Web of Science科普
在介绍如何检索之前,先做一个简单的科普(为了通俗易懂,并不严谨,读完之后你能知道这些大概是个什么事,这样完全足够了)。不看科普直接跳到下一节即可。
作为理工科的各位,肯定听说过“发一篇SCI,发一篇EI”之类的话。
这个世界上有很多科研工作者,大家都会把自己的科研进展共享与大家分享,主要有两种方式 1.大家坐下来聊聊天[会议];2.写成作文儿[期刊]。 也就是大家常说的投会议、投期刊。
会议会有会议文集,来开会的各位都说了些什么,做一下记录。这个记录就是你向会议发出的投稿。投期刊就不用多讲了,你要写一篇作文儿,跪求出版在某一本书上。
这个世界上有很多学科,无数的研究方向,他们都有各自领域的期刊。当你也想加入进来做研究时,如何查询大家都进展到什么地步了呢?找一本期刊看看目录,按时间顺序博览古今,都是方法。1950年有一个老头儿提出了一种高效的方法引文索引(Citation Index, CI)。
大家写作文儿的时候都会在最后附上我抄的借鉴的谁的文章,在此基础上我有编了创新了哪些内容。因此所有的文章之间可以分为四种关系:
- A借鉴了B(citing)
- B被A借鉴(cited)
- AB说的事情差不多,但是互相没借鉴(Relavant)
- AB说的事完全没关系
通过这四种关系就能从你找到的任意一篇文献快速的了解清楚这个方向的研究情况。
于是老爷子建立了著名的自然科学、社会科学、艺术和人文领域三大索引数据库:
- SCI(Science Citation Index)
- SSCI(Social Citation Index)
- A&HCI(Arts & Humanities Citation Index)
其中我们理工科熟悉的就是SCI了。SCI这个数据库不记录具体的文章内容,他记录这篇文章的关系网络,以及各种对这篇文章的“社会地位”的分析。而Web of Science就是所有此类数据库的一个Web汇总版(在互联网不发达的年代,所谓SCI数据库就是就是一本非常厚重的,可以在图书馆借到的书。那时候想要用它查文献,就要去图书馆翻阅,记下你找到的论文关系网中论文的题目,再拿着这些题目去找论文原文来阅读)。
Web of Science的界面很干净。可以看到Web of Science是Clarivate(科睿唯安)公司的产品,上边栏与Web of Science并列的其他栏目全部都是这个公司的其他产品(或许你熟悉其中的EndNote论文管理软件)。

除了SCI等数据库外,Web of Science还收录其他各个国家的各种数据库。SCI、SSCI、A&HCI数据库属于Web of Science核心合集中(毕竟这些数据库白手起家时的顶梁柱,称其为核心合集一点也不过分)。
科普到此结束~
Web of Science检索教程
首先我都会将数据库选择为Web of Science核心合集因为所有数据库中还包含中国、韩国、俄国等国家的引文索引数据库,追求高质量文章的研究僧们肯定要求精了呀,即便这样,也是海量的论文…我是理工科,我想只检索SCI数据库,也可以在下面的更多设置中只选择SCI数据库(可以选,但是没必要,毕竟理工科的文章不会被社会科学的数据库收录,要真收了,那还真有必要看看他的跨学科思想)~
