从技术研发者角度看RAID
在一个IO的旅程中基本上都会经历一个非常重要站点,他就是RAID。提起RAID,基本上是无人不晓,每个人都能说上一点。例如RAID5、RAID6之类的概念,此外,RAID可以提高数据可靠性,但是考虑到IO 性能等问题,很多人都会采用硬件RAID卡对IO进行加速。诸如此类的东西,或许大家都知道。从表面上看,RAID似乎很简单,多块磁盘聚合在一起,采用一定的数据分布算法将数据分布到多块磁盘上,这就构成了RAID。是的,从外表来看,RAID的确很简单,经过这么多年的发展,很多人也将RAID放入了古老技术的行列。但是,从技术研发者的角度来看,RAID其实很复杂,为什么这么说呢?这主要是因为在设计RAID的时候,有很多棘手的问题需要解决。这些棘手的问题主要包括如下几个方面:
1)数据小写问题。RAID把多块磁盘绑定在一起,并且在水平方向进行条带切分,每个条带都会横跨多块磁盘。重要的是每个条带会生成一个或者多个校验冗余数据。在写入操作的时候,需要更新校验冗余数据。在写入数据量比较小的情况下,为了生成校验冗余数据,那么需要读取条带中没有被更新过的数据,然后计算得到校验数据,最后将条带数据写入磁盘。显然,在整个过程中,存在一个写放大的问题,一个简单的写操作变成了“读-更新-写”的操作。所以,小写问题对RAID的性能带来极大的影响。
2)校验数据计算问题。对于常用的RAID5、RAID6,是需要计算校验数据的。这些校验数据的计算看起来不是很复杂,其实是很耗CPU时间的。常用的CPU不擅长数值计算,如果直接将乘法等运算交给CPU来做,那么RAID6的复杂度就会变得很高。大量的计算会使得IO延迟大为增加,从而使得RAID很难在对实时性和吞吐量要求比较高的场合应用。
3)数据重构问题。随着磁盘容量的不断增加,数据重构的时间会变得越来越长。较长的数据重构时间会使得数据可靠性变得越来越差。数据重构时间是一个RAID非常棘手的问题,该问题导致现有RAID技术很难在大数据环境下应用。要想解决该问题,需要从架构设计上颠覆现有RAID技术,并且打破现有RAID在数据重构过程中的读、写性能瓶颈。只有这样,才有可能解决RAID数据重构的性能问题。
4)一致性性能问题。当RAID处于降级模式时,系统中不仅会存在上层应用的IO,而且还会存在数据重构的IO,并且这两类IO会交织融合在一起,使得双方的性能都变得很差。这主要是因为,应用IO和数据重构IO的交织,使得磁盘读写出现抖动,从而应用IO和数据重构IO的性能都急剧下降。所以,如何保证应用IO性能在正常模式下和降级模式下都达到一个比较均衡的水平,是RAID设计者需要考虑的问题。
上述的四个问题是RAID研发过程中面临的最大问题,有些问题至今都很难完满解决。所以,RAID技术不是一种古老技术,而是一个欣欣向荣的存储底层技术。抛开RAID这个传统的概念,剖析一下RAID技术所要解决的问题究竟是什么?其实,大家也知道,RAID主要是为了解决存储性能问题和数据可靠性问题。存储性能问题的解决其实是一个附加值的体现,数据可靠性问题的解决才是RAID的精华所在。所以,简单来看,RAID技术的本质是想解决数据可靠性问题。那么为了解决这个问题,技术研发者是可以抛开现有RAID架构,采用新的架构、方法实现数据冗余,从而达到数据可靠性的效果。所以,在大数据环境下,广义RAID还会有其重要作用的。
RAID数据分布
RAID的数据分布是很讲究的。在RAID5之前,所有的校验数据集中在一块磁盘上,此时,这个磁盘就成了校验数据瓶颈。为了解除这种瓶颈,RAID5、RAID将校验数据采用分布是存储的方式。下图是RAID的校验数据分布。
