一、在master节点上下载所有核心组件


1. 下载镜像
一定要先切换到root用户再下载

docker pull anjia0532/kube-apiserver-amd64:v1.10.2
docker pull anjia0532/kube-controller-manager-amd64:v1.10.2
docker pull anjia0532/kube-scheduler-amd64:v1.10.2
docker pull anjia0532/kube-proxy-amd64:v1.10.2
docker pull anjia0532/etcd-amd64:3.1.12
docker pull anjia0532/pause-amd64:3.1
docker pull anjia0532/k8s-dns-sidecar-amd64:1.14.8
docker pull anjia0532/k8s-dns-kube-dns-amd64:1.14.8
docker pull anjia0532/k8s-dns-dnsmasq-nanny-amd64:1.14.8
注:
azure开放了gcr(google container registry)的代理:gcr.azk8s.cn,我们也可以通过下面的方式来下载k8s.gcr.io上的镜像文件,以pause-amd64:3.0为例:
docker pull gcr.azk8s.cn/google_containers/pause-amd64:3.0
下载后再重新打tag。


2. 给镜像打标签
docker tag anjia0532/kube-apiserver-amd64:v1.10.2 k8s.gcr.io/kube-apiserver-amd64:v1.10.2
docker tag anjia0532/kube-scheduler-amd64:v1.10.2 k8s.gcr.io/kube-scheduler-amd64:v1.10.2
docker tag anjia0532/kube-controller-manager-amd64:v1.10.2 k8s.gcr.io/kube-controller-manager-amd64:v1.10.2
docker tag anjia0532/kube-proxy-amd64:v1.10.2 k8s.gcr.io/kube-proxy-amd64:v1.10.2
docker tag anjia0532/etcd-amd64:3.1.12 k8s.gcr.io/etcd-amd64:3.1.12
docker tag anjia0532/pause-amd64:3.1 k8s.gcr.io/pause-amd64:3.1
docker tag anjia0532/k8s-dns-sidecar-amd64:1.14.8 k8s.gcr.io/k8s-dns-sidecar-amd64:1.14.8
docker tag anjia0532/k8s-dns-kube-dns-amd64:1.14.8 k8s.gcr.io/k8s-dns-kube-dns-amd64:1.14.8
docker tag anjia0532/k8s-dns-dnsmasq-nanny-amd64:1.14.8 k8s.gcr.io/k8s-dns-dnsmasq-nanny-amd64:1.14.8
查看是否都下载完了
docker images | grep gcr.io
二、初始化master节点

kubeadm init --apiserver-advertise-address=10.0.2.5 --pod-network-cidr=192.168.16.0/20 --ignore-preflight-errors=Swap
# 我自己的配置,此处的192.168.18.132为当前虚拟机的ip
# 这里的kubernetes-version一定要设置成和核心组件相同的版本,比如我们这里应该设置成1.10.2
# kubeadm init --apiserver-advertise-address=192.168.18.132 --pod-network-cidr=192.168.16.0/20 --kubernetes-version=v1.10.2
–pod-network-cidr是指配置节点中的pod的可用IP地址,此为内部IP
–apiserver-advertise-address 为master的IP地址
–kubernetes-version 通过kubectl version 可以查看到
如果报错,可以看看这两个教程
https://blog.csdn.net/u013288190/article/details/109028126
https://blog.csdn.net/u013288190/article/details/109028046
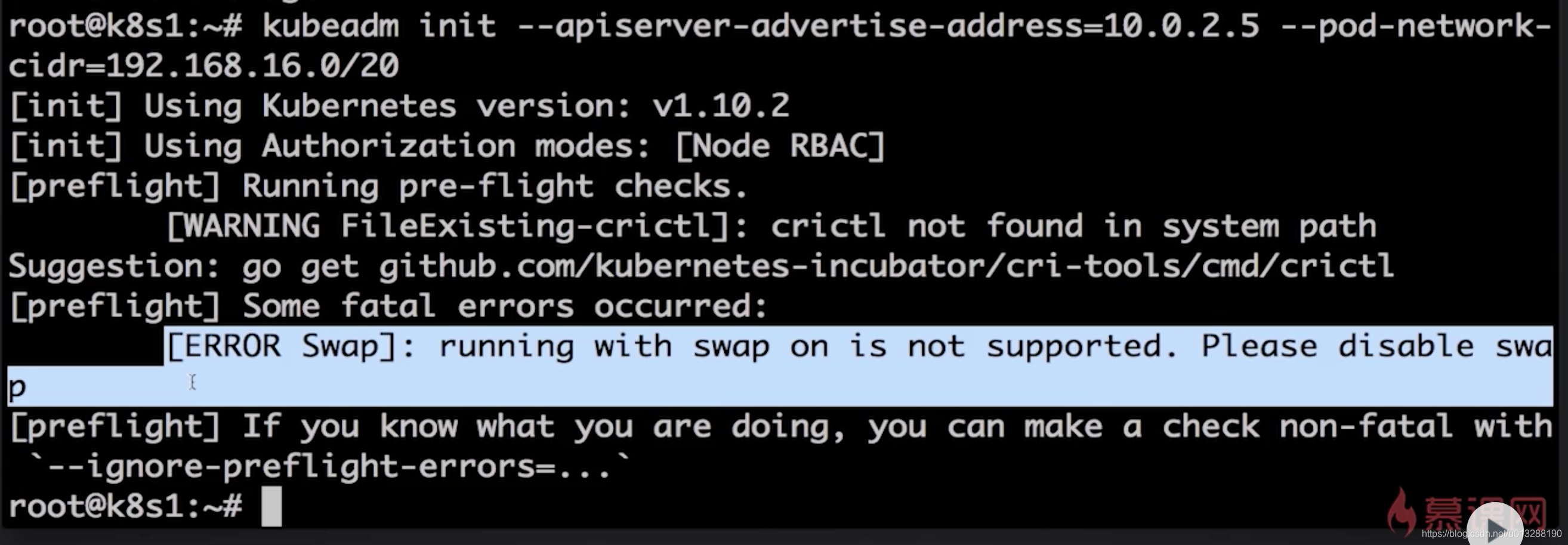
如果报错,则