以下对常用的、能够满足科研需求的检索方式做一下讲解(Web of Science有很多专业且花里胡哨的功能,一般我们是用不到的。我只讲我觉得实用的,日后某些功能我亲测过好用后会及时补充哒)。完整教程可以到Web of Science官网上查询,本文的目的是从繁复的教程中精简出最实用的那些。

基本检索
无用字段
引文索引数据库中对一篇文献的记录是通过各种字段完成的,即记录一篇文献就是记录了它的:标题、摘要、关键字、作者、编者、机构作者、团体作者、出版年、地址、入藏号等等一堆东西。 在搜索时你可以指定要搜索什么,比如搜索团体作者字段,检索结果就是包含这条信息的所有文献。
基本检索中一般只检索主题,为了内容完整性,其他基本不用的只做一下介绍。可以跳过不看。
- PubMed ID
有一个称为MEDLINE的医学数据库,PublicMed ID就是这个数据库中每条记录的ID,比如检索148474*就能检索到所有以这个ID开头的所有MEDLINE记录。 - 团体作者
一篇文献的著作权属于某个团体或者机构,那么这个团体或机构就是这天文献的团体作者。很好理解,你是研究原子弹的,你有了研究进展,发了一篇论文,你敢说这个你的成果么?那肯定是团体的国家的呀。 - DOI
数字对象标识符(DOI)是电子文档的“二维码”,其实是一串字符串,用于唯一标识电子文档用的。就像书籍都有一个标识号称为ISBN,期刊也都有他的标识号称为ISSN。 - 会议
这个会议是你要检索的字段,当你选中它之后,你应该在搜索框中输入会议标题、地点、日期、赞助方,这些内容来做检索,检索到的内容还是被数据库收录的文章信息。如搜索(India AND 2000),第一条结果是:

- ORCID
由于科研工作者的名字五花八门,所以每位科研工作者都可以申请一个名片,这张名片上会记录你所有发表的科研工作,以及你的一些个人信息。当然,还有这个用来代替姓名的ORCID,但是并不是所有作者都用这东西。
其它的就不再列举了,总之,没用。比如我就想找个富婆包养我,我就筛选“财富”“颜值”“户籍”等我关心字段就好了,为什么要了解“快乐球数量”字段是什么意思呢?
“主题”字段
主题字段包含:标题、摘要、关键字、Keywords Plus(作者自己没写,但是被添加的相关关键词)。这些字段就已经能够清晰的描述一篇论文的重要信息了。
当然,如果你要查某个作者,那要选择作者字段,在主题字段下查人名是什么都查不到的
PS:总有刁民问,老师让我调研,我怎么查了个寂寞?
那是因为你把参考文献直接复制过来,还在主题字段下搜索,比如:
Sebastian Kleis, Joachim Steinmayer, Rainer H. Derksen, and Christian G. Schaeffer, “Experimental investigation of heterodyne quantum key distribution in the S-band or L-band embedded in a commercial C-band DWDM system,” Opt. Express 27, 16540-16549 (2019)
这里面既有作者,还有期刊,还有编号,年份,再加一个被引号引起来作为整个词的标题。在主题字段下怎么能查得到东西呢?主题字段只会匹配“标题、摘要、关键字、Keywords Plus”这四项呀。你会把你自己的名字作为关键词写进论文嘛~
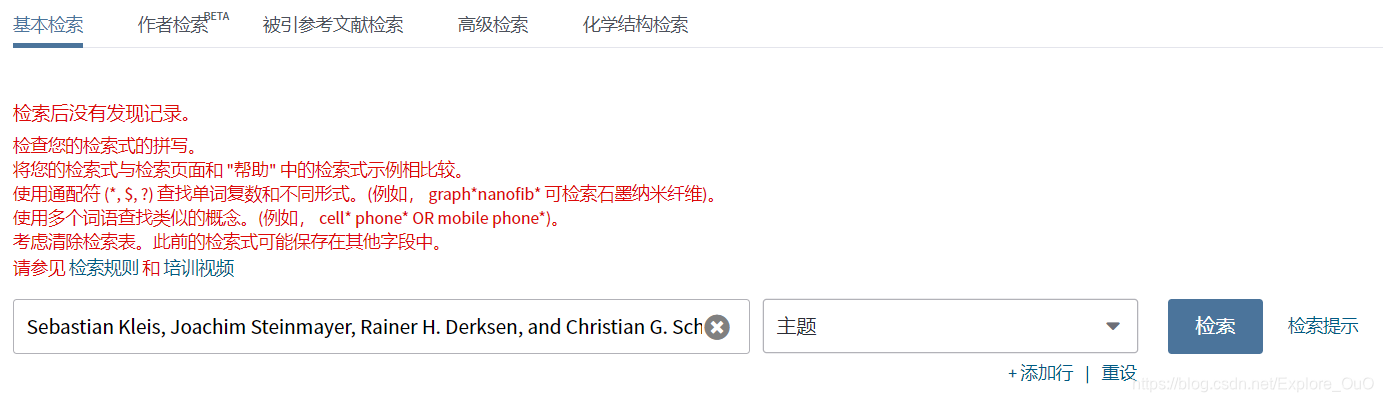
结果就变成了这样。
