前期准备
第一步:Router软路由构建
第二步:centos7安装 5台(自行安装)
链接:https://pan.baidu.com/s/1WIMdpo1TPYLwwLiu6Bk5-w
提取码:p7go
复制这段内容后打开百度网盘手机App,操作更方便哦

1、安装k8s的节点必须是大于1核心的CPU
2、安装节点的网络信息
master
BOOTPROTO=static
IPADDR=10.0.100.10
NETMASK=255.255.255.0
GATEWAY=10.0.100.8 #指定到koolshare的软路由上
node1
BOOTPROTO=static
IPADDR=10.0.100.11
NETMASK=255.255.255.0
GATEWAY=10.0.100.8
node2
BOOTPROTO=static
IPADDR=10.0.100.12
NETMASK=255.255.255.0
GATEWAY=10.0.100.8
3、koolshare 软路由的默认面是koolshare
集群安装
系统初始化
设置系统主机名以及Host文件
hostnamectl set-hostname k8s-master01
hostnamectl set-hostname k8s-node01
hostnamectl set-hostname k8s-node02
安装依赖包
wget -O /etc/yum.repos.d/CentOS-Base.repo http://mirrors.aliyun.com/repo/Centos-7.repo
yum install -y conntrack ntpdate ntp ipvsadm ipset jq iptables curl sysstat libseccomp wget vim net-tools git
设置防火墙为Iptables并设置空规则
systemctl stop firewalld && systemctl disable firewalld
yum -y install iptables-services && systemctl start iptables && systemctl enable iptables && iptables -F && service iptables save
关闭SELINUX
因为K8s安装的时候会去检测swap分区有无关闭,如果开启了话可能会把pod放在虚拟内存运行,大大降低工作效率。(也可以通过–ingress排除)
swapoff -a && sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab
setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
调整内核参数,对于K8s
必备三调参数:开启bridge网桥模式,关闭ipv6协议
cat > kubernetes.conf << EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.ip_forward=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0 # 禁止使用swap空间,只有当系统OOM时才允许使用它
vm.overcommit_memory=1 # 不检查物理内存是否够用
vm.panic_on_oom=0 # 开启OOM
fs.inotify.max_user_instances=8192
fs.inotify.max_user_watches=1048576
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
EOF
cp kubernetes.conf /etc/sysctl.d/kubernetes.conf
sysctl -p /etc/sysctl.d/kubernetes.conf
报错1:显示/proc/sys/net/bridge/bridge-nf-call-iptables:没有这个文件或者目录
modprobe br_netfilter
报错2:显示sysctl: cannot stat /proc/sys/net/netfilter/nf_conntrack_max: 没有那个文件或目录
modprobe ip_conntrack
调整系统时区
# 设置系统时区为 中国/上海
timedatectl set-timezone Asia/Shanghai
# 将当前的UTC时间写入硬件时钟
timedatectl set-local-rtc 0
# 重启依赖于系统时间的服务
systemctl restart rsyslog
systemctl restart crond
关闭系统不需要的服务
systemctl stop postfix && systemctl disable postfix
设置rsyslogd和systemd journald
让journald控制转发
mkdir /var/log/journal # 持久化保存日志的目录
mkdir /etc/systemd/journald.conf.d # 配置文件存放目录
# 创建配置文件
cat > /etc/systemd/journald.conf.d/99-prophet.conf << EOF
[Journal]
# 持久化保存到磁盘
Storage=persistent
# 压缩历史日志
Compress=yes
SyncIntervalSec=5m
RateLimitInterval=30s
RateLimitBurst=1000
# 最大占用空间 10G
SystemMaxUse=10G
# 单日志文件最大 200M
SystemMaxFileSize=200M
# 日志保存时间2周
MaxRetentionSec=2week
# 不将日志转发到 syslog
ForwardToSyslog=no
EOF
