类型系统基础:静态类型和动态类型
我们知道,每一门高级程序设计语言都有自己的类型系统。由于所有数据在内存中都是字节(当然,内存中的字节并非皆为"数据",还有可执行的代码)。而同样32位二进制数据在不同的解释方式下具有完全不同的意义(最简单的例子便是IEEE double浮点数与int32类型的数据, 同样的32位bit解释为浮点数和int类型讲得到完全不一样的数值)
所以,我们需要一套系统来确定某一段内存的数据所拥有的类型。这套系统帮助程序员维护数据的类型信息,而不是让程序员将某个内存位置的数据到底代表什么记在脑子里(不要笑,在程序员用纸带和机器码写程序的时候,现实就是这样的)。
于是类型系统应运而生了,而类型又分为静态类型和动态类型。
静态类型
从程序运行或者二进制的角度,或者说“运行时”的角度来看,静态类型就是 没有类型。因为程序实际上不在运行时保存任何的静态类型。这也是静态类型又被称为”编译时类型“的原因,因为一旦经过编译,静态类型系统就基本上消失殆尽了。为什么又说基本上了呢,因为有时候,为了实现debug等功能,需要在可执行的二进制文件中(或者.lib .a .dll .so)文件中保存类型的信息,还有一些符号表信息。这也是编译为"release"版本的build目录要比debug版本小的原因。
既然静态类型不在运行时保存,那它是如何在编译中帮助编译器或者程序员识别数据类型的呢?
要回答这个问题,让我们来考察一下世界上最伟大的语言之一,也是最伟大的仅支持静态类型的语言之一,众神之父 — C语言。
C的静态类型
稍微有C语言程序基础以及一点汇编语言功底的人应该可以轻易回答这个问题,因为C语言中最神奇的事情就是强制类型转换了 — 尤其是当强制类型转换和指针结合在一起。各种优秀C项目的代码(包括各种#define 宏的奇技淫巧中)你都能看到指针和强制类型转换。
没错,所谓强制类型转换,就是改变了一块内存的解释方式,实际上,也就是静态类型。
静态类型说明数据解释方式
先看个例子
/* 向栈上压入一个字节的0*/
char ch = '\0';
/*在向栈上压入一个字节的7*/
char ch_lower = '\7';
/* 使一个指针指向第二个字节*/
int * pint = &ch_lower;
printf("ch_lower 的地址:%p, ch 的地址:%p\n", &ch_lower, &ch);
printf("ch_lowr 中的内容:%d\n", (int)ch_lower);
printf("%%x: %x\n", *pint);
执行结果如下

正如代码所表现的,借助一个指向int的指针,我们甚至读出了不该读出的内容:第一个局部变量地址以上的内容,如果该函数没有参数,或者想办法将int类型变成一个更长的类型,我们就能读出函数返回的地址。
不知道看到这里,你对静态类型有没有了一点认识。实际上,以上代码的核心思想,可以用几句话总结为:静态类型说明了数据的解释方式。
静态类型说明数据的使用方式
但是静态类型并不仅说明了数据的解释方式,同时还说明了数据的使用方式。还是举个例子
int c = 10;
int *pc = (int*)c;
printf("c的值:%d, pc的值:%d", c, pc);
printf("c + 1的值:%d, pc + 1的值:%d", c + 1, pc + 1);
输出结果为

为什么c+1 = 10 而pc + 1 = 14?
因为编译器在执行 pc + 1的时候并非执行的算数运算,而是执行的指针运算,其含义为指向下一个int。而一个int长度为32bit,4个字节。所以pc + 1 算出来就变成了14,然后再由编译器执行强制类型转换,交给printf函数。
简而言之,在对数据进行操作的时候 (+),编译器会根据静态类型的不同,而将不同的二进制操作应用于这些数据。
C++与Java中的静态类型与动态类型
由于C没有完备的动态类型系统,所以现在我们进入到C++与Java的部分.
C++的静态类型系统和C语言的如出一辙,唯一值得一提的地方就是结构体
跟上面的例子一样,我们完全可以定义一个结构体,然后在函数中声明一个指向该结构体的指针,然后用我们喜欢的方式来解释任意的内存地址(尤其是在内存保护机制微弱的内核中,这样灵活的代码随处可见,这也是C/C++的魅力之一)。
没错, someStuct -> someField将会被硬编码到代码中,变为某个内存地址加上某个偏移量,并且在运行时中不保留任何信息。而class是通过struct实现的,方法实际上就是放在某个struct中的函数指针。
对于一个声明类型(或者说类声明)
typedef struct _Some_Struck {
/* some code... */
} SomeStruct;
由于面向对象要求父类引用可以持有子类对象,所以对于一个子类对象引用(实际上就是指向堆里某个内存的指针)总能交给父类型的引用持有。
class Super {
/*some code*/}
class Extend : public Super{
/*some code*/}
Super *s = new Extend;
思考一下,如果C++不支持动态类型的话。你在内存上依照子类的类型开辟了一段空间,然后用父类的引用持有这个指针,然后这个子类对象就变得和父类对象没有任何区别了。因为你操作这个对象使用的是父类型的引用s,而s->someField的操作将按照s的静态类型进行。这看起来是非常搞笑的。(从某种角度来讲是不可接受的)。
所以到这里,C++加入了动态类型的方式(Java原生支持):无论持有对象的引用是何类型,使用该类型调用方法的时候,总是调用的正确类型的方法。(C++ 需要显示声明为virtual函数),这也要求程序在运行时保存类型的信息。(关于程序如何保存运行时信息这里就不展开谈了)
总结一下,以上这种在调用方法时动态查询对象的真实类型然后根据真实类型调用对应的方法的类型系统,就是动态类型系统。
Java类型系统地狱 – 自限定泛型
简介了类型系统,现在是时候搬上今天的主角了,Java自限定泛型,先上代码
class Gen<T extends Gen<T>> {
}
来跟我念一下,我声明了一个类型,这个类型有一个泛型参数,该泛型参数有一个以我声明的类型的泛型参数为泛型参数,并以我声明的类型为类型上界的泛型上界。
乍一看觉得有点糊,谁会这样声明一个类???
实际上JDK源码中由相当一部分使用自限定代码的地方,比如Enum;