无论是论文数据库,还是浏览器搜东西,规则都是差不太多的。我见过很多人在百度上这样搜索:2020年最可爱的日本哔哔哔哔都有谁? 还不忘加上问号。
你是问百度问题吗?它是一堆代码而已,没有思想,怎么能回答你问题呢?这些都是一个文字匹配的过程,你需要查询关键词。正确的搜索方式应该是:2020 空格 可爱 空格 日本 空格 哔哔 空格 排行。数据库也是如此~
“作者”字段
与上一节相同,只需要把检索字段换成作者即可。Web of Science在检索作者名字时,要求输入[姓氏+空格+名字首字母],如:检索作者Alessio Ferrari,需输入Ferrari A。(不同的检索平台对姓名检索的要求不同,要因地制宜。最重要的还是要分清哪个是姓,哪个是名。反正我是来回试一下,我分不出来…)
此外为了检索更流畅,我们需要学习一点检索表达式~
检索表达式&规则
- 检索运算符 and or not near/x same
near/x和same运算符可以忽略,不常用。
检索运算符不区分大小写,AnD、and、AND都是一样的。当搜索两个关键词时,空格默认为and。也就是为什么你输入一篇论文的标题却能搜到很多文献的愿意。如果你想只搜到这一篇,需要给它加上引号,才会将整个题目视作一个单词。
运算符的优先级不用记,加括号就完事了 near/x>same>not>and>or - 通配符 * $ ?
$用来代替一个字符或什么都不做。如:检索flavo$r,可以检索到flavor和flavour,对于同一个单词的英美拼写差异非常有用。
?用来代替一个字符,它与$的差异就在于,不可以占坑不办事。如:检索Barthold?,可以检索到Bartholdi和Bartholdy等等。对于最后一个字符不确定的作者姓氏非常有用。(但是对我这种口语=0的英语渣渣,没啥用) - 检索之神:“*”。
*可以代替任意长度的任意字符,但是使用*前至少要有三个字符,如:zeo*是合法的,ze*是不合法的。同理后面也是一样至少有三个字符,如*bio
PS:星号的检索规则还有很多,只是因为程序员要把所有情况都考虑到,实际使用起来,那些规则基本用不上。记得*通配符只在检索主题字段的时候使用即可。 作者字段可以用吗?你想想你真的会用吗?还不是在一篇论文上看到谁的名字直接复制过来搜,怎么会用得到通配符,虽然有规则,但是没必要知道~ - 进阶规则:词形还原+词干提取
词形还原是默认开启的,当你检索某个单词时,会自动检索相应的词根,以此避免词形变化带来的工作量。如:检索communicate

很多时候你会碰到检索出来的文章,并没有标黄的匹配词,为什么会检索到它呢?就是因为词形还原功能。上图右侧可以看到我检索的字段时标题,检索词为communicate。第二条结果中,有同根词communicating,同理,那些标题中含有communication的论文也会被检索到。
PS:当你的检索词太简单时,检索结果非常多,只会显示部分结果,所以要想好检索词,不然1W个结果,你要手动筛选么?
词干提取是类似的功能,也是自动打开的。当使用“”将单词或词组限定后,以及使用了通配符后,这两个功能就自动关闭了。
被引文献检索
这个功能非常实用,当你看到一篇经典论文的时候,想要查看他的后续发展情况,最快捷的方法就是查看有哪些文献引用了这篇论文。如果你想看这篇文章的前人贡献只需要查看这篇文献下给出的参考文献就可以了。而后续发展,就需要使用这个检索功能了!
