Course Overview
数组下标越界访存
#include <stdio.h>
typedef struct {
int a[2];
double d;
} struct_t;
double fun(int i) {
volatile struct_t s;
s.d = 3.14;
s.a[i] = 1073741824;
return s.d;
}
int main() {
for (int i = 0; i < 100; ++i)
{
printf("fun(%d) = %.8lf\n", i, fun(i));
}
return 0;
}
fun(0) = 3.14000000
fun(1) = 3.14000000
fun(2) = 3.13999987
fun(3) = 2.00000061
fun(4) = 3.14000000
fun(5) = 3.14000000
zsh: segmentation fault

由于数组下标索引越界不检查,当i >= 2时会修改a数组内存后的区域。当修改a[2],a[3]的时候会影响到结构体双精度浮点数d的内存空间,从而影响fun函数的返回值。当i>=4时会继续修改后面的内存,当i为6时触发了段错误导致程序崩溃,该内存最有可能是记录已经分配的内存无法修改。
访问内存方式与性能的关系
#include <stdio.h>
#include <time.h>
int a[2048][2048], b[2048][2048];
void copyij(int src[2048][2048], int dst[2048][2048])
{
int i, j;
for (i = 0; i < 2048; ++i)
{
for (j = 0; j < 2048; ++j)
{
dst[i][j] = src[i][j];
}
}
}
void copyji(int src[2048][2048], int dst[2048][2048])
{
int i, j;
for (j = 0; j < 2048; ++j)
{
for (i = 0; i < 2048; ++i)
{
dst[i][j] = src[i][j];
}
}
}
int main()
{
clock_t start_time, end_time;
double duration;
start_time = clock();
copyij(a, b);
end_time = clock();
duration = double(end_time - start_time) / CLOCKS_PER_SEC;
printf("copyij的运行时间: %lf\n", duration);
start_time = clock();
copyji(a, b);
end_time = clock();
duration = double(end_time - start_time) / CLOCKS_PER_SEC;
printf("copyji的运行时间: %lf", duration);
return 0;
}
copyij的运行时间: 0.024819
copyji的运行时间: 0.112909
CLOCKS_PER_SEC是标准c的time.h头函数中宏定义的一个常数,表示一秒钟内CPU运行的时钟周期数,用于将clock()函数的结果转化为以秒为单位的量,但是这个量的具体值是与操作系统相关的。
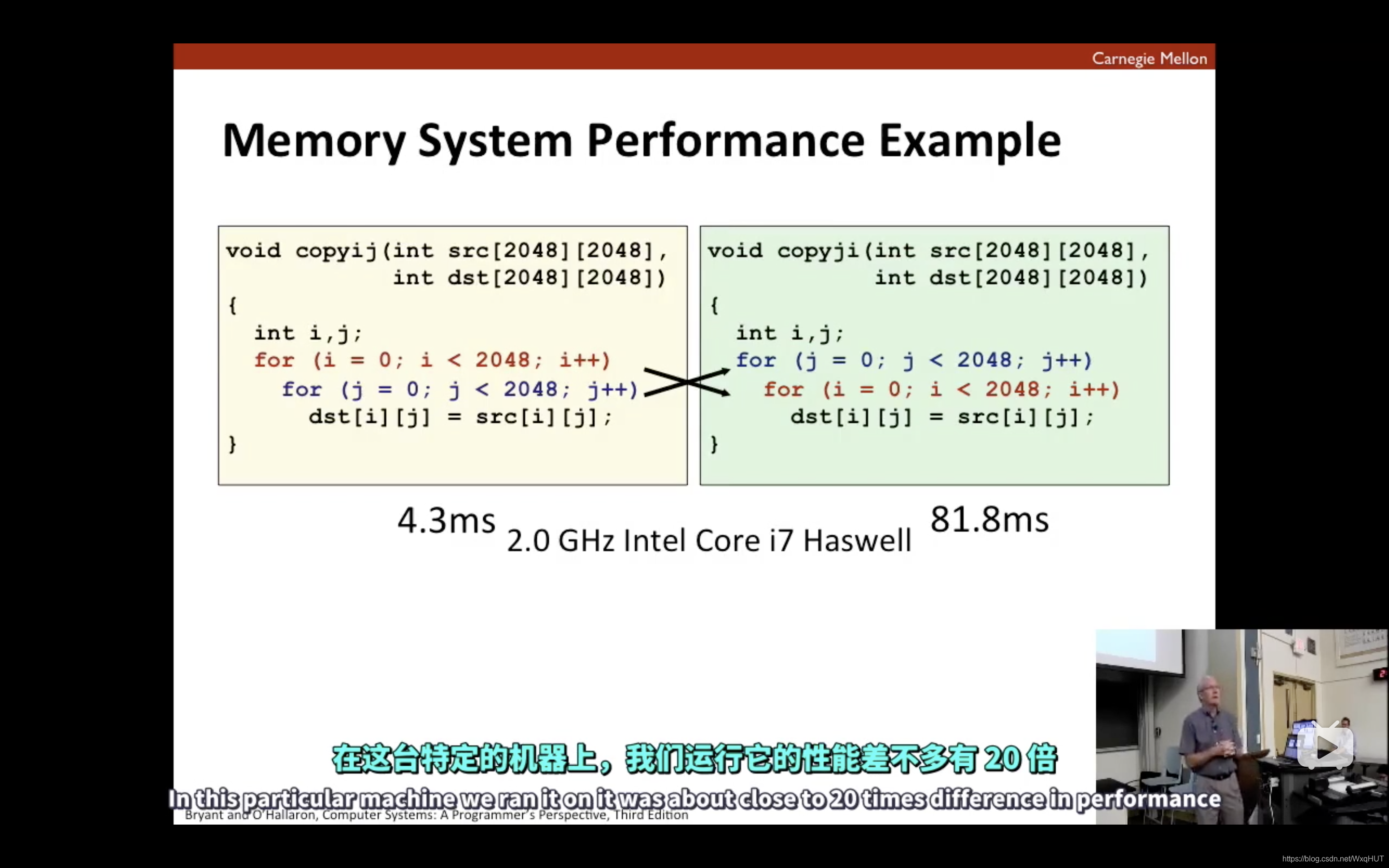
在一台普通个人台式机上粗略计算可以看到copyij与copyji性能上的差距,特定的机器上,我们运行它的性能会有更大的差距。不同的访存方式会有不同的性能体验,很明显得得出结论先行再列的访问方式由于先列后行的方式。我的猜想是:dst[i][j]实质是指针访问*((dst + i * 2048) + j)频繁地移动回溯指针性能消耗大。