vi /etc/fstab把最后一行,注释了
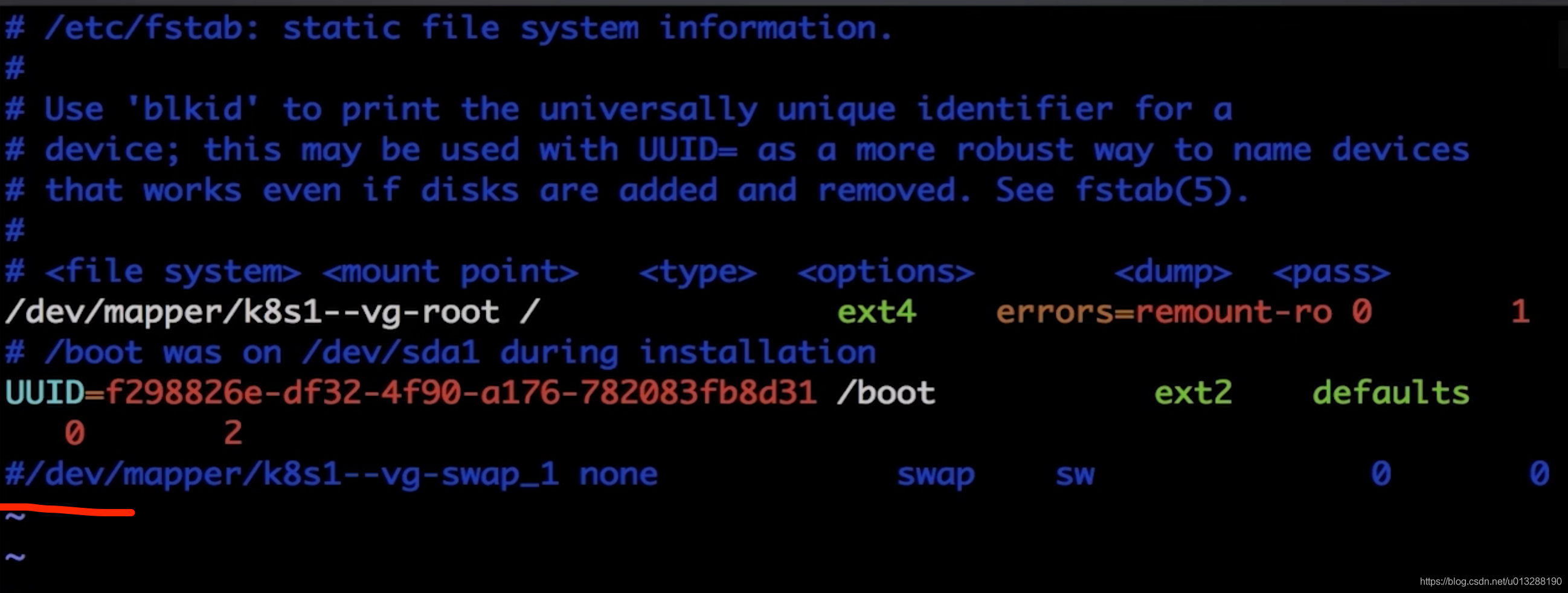
重启虚拟机
reboot now
重启初始化

保留下面这句,后续备用

比如我的
kubeadm join 192.168.18.132:6443 --token dvzyxu.wvxaymbz1x666xwv --discovery-token-ca-cert-hash sha256:10432bdce63bc3ee5fe2f7c71a0e0b9f905facea26f956f4fe67054e8d8e0e6b

export KUBECONFIG=/etc/kubernetes/admin.conf
kubectl get pods -n kube-system -o wide
如果要重启,即重新执行init,需要先执行reset
kubeadm reset
三、安装集群网络

安装weave cni插件:
方法1:
# kubectl apply -f "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')"
方法2: (应对weave pod启动时出现:Network 10.32.0.0/12 overlaps with existing route xx.xx.xx.xx/16 on host 错误信息)
# curl -L "https://cloud.weave.works/k8s/net?k8s-version=$(kubectl version | base64 | tr -d '\n')" > weave.yaml
vi weave.yaml
修改:IPALLOC_RANGE
# kubectl apply -f weave.yaml




kubectl get pods -n kube-system -o wide
四、worker节点只需要下载pod和proxy
分别安装k8s2和k8s3节点作为worker
1. 下载镜像
docker pull anjia0532/pause-amd64:3.1
docker pull anjia0532/kube-proxy-amd64:v1.10.22. 打标签
docker tag anjia0532/pause-amd64:3.1 k8s.gcr.io/pause-amd64:3.1
docker tag anjia0532/kube-proxy-amd64:v1.10.2 k8s.gcr.io/kube-proxy-amd64:v1.10.2五、将worker节点加入集群
1.在master节点查看所有节点

kubectl get nodes
2. 在worker节点执行加入命令

kubeadm join 192.168.18.132:6443 --token pro2xr.vzzelsp0s09jvd6u --discovery-token-ca-cert-hash sha256:28cb549b407f7d23c61d941459d7cd00849b520e8fb375c1bf22883f19290c00

3. 查看效果
kubectl get nodes
k8s3上也执行相同操作使其加入到集群中
