欢迎来到猿史天尊的博客
误区:byte数组在不确定是哪种编码集的情况下,以任意一种编码集将byte转成String字符串,再以同样的编码集将String字符串转成byte数组。前后byte数组是一样的。
这么理解是错误的!!byte数组很有可能含有中文。但事先我们也不知道有没有中文,导致前后byte数组发生改变。
话不多说。上代码,执行一下,看下结果。
public static void main(String[] args) throws UnsupportedEncodingException {
String str = "123木头人";
/**生成相应编码集的byte数组,假设编码集并不知情*/
byte[] bytes = str.getBytes("UTF-8");
//byte[] bytes = str.getBytes("GBK");
//byte[] bytes = str.getBytes("GB2312");
//byte[] bytes = str.getBytes("ISO8859-1");
//byte[] bytes = str.getBytes("GB18030");
/**打印转换前byte数组*/
System.out.println(Arrays.toString(bytes));
/**编码集转换*/
String newstr = new String(bytes,"GBK");
byte[] bytes2 = newstr.getBytes("GBK");
/**打印转换后byte数组*/
System.out.println(Arrays.toString(bytes2));
}
执行结果
[49, 50, 51, -26, -100, -88, -27, -92, -76, -28, -70, -70]
[49, 50, 51, -26, -100, -88, -27, -92, -76, -28, -70, 63]
由此可见,编码集转换之后,byte已不在是原来的数据。
根据上述情况。针对比较常用的编码集(UTF-8、GBK、GB2312、ISO8859-1、GB18030)我们做了一个完整的测试。测试结果如下图。
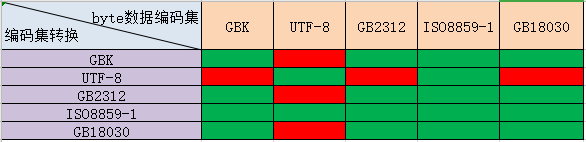
红色代表前后byte不一致。绿色代表前后byte没有变化。
总结
1. UTF-8与GB系列(GBK、GB2312、GB18030)编码集之间转换,有中文时需慎重。
2. byte数组在不确定是哪种编码集的情况下。进行ISO8859-1编码转换是完全OK的。
3. byte数组是ISO8859-1编码的情况下。上述编码集都可以进行转换。数组不会改变。