看到这里已经慌了对不对,没问题,这段代码完全可以通过编译,但是,当你想要尝试创建一个这样的引用时,更可怕的事情发生了

以String为例,假设我想用String作为我的泛型,我会发现,无论怎么样都会失败。
(除非用原始类型,但那样就不好玩了)
那我就纳闷了,那这个破类到底要怎么用?
在查阅了一些资料,并烧掉了一部分脑细胞以后,我终于找到了问题的答案。
古怪的循环泛型
我们不妨先观察<>中的内容 T extends Enum<T>
有点奇怪,这样的类型定义能通过编译嘛?
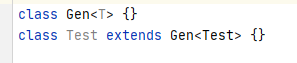
确实没有任何问题,但是,为什么?
类还没有定义完,为什么就可以跑到自己的类声明中去?还是在泛型参数里。这不就是循环无限递归嘛?
其实不是的,到这里,我们刚刚花了很大篇幅讲的静态类型与动态类型就派上用场了。实际上,静态类型的确定,并不需要 知道该类型的所有信息。有点懵对不对,我们再回到C语言,来看一段C的经典代码
struct SomeStruct {
int a_int;
SomeStruct* some_struct;
int another_int;
/* some code */
}
为什么在SomeStruct还未定义完全的时候就可以定义该结构中定义SomeStruct结构的指针?这难道看起来不奇怪吗?是的,仔细想的话,这是一件相当奇怪的事情,不过,还有更奇怪的事情呢,看下面这段Java代码
class Test {
int test = this.test;
}
这段代码完全可以通过编译,没有什么循环定义,不知道你脑子昏了没有?
现在就来解开谜题,这需要使用使用静态类型的思维方式:当定义SomeStruct的时候,编译器其实并不关心some_struct字段指向的类型有没有被定义完全。它只需要扫描全部的字段定义,然后知道some_struct字段是一个32位的数据就可以了,没错,因为在32位的系统中,所有指针都是32位的。
这样一来,即便是在SomeStruct类的方法代码中,使用some_struct字段的代码也会被正确的硬编码(因为偏移量是确定的,使用方式基本上也是确定的 – 反正都是指针)。
接下来这段Java代码其实是一样的, int test 其实就是在一个结构上声明了一个字段而这个字段初始化器(实际上是代码, 代码会被静态硬编码,还记得吗)将这个结构(对象)这个字段(偏移量)里的值赋值到这个字段中,实际上等于啥事儿也没做,而不是无限循环。
好了,搞懂了这些,我们就知道了
class Test extends Gen<Test>{
}
代码之所以能通过编译的原因了,因为这段代码实际上就是往Test结构体中加入了一堆使用Test作为返回值和参数的函数和字段声明;我不知道读者是否理解泛型类的目的:一个泛型类就是为了在类中定义使用类型参数作为返回值、函数参数、字段类型的字段声明和函数声明。
所以!!总结一下,上面这段代码,这段古怪的循环定义,实际上就是定义了一个类,这个类里面有一堆方法和字段,使用了这个类型自己本身作为返回值或者参数或者字段类型。
将古怪的循环定义类型作为类型参数
现在回到大boss自限定类型
class Gen<T extends Gen<T>> {
}
我们已经了解了Gen的<>参数类型的意义,就是一个可爱的循环定义而已。也就是说,我们现在定义了一个泛型类型,这个泛型类型Gen有一堆方法会使用和返回一个泛型T,这个T有这样一种特性:类型T有一堆方法,会返回和使用T自己。好了,over;
等一下,我知道你想说Gen类型出现在了自己的类型定义的泛型参数中。但是!!!我们已经花了很大的篇幅说明了,这并没有什么问题。由于泛型的类型系统是静态 的所以定义Gen的时候只需要知道他有多少字段,和函数,这些字段和函数占多少位,就可以了。当有代码使用这些自引用字段的时候,再根据静态类型硬编码就行了。
那问题是,Gen拿来有什么用呢,这玩意儿怎么都循环啊;
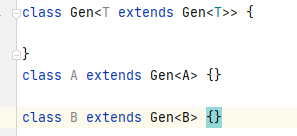
没错,Gen就是用来定义古怪的循环定义的,实际上
class C extends Gen<A> {
}
也可以通过编译,因为A extends Gen<A>,所以Gen<A>是合法的,因为Gen的类型参数要求是如下形式:T extends Gen<T>,将T换成A就可以了。
总结
最后总结一下,把最精髓的话拿出来:
我们现在定义了一个泛型类型,这个泛型类型Gen有一堆方法会使用和返回一个泛型T,这个T有这样一种特性:类型T有一堆方法,会返回和使用T自己,这也是自限定名称的由来。
现在来考察一下enum,你会发现枚举类型有一堆方法会返回和使用自己,而返回的自己当然也有一堆方法会返回自己,现在知道自限定类型的用法了吗?