systemctl restart systemd-journald
修改系统内核为4.44
CentOS 7.x系统自带的3.10x内核存在一些Bugs,导致运行的Docker、Kubernetes不稳定。
rpm -Uvh http://mirror.ventraip.net.au/elrepo/elrepo/el7/x86_64/RPMS/elrepo-release-7.0-4.el7.elrepo.noarch.rpm
# 安装完成后检查 /boot/grub2/grub.cfg 中对应内核 menuentry 中是否包含 initrd16 配置,如果没有,再安装一次
yum --enablerepo=elrepo-kernel install -y kernel-lt
# 设置开机从新内核启动
grub2-set-default "CentOS Linux (4.4.182-1.el7.elrepo.x86_64) 7 (Core)"
检测:
[root@k8s-master01 ~]# uname -r
4.4.237-1.el7.elrepo.x86_64
修改DNS
vim /etc/hosts
10.0.100.10 k8s-master01
10.0.100.11 k8s-node01
10.0.100.12 k8s-node02
scp /etc/hosts root@k8s-node01:/etc/hosts
scp /etc/hosts root@k8s-node02:/etc/hosts
kube-proxy开启ipvs的前置条件
kube-proxy主要解决 pod的调度方式,开启这个条件可以增加访问效率
modprobe br_netfilter
cat > /etc/sysconfig/modules/ipvs.modules << EOF
#! /bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
EOF
chmod 755 /etc/sysconfig/modules/ipvs.modules && bash
/etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_contrack_ipv4
安装Docker软件
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum update -y && yum install -y docker-ce
## 创建/etc/docker目录
mkdir /etc/docker
# 配置daemon
cat > /etc/docker/daemon.json << EOF
{
"exec-opts":["native.cgroupdriver=systemd"],
"log-driver":"json-file",
"log-opts":{
"max-size":"100m"
}
}
EOF
# 创建存放docker的配置文件
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
安装Kubeadm(主从配置)
让kubeadm去引导成为k8s
cat <<EOF >/etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
yum -y install kubeadm-1.15.1 kubectl-1.15.1 kubelet-1.15.1
# kubelet是与容器接口进行交互,而k8s通过kubeadm安装以后都是以Pod方式存在,底层是以容器的方式运行。所以一定要开机自启,不然的话启动不了k8s集群
systemctl enable kubelet.service
初始化主节点
kubeadm在初始化k8s集群的时候,会从gce云服务器pull一些所需要的镜像,并且这个镜像是非常大的,而且速度比较慢。
如果有xxr,可通过软路由配置让K8s集群机器
没有xxr,直接拉入Kubeadm-basic.images.tar.gz,拉到k8s集群中,导入即可
vim load-images.sh,因为要导入的镜像太多,直接用脚本。
#!/bin/bash
# 默认会解压到/root/kubeadm-basic.imageswe文件下
tar -zxvf /root/kubeadm-basic.images.tar.gz
ls /root/kubeadm-basic.images > /tmp/image-list.txt
cd /root/kubeadm-basic.images
for i in $( cat /tmp/image-list.txt )
do
docker load -i $i
done
rm -rf /tmp/image-list.txt
接着
# 显示默认init初始化文件打印到 yaml文件中。从而得到默认的初始化模板
kubeadm config print init-defaults > kubeadm-config.yaml
vim kubeadm-config.yaml
修改为(默认的调度方式是ipvs):
advertiseAddress: 10.0.100.10
kubernetesVersion: v1.15.1
添加覆盖:
networking:
dnsDomain: cluster.local
podSubnet: "10.244.0.0/16"
serviceSubnet: 10.96.0.0/12
scheduler: {
}
---
apiVersion: kubeproxy.config.k8s.io/v1alpha1
kind: KubeProxyConfiguration
featureGates:
SupportIPVSProxyMode: true
mode: ipvs
然后
kubeadm init --config=kubeadm-config.yaml | tee kubeadm-init.log


