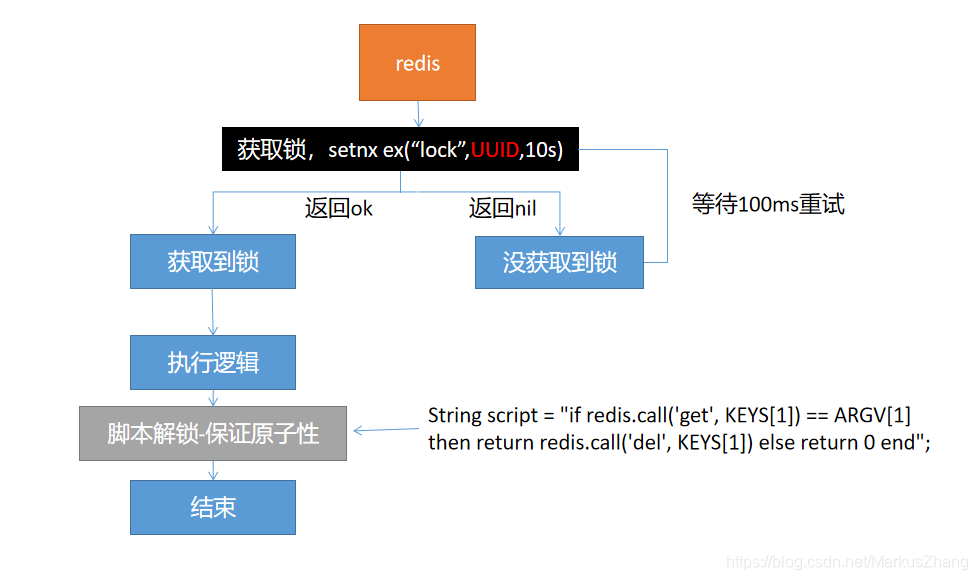
方案四就是终极方案,总之,就是要保证,在获取锁和删除锁的时候都要保证原子性!
接下来又到了一个关键环节:如何解决缓存数据一致性?
有两种方案:
- 双写模式
- 失效模式
来画图分析下双写模式的工作流程:

再来画图分析下失效模式的工作流程:

其实这两种方案都会导致数据不一致性的问题;比如在双写模式下,两个写的请求先后打过来,处理后,在写缓存是由于网络延迟等原因导致后写的请求先写缓存,先写的请求后写入缓存,这就导致了数据不一致性,缓存中的数据不是最新的数据;再比如在失效模式下,看图可知道,当我在第二个写请求还没完成时,我去读缓存,没有读到,然后去数据库中查,当我读到之后假设第二请求还没完成,当第二个请求完成之后,删掉缓存,我再更新到缓存中,也会导致数据不一致性的问题。
针对上面的问题,我们怎么解决呢?
解决方案:
- 如果是用户纬度数据(订单数据、用户数据),这种并发几率非常小的,就不用考虑数据不一致的问题,缓存数据加上过期时间,每隔一段时间触发读主动更新即可
- 如果是菜单、商品介绍等基础数据,也可以采用canal订阅binlog的方式,数据库中信息改变,canal采集这些信息,再做些处理然后同步到redis当中即可
- 缓存数据+过期时间足够解决大部分业务对于缓存的要求
- 如果写入操作稍多的话,我们可以通过加锁的方式去保证并发读写,写写的时候排好队,保证顺序,读的时候不加锁,所以适用读写锁(业务不关心脏数据,允许临时脏数据可忽略)
来个小总结
说了这么多,总结一下吧!
对于我们能够放入缓存的数据就不应该是实时性、数据一致性要求高的。所以缓存数据的时候加上过期时间,保证每天拿到当前最新的数据即可。我们不应该过度的设计,增加系统的复杂性,遇到那些实时性、一致性要求高的数据,就应该去查询数据库,慢点就慢点。