1.前言
从模拟登录这件事上,可以看出公司之间的技术水平,对安全的重视程度。之前做过豆瓣的模拟登录(链接),直接做一个post请求就OK,简直easy. 但是到新浪微博上,这个方法完全行不通,新浪微博简直了!!!各种加密,各种跳转,登录过程神烦!!!在参考了很多的博文,历经无数次失败之后,终于,我也成功登录上了!(●'◡'●)
2.登录过程分析
我一直用的是chrome浏览器,所以在开始做模拟登录的时候也是用chrome看登录过程,但是!并没有获得很多有用的信息,之后看网上很多推荐fiddler抓包,但是看着太乱了,也并没有真正去分析这个软件. 之后我转向了火狐,奇迹发现了,我看到了登录的全过程,网页的响应也很容易查看(chrome响应看不到的情况下也可以).因此,复杂的登录分析还是用火狐吧!
好,接下来就是见证奇迹的时刻,来看看登录到底经历了哪些过程:
首先,在输入用户名后,会进行预登录,网址为:http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=ZW5nbGFuZHNldSU0MDE2My5jb20%3D&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.18)&_=1443156845536,通过响应(sinaSSOController.preloginCallBack({"retcode":0,"servertime":1443156842,"pcid":"gz-e88b75a929252baec7c12c741985eaa45627","nonce":"2L4IZ3","pubkey":"EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC253062882729293E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443","rsakv":"1330428213","showpin":0,"exectime":16})),我们可以获得四个有用的变量,servertime、nonce、pubkey和rsakv.
新浪微博的用户名加密目前采用Base64加密算法,而新浪微博登录密码的加密算法使用RSA2,这是模拟登陆的重点,需要先创建一个rsa公钥,公钥的两个参数新浪微博都给了固定值,第一个参数是登录第一步中的pubkey,第二个参数是js加密文件中的‘10001’(针对网友的提问进行更新:这个其实就是在ssologin.js的响应中). 这两个值需要先从16进制转换成10进制,把10001转成十进制为65537,随后加入servertime和nonce再次加密.
在做完准备工作之后,可以看看登录需要什么数据,切换到post请求,网址为:http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18),查看提交的表单数据,如下图:
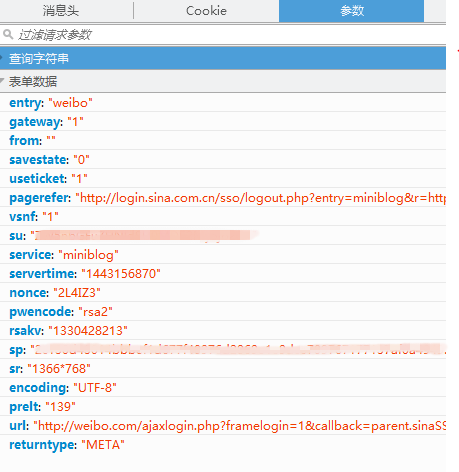
主要的需要提交数据:
su:base64加密过后的用户名
servertime/nonce/rsakv之前预登陆获取到了
sp是加密过户的密码
表单数据获取到了之后自然就是提交表单数据,你以为这样就好了吗?太naive了!
提交之后返回的并不是微博个人主页,而是一段重定向的代码,大概是这样:
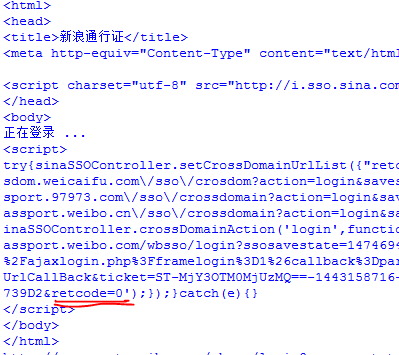
注意红线部分,如果是retcode=0则表示成功,否则前面的过程就有问题哦==
通过正则表达式获取到重定向的网址,提交请求之后就大功告成啦!
3.技术要点
3.1 几个库
cookielib:The cookie module defines classes for abstracting the concept ofcookies, an HTTP state management mechanism. It supports both simple string-onlycookies, and provides an abstraction for having any serializable data-type ascookie value. 用来保存cookies.
urllib2:The urllib2 module defines functions and classes which help in openingURLs (mostly HTTP) in a complex world — basic and digest authentication,redirections, cookies and more. 用来发送请求获取网页数据,与cookielib配合可以利用cookie访问.
json:Json is a lightweight data interchange format inspired by javascript object literal syntax(although it is not a strict subset of JavaScript ).
3.2 正则表达式
正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大.