安装完成后,还需要进行如下设置
在当前家目录下创建.kube文件,这里会保存连接配置
kubectl和kubeapi交互,采取HTTPS协议,所以需要些缓存和认证文件都会保存到.kube文件
然后拷贝管理配置文件到.kube目录下
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
查看当前有哪些节点,kubectl get node

为什么是NotReady状态,因为k8s要求有一个扁平化网络存在,还没构建Flannel网络插件,所以还是NotReady
部署网络
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
[root@k8s-master01 ~]# mkdir install-k8s
mv kubeadm-init.log kubeadm-config.yaml install-k8s/
cd install-k8s/
mkdir core
mv * core/
mkdir plugin
cd plugin
mkdir flannel
cd flannel/
wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl create -f kube-flannel.yml
查看组件运行,发现flannel已经在运行
kubectl get pod -n kube-system
发现已经ready了
kubectl get node
原理:kubectl是命令行管理工具,get获取pod状态,-n是指定名称空间为kube-system。因为所有的系统组件都被安装在kube-system
如果不加-n指定,默认是default

加入主节点以及其余工作节点
在其余工作节点 执行主节点的安装日志中的加入命令即可(语句在安装的结尾处)
kubeadm join 10.0.100.10:6443 --token abcdef.0123456789abcdef
–discovery-token-ca-cert-hash sha256:fc19a598cb245d740ed58ca964a7e7e646dd19c773756f86224a966eecb6038e

kubectl get node 查看

Harbor采取私有的仓库去镜像使用
Centos7系统,然后安装Docker,跟上面安装docker一样
安装docker
yum install -y yum-utils device-mapper-persistent-data lvm2
yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum update -y && yum install -y docker-ce
## 创建/etc/docker目录
mkdir /etc/docker
# 配置daemon
cat > /etc/docker/daemon.json << EOF
{
"exec-opts":["native.cgroupdriver=systemd"],
"log-driver":"json-file",
"log-opts":{
"max-size":"100m"
}
}
EOF
# 创建存放docker的配置文件
mkdir -p /etc/systemd/system/docker.service.d
# 重启docker服务
systemctl daemon-reload && systemctl restart docker && systemctl enable docker
vim /etc/docker/daemon.json
为了让k8s集群信任这个自己制作的证书
每个节点,包括harbor都需要加这么一句话
"insecure-registries": ["https://hub.atguigu.com"]
systemctl restart docker

拉入docker-compose到harbor
mv docker-compose /usr/local/bin/
chmod a+x /usr/local/bin/docker-compose
拉入harbor安装包
tar -zxvf harbor-offline-installer-v1.2.0.tgz
mv harbor /usr/local/
cd /usr/local/harbor/
vim harbor.cfg
修改:
hostname = hub.atguigu.com
ui_url_protocol = https
创建https证书以及配置相关目录
创建https证书的目录,在harbor.cfg对应
mkdir -p /data/cert
cd /data/cert
# 创建私钥密码
openssl genrsa -des3 -out server.key 2048
# ssl请求
# 国家名 CN
# 省 GD
# 组织 atguigu
# 域名 hub.atguigu.com
# Common Name (eg, your name or your server's hostname) []:hub.atguigu.com
openssl req -new -key server.key -out server.csr
# 备份私钥
cp server.key server.key.org
# 转换成证书,让私钥的密码退掉,因为docker启动时私钥的证书有密码,会启动不成功
openssl rsa -in server.key.org -out server.key
# 证书签名
openssl x509 -req -days 365 -in server.csr -signkey server.key -out server.crt
# 证书赋予权限
chmod -R 777 /data/cert

运行install脚本
每个节点
echo "10.0.100.13 hub.atguigu.com" >> /etc/hosts
harbor目录下 ./install.sh

(1)联网问题,修改主机名为 hub.atguigu.com
ERROR: for harbor-ui UnixHTTPConnectionPool(host='localhost', port=None): Read timed out. (read timeout=70)
ERROR: for ui UnixHTTPConnectionPool(host='localhost', port=None): Read timed out. (read timeout=70)
ERROR: An HTTP request took too long to complete. Retry with --verbose to obtain debug information.
If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60).
解决:hostnamectl set-hostname hub.atguigu.com
直接把之前的容器和镜像都删除干净,重新执行install.sh
(2)has active endpoints
ERROR: error while removing network: network harbor_harbor id 91ec97d7a1f661e4d687b7d69c3060144de77df113f0205590f07fb39843f44b has active endpoints
解决
docker network inspect harbor_harbor
//断开网络,这里有两个Name参数 ,分别是上面标记的参数一和参数二
docker network disconnect -f harbor_harbor harbor-ui
//然后执行
docker-compose up -d
再次执行install.sh
(3)Timed out
ERROR: for jobservice UnixHTTPConnectionPool(host='localhost', port=None): Read timed out. (read timeout=60)
ERROR: An HTTP request took too long to complete. Retry with --verbose to obtain debug information.
If you encounter this issue regularly because of slow network conditions, consider setting COMPOSE_HTTP_TIMEOUT to a higher value (current value: 60).
解决
解决思路:把 COMPOSE_HTTP_TIMEOUT 的值调大,并转为环境变量即可。
解决步骤:
先进入/etc/profile配置文件,执行命令:
vi /etc/profile
然后在尾部添加上下面代码:
export COMPOSE_HTTP_TIMEOUT=500
export DOCKER_CLIENT_TIMEOUT=500
接着使/etc/profile配置文件生效,执行命令:
source /etc/profile
最后重新执行命令 docker-compose up 即可。
(4)容器重新建
ERROR: for 30a708d1ccb1_harbor-ui b'You cannot remove a running container 30a708d1ccb166cb63885c4aa66e73a4b1c0e5b815185d990eb5190e16463da7. Stop the container before attempting removal or force remove'
ERROR: for ui b'You cannot remove a running container 30a708d1ccb166cb63885c4aa66e73a4b1c0e5b815185d990eb5190e16463da7. Stop the container before attempting removal or force remove'
ERROR: Encountered errors while bringing up the project.
解决
删除不掉容器文件占用,其实是网络问题。
解决办法如下
1、docker stop 容器ID\容器名 先暂停
2、docker network disconnect --force bridge 容器ID\容器名 清除网络
3、docker rm -f 容器ID\容器名 再强制删除
最终成功,各种报错,一步步终于好了!!!


