第五周工作进展报告
基于内容感知的视频编解码技术
基于内容感知的视频编解码技术的目的是降低视频传输成本,节省带宽。视频内容特性是指其各个帧图像中的纹理特性和物体或者区域的运动特性。如图1所示,图像的纹理特性与它的内容细节相关,例如:色彩丰富度、物体边界锐利程度,物体形状大小等。如图2所示,物体运动特性与视频内容的变化程度相关,例如:物体运动的快慢,物体运动的方向,前后帧内容变化或者场景切换的剧烈程度等。

图1 图像的纹理特性

图2 物体的运动特性
而目前在内容感知方面有两种比较经典的解决方案,一个是显著性图预测,如图3所示,它是利用人类视觉系统在面对所获取的完整信息中,只将注视焦点放在场景中关键的特定目标上。而显著性图是在图像中找到“引人注目”的内容。我们可以利用显著性图,提取视觉重点,让视频编码器具有编码权重分配的依据。

图3 显著性图
在“基于深度神经网络的图像显著性检测”一文中,作者提出了显著性图预测网络,实验使用到的数据集是开源的显著性检测数据集SALICOM、iSUN,如图4所示,网络分成局部模块和全局模块。全局模块的输入图像是96x96x3的RGB图像,全局模块使用的是3层卷积层做特征提取。局部模块的输入图像是96x96的灰度图,使用预训练的VGG-16模型的前5层卷积层嵌入到CNN网络中,CNN网络中包含了一个STN模块和两个卷积层。网络最后一个模块是获取两种互补信息之间的最佳组合值,包含一个拼接层(concat)、一个激活函数层(maxout)和一个全连接层(FC),最后输出显著性图。
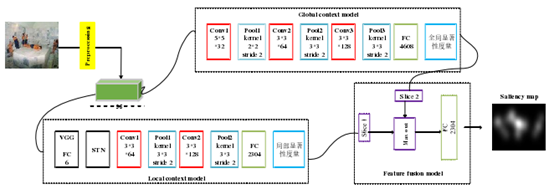
图4 显著性图预测网络模型
而另一种解决内容感知问题的方法是语义分割,语义分割是在像素级别上的分类,属于同一类的像素被归为一类。如图5所示,属于人的像素被分为一类,属于摩托车的像素被分为一类。我们同样可以可利用语义分割,提取视觉重点,让视频编码器具有编码权重分配的依据。

图 5 语义分割
在“Context-aware encoding for clothing parsing”一文中,提出了一个基于彩色时装解析的语义分割模型,主干网络使用的是FCN模型和MobilelNet模型,经过预测、上采样以及一个softmax激活函数,并在网络的边分支建立一个轻量级的COE架构,用于提高特征提取能力和减少过拟合,网络最后输出的是人和彩色时装的语义分割图。
对于视频编解码部分,在“面向动态自适应流视频传输的码率控制算法研究”一文中,提出X264码率控制的三种模式,分别是CBR(constant rate factor):固定码率,输出码率是一个固定值。VBR(variable bit rate):可变比特率,简单部分用低比特率编码,复杂部分用高比特率编码,但输出码流大小不可控。ABR(average bit rate):平均比特率,同样可以动态调整比特率,而且一定时间内,平均码率趋近于目标码率,可以控制输出文件大小。我们可以将上述方法所获得的人眼关注的图像部分结合ABR码率控制算法达到节省带宽的目的。
总结:不足的地方:①缺少视频评判标准②高速运动目标检测(镜头高速运动会出现运动模糊,可适当降低码率③目前找到的方法是基于图像而非视频,针对视频方面的方法还要考虑帧率等因素。