紧接上一篇文章
1、创建NodeClient对象
将截止到目前为止涉及到的所有对象的配置文件收集起来,又是以list集合的方式,
final List<Setting<?>> additionalSettings = new ArrayList<>();然后作为参数创建了一个NodeClient对象。如果Node是节点的静态表现方式,那NodeClient就是节点的动态表示方式,将会执行各种action。action是什么呢,我们到相应的场景再说,在这里可以简单理解为查询、新增文档等动作
2、解析Plugin
Plugin是es中放给开发者进行自定义功能的扩展点,我们从磁盘上将plugin文件目录读取后,现在需要将里面为ScriptPlugin类型的插件抽取出来进行操作。
不知道你对es的api操作了解多少,是否使用过es的脚本,例如下面的api,查询到的结果进行删除
jiaowu_school/_delete_by_query
{
"query": {
"match_all": {}
}
}又或者将查询到的结果进行update
这是我日常开发中经常使用的2个api,这2个api对应的就是这里的Script关键词
在脚本模块里会有上下文context的概念,可以简单理解为做操作之前掌握的一些信息。
关于脚本的介绍说细的化可以单独开一篇文章进行介绍了,由于这里是在阐述启动,不能喧宾夺主的过分介绍。
解析完后放入内存
public final Map<String, ScriptEngine> engines;
public final Map<String, ScriptContext<?>> contexts;接下来是分析插件AnalysisPlugin
和分词器相关,比如如何切分,如何过滤相关的就是在这一步进行了注册
接下来是将Settings也封装成模块,这里包含集群内置的一些参数等,都封装成了SettingsModule对象
public SettingsModule(
Settings settings,
List<Setting<?>> additionalSettings,
List<String> settingsFilter,
Set<SettingUpgrader<?>> settingUpgraders) {
this(
settings,
additionalSettings,
settingsFilter,
settingUpgraders,
ClusterSettings.BUILT_IN_CLUSTER_SETTINGS,
IndexScopedSettings.BUILT_IN_INDEX_SETTINGS);
}NetworkService也被创建了,在创建过程中会根据setting判断用户是否自己定义了主机地址的获取方式等。默认情况下肯定是没有实现接口自己定义
接下来是找出插件中和集群管理行为相关的插件,这些插件都实现了ClusterPlugin接口。
默认有4个

截止到现在具备了集群的配置、集群的名字、线程池,就可以封装一个针对集群管理的ClusterService对象了,集群的状态变更它要知道,还要添加监听器对集群的event进行监听,比如当本地节点变成主节点,或者不再是主节点
而对于集群运行期间的一些信息的统计也封装了ClusterInfoService对象,但主要是一些静态的结果。
es作为框架,对一些信息要进行监控,特意封装了监控服务,那主要是监控哪些资源呢?
public MonitorService(Settings settings, NodeEnvironment nodeEnvironment, ThreadPool threadPool) throws IOException {
this.jvmGcMonitorService = new JvmGcMonitorService(settings, threadPool);
this.osService = new OsService(settings);
this.processService = new ProcessService(settings);
this.jvmService = new JvmService(settings);
this.fsService = new FsService(settings, nodeEnvironment);
}jvm 垃圾回收的情况,操作系统的基础项,进程信息,jvm信息,文件系统的信息
都是按1s位单位进行采集
3、重要module解析
接下来封装了一个ClusterModule,和集群相关的配置和service都在这里处理,影响的是整个集群。也就是说上文中的ClusterInfoService也是ClusterModule的一部分。而且看出上文的很多对象的创建都是为了ClusterModule做准备工作。
在构建该对象时,除了使用上文已经创建好的对象,这一环境还会创建一些系统内置的decider集合,是将各种不同的AllocationDecider的都汇聚在一起,目前还不知道allocate什么,但是这些AllocationDecider可以理解为各自场景下的一些规则,只有符合了这些规则才可以重新分配。接着是创建了分片的allocate,最终将decider集合和分片的allocate统一成AllocationService进行管理。
接下来就是索引模块IndicesModule的解析。
我们和索引打交道,肯定要处理mapping的相关问题,而在创建IndicesModule时首要的也是获取内置mappers,目前是25种

要求从磁盘加载的MapperPlugin 不能和这25个已有的重复,并且也放入最终的mappers.
元数据mapper指的是什么呢?如图
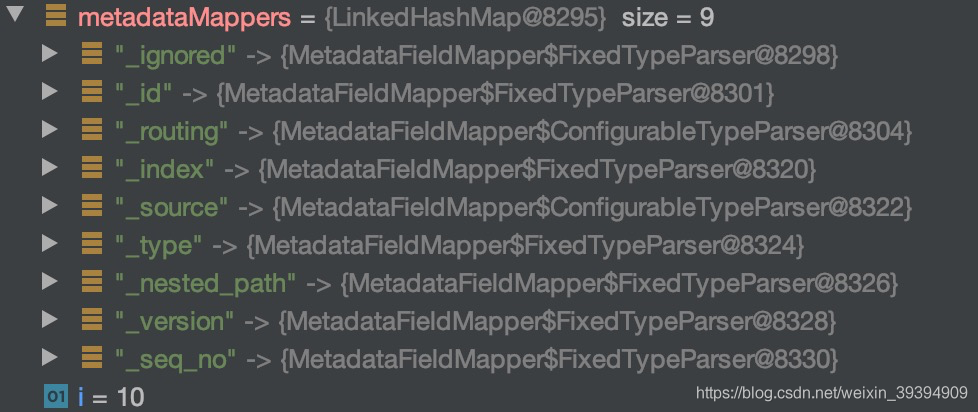
这2个mapper就是索引模块最重要的内容了