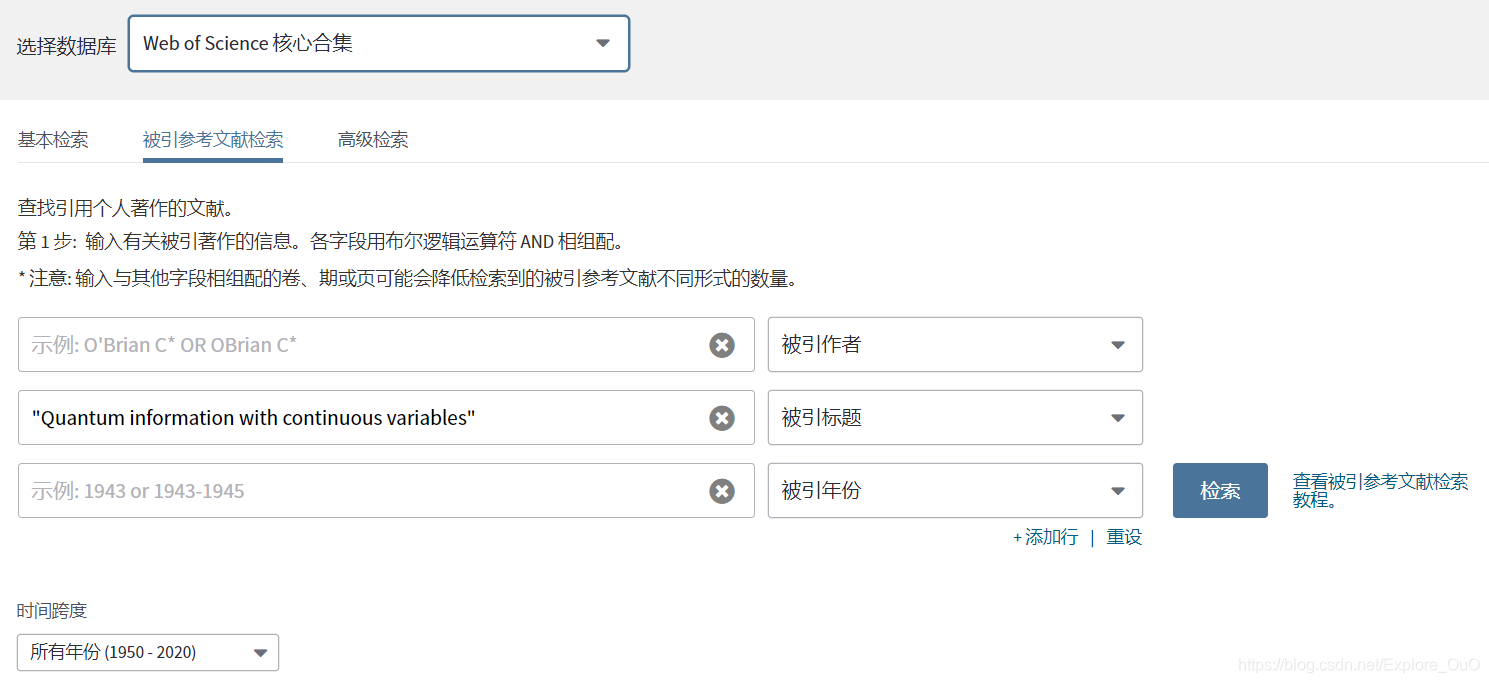
我选择了一篇被引次数高达2000的文章举例。第一步,你要确定查看那篇文献的后续发展,上图就是第一步的检索。检索到你预期的文献后,选中它点击完成检索。

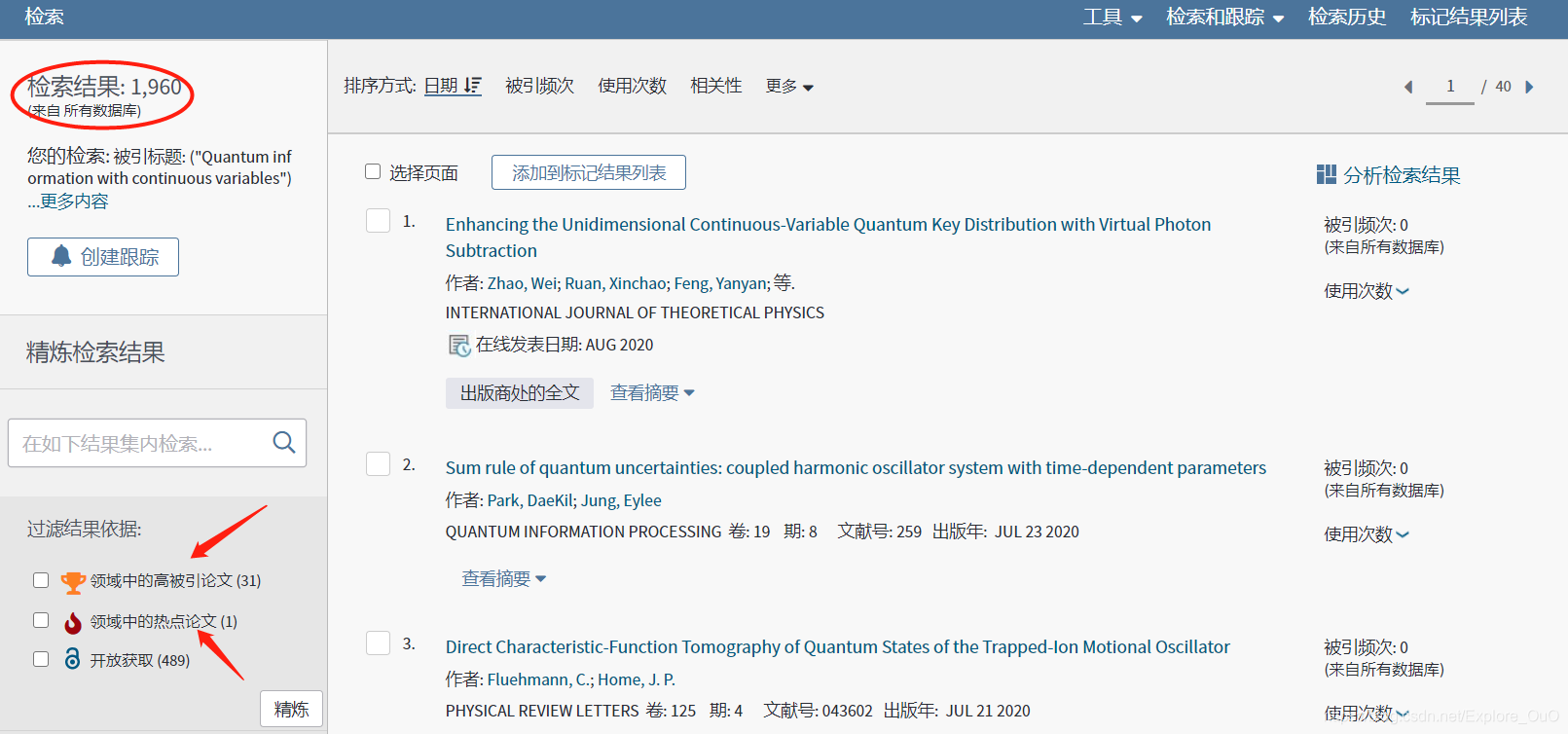
于是你就找到了引用这篇文章的1960篇文章。你不可能都看一遍的。所以使用下方的高被引论文、热点论文进一步筛选。这下就只剩下30篇了,已经到了可以阅读的程度了。如此一来,你就能在短期内完成一个研究方向的大概了解喽~。
高级检索
由于基本检索中已经可以达到高级检索的效果了,为啥还要记高级检索的公式呢,反正我是懒,可以记,但是没必要。如下图所示:
分析检索结果
Web of Science还有一个非常实用的功能那就是分析检索结果。直接上图吧(有一些细节问题没有全部展开,再有疑问,百度一下呗)



通过对检索结果的分析,锁定相关课题研究内容的核心期刊/核心会议,对这些期刊/会议的持续关注,你就能一直走在学科发展的前沿。以此也了解到了该领域的大牛和科研机构,都可以作为你晋升道路的不二选择。
后记
Web of Science是一个非常有用的科研工具,我只介绍了其冰山一角,但是都是最实用的那些。做科研不要本末倒置,把精力花在学习工具使用上。这些方法、技巧,都是应该在论文查询和解决需求的过程中去慢慢掌握的,不要着急~
本文对Web of Science的介绍,足够应付大家的科研需求了。
各位,回见~