W10真实主机
C:\Windows\System32\drivers\etc\hosts
10.0.100.13 hub.atguigu.com
浏览器访问 hub.atguigu.com
在/usr/local/harbor/harbor.cfg文件中
默认用户名 admin
默认密码 Harbor12345

集群检测
检测k8s是否能利用到harbor仓库,那在k8s利用之前,docker要能先利用到
1、node01上检测docker
出现报错可能是因为json格式
检查 /etc/docker/daemon.json是不是如下格式
{
"exec-opts":["native.cgroupdriver=systemd"],
"log-driver":"json-file",
"log-opts":{
"max-size":"100m"
},
"insecure-registries": ["https://hub.atguigu.com"]
}
然后重启一下docker:
systemctl daemon-reload
systemctl restart docker
docker login https://hub.atguigu.com
docker pull wangyanglinux/myapp:v1 在公共docker hub拉取
重新打标签,因为推送镜像必须要命名成hub.atguigu.com
docker tag wangyanglinux/myapp:v1 hub.atguigu.com/library/myapp:v1
docker push hub.atguigu.com/library/myapp:v1
刷新查看镜像情况
docker images
然后删除镜像,为了后面验证k8s集群是否可下载
docker rmi -f hub.atguigu.com/library/myapp:v1
docker rmi -f wangyanglinux/myapp:v1
重新打标签,因为推送镜像必须要命名成hub.atguigu.com

完整过程

2、测试k8s集群是否可用,与镜像仓库连接情况
在k8s启动pod看是否OK

k8s-master01执行:
暴露端口80和docker的80是不一样的,不写也可以访问的,因为是扁平化网络
kubectl run nginx-deployment --image=hub.atguigu.com/library/myapp:v1 --port=80 --replicas=1
kubectl get deployment
kubectl get rs
kubectl get pod
kubectl get pod -o wide

然后到node01查看是否有nginx的
docker ps -a | grep nginx
只要运行一个pod就会有pause

如果master想访问node01的话,直接curl IP,因为是扁平化网络
curl 10.244.2.2
curl 10.244.2.2/hostname.html 获取pod名称

这样一来私有仓库连接成功。减轻外网网络资源压力
3、harbor仓库查看,镜像下载次数1

集群功能演示
kubectl get pod 获取pod
kubectl delete pod Name 删除pod
kubectl get pod 获取pod,发觉又多了一个,和之前名字不一样

因为在之前kubectl run的时候已经指明了副本replicas=1,会保持为1
如果有一天压力过大,可不可以扩容?
kubectl get pod
kubectl scale --replicas=3 deployment/nginx-deployment
kubectl get pod
kubectl get pod -o wide


nginx负载访问,通过SVC
kubectl expose --help
kubectl expose deployment nginx-deployment --port=30000 --target-port=80
访问服务端的30000端口, 访问的是容器的80端口
kubectl get svc

curl访问测试,是一个轮询的机制

ipvsadm -Ln | grep 10.105.236.174

kubectl get pod -pod -o wide

发现SVC机制就是调度LVS模块实现负载均衡,这个是内部地址。
如果外部想访问怎么办?修改类型
kubectl get svc
kubectl edit svc nginx-deployment
type: NodePort
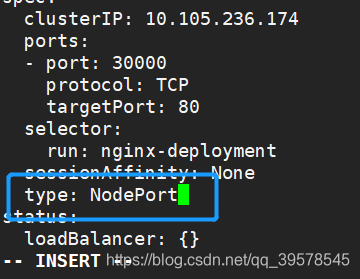
kubectl get svc

netstat -anpt | grep 30000
netstat -anpt | grep 32651
在所有的节点都暴露这么一个端口,然后浏览器直接访问32651端口即可

10.0.100.10:32651
10.0.100.11:32651
10.0.100.12:32651
这样一来,改成NodePort类型,就可以在web访问到k8s内部的服务。

终于大功告成!!!!!!!!!!