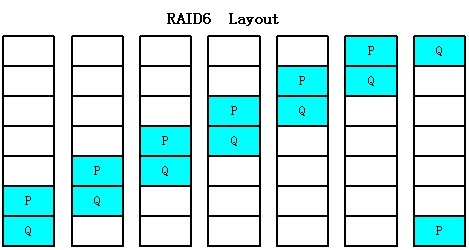
这种数据分布被称之为左循算法,PQ分布是可以通过条带号计算出来的。从上图我们也可以知道RAID的数据分布和物理磁盘是一一对应的,通过逻辑条带号就可以知道数据在每个物理磁盘上的分布情况。仔细考虑一下,RAID6之类的算法其实是一种数据保护算法,是一种数据编解码算法。传统的RAID将这种数据保护算法和物理磁盘进行了紧耦合绑定,这是传统RAID的一大特征。
其实,数据保护算法完全可以在一种逻辑域中完成,物理磁盘的管理可以在一种物理域中实现。逻辑域和物理域可以通过某种映射关系联系在一起。逻辑域和磁盘物理域拆分的最主要目的是加速数据重构过程,并且可以优化应用层性能一致性的问题。拆分之后的两个域之间关系可以表示如下:
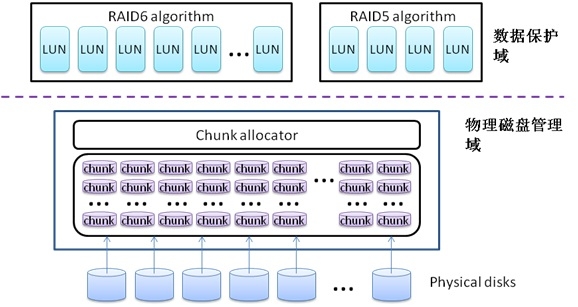
通过这种架构上的拆分,RAID中的数据分布将会发生本质上的变化。例如一个盘阵系统中有20块磁盘,其中创建了一个RAID5和一个RAID6。那么,通过物理磁盘管理域中allocator的资源分配,RAID5和RAID6 中的数据将会均匀分布在所有的20块磁盘中,而不是RAID5的数据分布在固定10块磁盘上,而RAID6的数据分布在另外10块磁盘上。这种数据布局打破了传统RAID的规则数据分布,带来的最大好处就是提升数据重构性能。通过上述描述,我们可以知道一块物理磁盘上存储的数据涉及到所有数据保护域的RAID。所以,当一块物理磁盘损坏之后,所有的RAID都会参与到数据重构的过程中,而不仅仅是一个RAID的事情了。这就好比传统RAID在处理数据重构时,都是“自家各扫门前雪”,但是,引入新型架构之后,数据重构过程就变成了“众人拾材火焰高”。
随着磁盘容量的进一步增大,数据重构和一致性性能将会变成RAID的两大最重要问题。在现有RAID基础上,如果不改变RAID架构,那么这个问题将会变得很棘手,难于解决。除非采用影响性能的擦除码来增强冗余度。
RAID算法实现
RAID6算法是RAID实现过程中需要考虑的重要问题,从算法本身来看,RAID6算法是比较简单的:
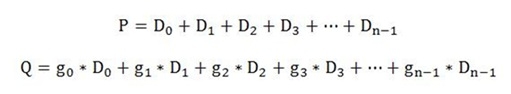
P码运算很简单,只需要把所有的数据累加起来就可以了。Q略有复杂,需要涉及到乘法运算。将上面的算式表示成矩阵的形式,表示如下:

输入数据和编码矩阵的乘积就是我们需要存储的RAID数据。
我们知道CPU的强项不在于算术运算,一次乘法运算需要耗费很多个指令周期,因此,如何避免编解过程中的乘法运算成了RAID技术实现的重点。要做到高效编码,需要引入一个有限域——加逻华域。在加逻华域中,加法运算变成了异或XOR运算,显然能够提高效率。但是,在加逻华域中,乘法运算还是二进制乘法,还具有一定的复杂度,为了将这种乘法运算转换成简单的异或操作,又引入了对数/反对数操作。我们知道,通过对数操作可以将乘法转换成加法操作,这个特性被RAID编解码采用了。例如,A*B的操作就可以通过如下方式进行转换:
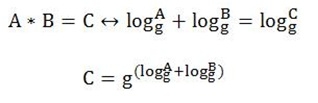
所以,A*B的计算过程可以分解成如下四步:
1)通过对数表查到logA的值A1
2)通过对数表查到logB的值B1
3)将A1和B1进行异或运算,得到C1
4)通过反对数表查到C1对应的值C
通过上述方法,可以将RAID的所有编解码操作转换成了异或XOR操作,从而可以提高IO效率。
<待续>