具体可以参考:Python正则表达式指南
4.源代码
# -*- coding: utf-8 -*-
########################
#author:Andrewseu
#date:2015/9/23
#login weibo
########################
import sys
import urllib
import urllib2
import cookielib
import base64
import re
import json
import rsa
import binascii
#import requests
#from bs4 import BeautifulSoup
#新浪微博的模拟登陆
class weiboLogin:
def enableCookies(self):
#获取一个保存cookies的对象
cj = cookielib.CookieJar()
#将一个保存cookies对象和一个HTTP的cookie的处理器绑定
cookie_support = urllib2.HTTPCookieProcessor(cj)
#创建一个opener,设置一个handler用于处理http的url打开
opener = urllib2.build_opener(cookie_support, urllib2.HTTPHandler)
#安装opener,此后调用urlopen()时会使用安装过的opener对象
urllib2.install_opener(opener)
#预登陆获得 servertime, nonce, pubkey, rsakv
def getServerData(self):
url = 'http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su=ZW5nbGFuZHNldSU0MDE2My5jb20%3D&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.18)&_=1442991685270'
data = urllib2.urlopen(url).read()
p = re.compile('\((.*)\)')
try:
json_data = p.search(data).group(1)
data = json.loads(json_data)
servertime = str(data['servertime'])
nonce = data['nonce']
pubkey = data['pubkey']
rsakv = data['rsakv']
return servertime, nonce, pubkey, rsakv
except:
print 'Get severtime error!'
return None
#获取加密的密码
def getPassword(self, password, servertime, nonce, pubkey):
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password) #拼接明文js加密文件中得到
passwd = rsa.encrypt(message, key) #加密
passwd = binascii.b2a_hex(passwd) #将加密信息转换为16进制。
return passwd
#获取加密的用户名
def getUsername(self, username):
username_ = urllib.quote(username)
username = base64.encodestring(username_)[:-1]
return username
#获取需要提交的表单数据
def getFormData(self,userName,password,servertime,nonce,pubkey,rsakv):
userName = self.getUsername(userName)
psw = self.getPassword(password,servertime,nonce,pubkey)
form_data = {
'entry':'weibo',
'gateway':'1',
'from':'',
'savestate':'7',
'useticket':'1',
'pagerefer':'http://weibo.com/p/1005052679342531/home?from=page_100505&mod=TAB&pids=plc_main',
'vsnf':'1',
'su':userName,
'service':'miniblog',
'servertime':servertime,
'nonce':nonce,
'pwencode':'rsa2',
'rsakv':rsakv,
'sp':psw,
'sr':'1366*768',
'encoding':'UTF-8',
'prelt':'115',
'url':'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
'returntype':'META'
}
formData = urllib.urlencode(form_data)
return formData
#登陆函数
def login(self,username,psw):
self.enableCookies()
url = 'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)'
servertime,nonce,pubkey,rsakv = self.getServerData()
formData = self.getFormData(username,psw,servertime,nonce,pubkey,rsakv)
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0'}
req = urllib2.Request(
url = url,
data = formData,
headers = headers
)
result = urllib2.urlopen(req)
text = result.read()
print text
#还没完!!!这边有一个重定位网址,包含在脚本中,获取到之后才能真正地登陆
p = re.compile('location\.replace\([\'"](.*?)[\'"]\)')
try:
login_url = p.search(text).group(1)
print login_url
#由于之前的绑定,cookies信息会直接写入
urllib2.urlopen(login_url)
print "Login success!"
except:
print 'Login error!'
return 0
#访问主页,把主页写入到文件中
url = 'http://weibo.com/u/2679342531/home?topnav=1&wvr=6'
request = urllib2.Request(url)
response = urllib2.urlopen(request)
text = response.read()
fp_raw = open("e://weibo.html","w+")
fp_raw.write(text)
fp_raw.close()
#print text
wblogin = weiboLogin()
print '新浪微博模拟登陆:'
username = raw_input(u'用户名:')
password = raw_input(u'密码:')
wblogin.login(username,password)
5.结果截图
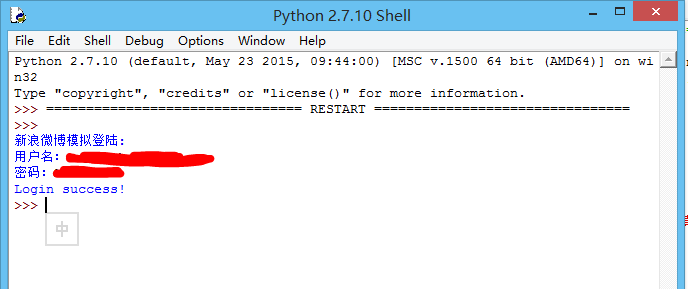
根据提示输入用户名和密码:
主页文件:
and then? 随心所欲的做自己喜欢的事~~~~~~~~~~~~~~~~~~
生命不息,奋斗不止!