实际开发过程中,大家肯定都使用过for()循环与foreach()循环,但是有没有思考过什么时候选择for(),什么时候选择foreach(),两者的使用场景以及遍历效率的区别?下面就来一起揭秘两者的使用与区别。
for循环和foreach循环的选择使用
一、思考案例
统计一个省的各科高考平均值,比如数学平均分是多少,语文平均分是多少等,这是每年招生办都会公布的数据,我们来想想看该算法应如何实现。当然使用数据库中的一个SQL语句就可能求出平均值,不过这不再我们的考虑之列,这里还是使用纯Java的算法来解决之,看代码:
@Test
public void test1() {
// 学生数量 300万
int stuNum = 300 * 10000;
// List集合,记录所有学生的分数
List<Integer> scores = new ArrayList<Integer>(stuNum);
// 写入分数
for (int i = 0; i < stuNum; i++) {
scores.add(new Random().nextInt(150));
}
// 记录开始计算 时间
long start = System.currentTimeMillis();
System.out.println("平均分是:" + average(scores));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + "ms");
}
/**
* 求平均数
* @param scores 分数集合
* @return
*/
public static int average(List<Integer> scores) {
int sum = 0;
// 遍历求和
for (int i : scores) {
sum += i;
}
return sum / scores.size();
}
- 300万名考生的成绩放到一个ArrayList数组中,然后通过foreach方法遍历求和,再计算平均值,程序很简单,运行结果:
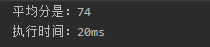
- 上面方法在遍历list时使用了foreach进行遍历操作,只是计算一个算术平均值就花了20ms,不要说什么其它诸如加权平均值,补充平均值等算法,那花的时间肯定更长。仔细分析一下average方法,加号操作是最基本的,没有什么可以优化的,剩下的就是一个遍历了,问题是List的遍历可以优化吗?
二、优化List的遍历方式
这里尝试将list的遍历方式更改为普通for循环(下标遍历):
/**
* 求平均数
* @param scores 分数集合
* @return
*/
public static int average(List<Integer> scores) {
int sum = 0;
// 遍历求和
for (int i = 0; i < scores.size(); i++) {
sum += scores.get(i);
}
return sum / scores.size();
}
- 当把遍历方法更改为普通for以后,来看看运行效率:

- 很明显,执行时间少了4ms,如果是更大数据量效果会更加明显。那为什么使用下标方式遍历数组可以提高的性能呢?
- 原因: 因为ArrayList数组实现了RandomAccess接口(随机存取接口),这样标志着ArrayList是一个可以随机存取的列表。在Java中,RandomAccess和Cloneable、Serializable一样,都是标志性接口,不需要任何实现,只是用来表明其实现类具有某种特质的,实现了Cloneable表明可以被拷贝,实现了Serializable接口表明被序列化了,实现了RandomAccess接口则表明这个类可以随机存取,对我们的ArrayList来说也就标志着其数据元素之间没有关联,即两个位置相邻的元素之间没有相互依赖和索引关系,可以随机访问和存取。我们知道,Java的foreach语法时iterator(迭代器)的变形用法,也就是说上面的foreach与下面的代码等价:
/**
* 求平均数
* @param scores 分数集合
* @return
*/
public static int average(List<Integer> scores) {
int sum = 0;
// 遍历求和
for (Iterator<Integer> i = scores.iterator(); i.hasNext();) {
sum += i.next();
}
return sum / scores.size();
}
- 也就是说使用foreach遍历ArrayList需要先创建一个迭代器容器,这个容器屏蔽了内部细节,对外只提供hasNext、next等方法。这就是问题的所在,ArrayList本身实现RandomAccess接口,元素之间本来就没有关系,但是使用foreach后,通过迭代器强行的去建立元素之间的关系,上一个元素遍历完成后,需要判断下一个元素是否存在,这样就降低了遍历的效率,所以foreach对于ArrayList的遍历会比for遍历低效;
- 那是不是就表明foreach循环的效率真的就比for循环的效率低呢?再来看一个示例;
三、for循环遍历LinkedList
示例代码如下:
@Test
public void test1() {
// 学生数量 10万
int stuNum = 10 * 10000;
// List集合,记录所有学生的分数
List<Integer> scores = new LinkedList<>();
// 写入分数
for (int i = 0; i < stuNum; i++) {
scores.add(new Random().nextInt(150));
}
// 记录开始计算 时间
long start = System.currentTimeMillis();
System.out.println("平均分是:" + average(scores));
long end = System.currentTimeMillis();
System.out.println("执行时间:" + (end - start) + "ms");
}
/**
* 求平均数
* @param scores 分数集合
* @return
*/
public static int average(List<Integer> scores) {
int sum = 0;
// 遍历求和
for (int i = 0; i < scores.size(); i++) {
sum += scores.get(i);
}
return sum / scores.size();
}
- 示例代码的测试数据更换成了10万条,因为使用for循环遍历300万条数据,程序直接卡死了,代码运行结果:
- for循环遍历LinkedList的运行结果(10万条数据):

- foreach循环遍历LinkedList的运行结果(10万条数据):

- 很明显在对LinkedList进行遍历操作时,for循环的效率比foreach循环的效率低了100倍不止,这是什么原因呢?来看看LinkedList.get()方法的源码:
/**
* Returns the element at the specified position in this list.
*
* @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
checkElementIndex(index);
return node(index).item;
}
//...............中间源码已省略...............
/**
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
Node<E> x = first;
for (int i = 0; i < index; i++)
x = x.next;
return x;
} else {
Node<E> x = last;
for (int i = size - 1; i > index; i--)
x = x.prev;
return x;
}
}
- LinkedList.get()方法通过node()方法查找指定下标的节点,然后返回其包含的元素,而node()方法会先判断输入的下标与中间值(size右移一位,也就是除以2了)的关系,小于中间值则从头开始正向搜索,大于中间值则从尾节点反向搜索,也就是说每一次get()操作都是一次新的遍历,性能理所当然会低;
- 那为什么相比之下foreach循环 效率就很高?这是因为LinkedList类实现了双向链表,每个数据节点都有三个数据项:前节点的引用(Previous Node)、本节点元素(Node Element)、后继结点的引用(Next Node),也就是说在LinkedList中的两个元素本来就是有关联关系的。既然元素之间已经有关联关系,使用foreach循环也就是迭代器方式肯定就比for循环要高效很多;
四、方法改进
明白了for()循环和foreach()循环对于数组结构和链表结构遍历时的效率差别后,可以对示例中average方法进行一下小改进,以便实现不同的列表采用不同的遍历方式,代码如下:
/**
* 求平均数
* @param scores 分数集合
* @return
*/
public static int average(List<Integer> scores) {
int sum = 0;
if (scores instanceof RandomAccess) {
// 可以随机存取,则使用下标遍历
for (int i = 0; i < scores.size(); i++) {
sum += scores.get(i);
}
} else {
// 有序存取,使用foreach方式
for (int i : scores) {
sum += i;
}
}
return sum / scores.size();
}
五、结论
- 遍历随机存取列表(数组结构)时用for或者foreach都行:
1. 在固定长度或者长度不需要计算的时候for循环效率高于foreach循环;
2. 在不确定长度或者计算长度有损性能的时候用foreach比较方便; - 遍历有序存取列表(链表结构)时,一定不要用for循环;
- 所以for循环与foreach循环的效率没有绝对高低,具体数据结构选择具体的遍历方式,才能使程序更加的高效;