前言
本文讨论Connector/J 的failover模块。通过获取连接,我们观察连接的构造,获得相关类的UML图,进而分析failover的运行机制(包括连接的切换方式和异常的处理),最终分析此模式的实用性。
本次分析的版本为5.1.46。若通过maven下载,可添加以下依赖:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.46</version>
</dependency>我们获取连接的例子如下:
Connection conn = null;
URL =“jdbc:mysql://ip1:port1,ip2:port2,ip3:port3/dbname”;
try{
// 注册 JDBC 驱动
Class.forName("com.mysql.jdbc.Driver");
// 打开链接
conn = DriverManager.getConnection(DB_URL,USER,PASS);
....一、什么是Failover?
官方用两段文字对Failover进行描述:
MySQL Connector/J supports server failover. A failover happens when connection-related errors occur for an underlying, active connection. The connection errors are, by default, propagated to the client, which has to handle them by, for example, recreating the working objects (Statement, ResultSet, etc.) and restarting the processes. Sometimes, the driver might eventually fall back to the original host automatically before the client application continues to run, in which case the host switch is transparent and the client application will not even notice it.
A connection using failover support works just like a standard connection: the client does not experience any disruptions in the failover process. This means the client can rely on the same connection instance even if two successive statements might be executed on two different physical hosts. However, this does not mean the client does not have to deal with the exception that triggered the server switch.
大意是说,通常情况下连接发生异常,调用方就得放充当前连接,获取新连接,重新一遍之前的操作。而有了failover特性后,它会在底层的连接出状况时候产生作用,它不会让调用方当前的操作崩掉而重新再来。在failover的作用下,调用方只需保持着一个连接,尽管前后两条SQL命令有可能在两台不同的设备上执行。
通过官方的描述,看起来调用方很轻松,拿看一个连接就可走天下了。但细想一下,如果当前的操作是带事务的,前后两条命令在不同设备上执行,事务还会生效?官方的最后一句是说有了failover并不意思的调用方高枕无忧,那么到底调用方在什么情况下需要做什么处理呢?后面章节我们尝试一一揭开这些迷。
二、Failover的主要结构
Failover模块有几个重要角色:FailoverConnectionProxy、JDBC4MultiHostMySQLConnection、构造普通Connection连接以及代理。下面通过我们的例子一探它们是如何构造的。
2.1 构造过程
我们直接从DriverManager#getConnection方法跳到ConnectionImpl#connect方法。中间过程看官可看《Mysql Connector/J 源码分析(普通Connection)》。

public java.sql.Connection connect(String url, Properties info) throws SQLException {
if (url == null) {
throw SQLError.createSQLException(Messages.getString("NonRegisteringDriver.1"), SQLError.SQL_STATE_UNABLE_TO_CONNECT_TO_DATASOURCE, null);
}
if (StringUtils.startsWithIgnoreCase(url, LOADBALANCE_URL_PREFIX)) {
return connectLoadBalanced(url, info);
} else if (StringUtils.startsWithIgnoreCase(url, REPLICATION_URL_PREFIX)) {
return connectReplicationConnection(url, info);
}
Properties props = null;
if ((props = parseURL(url, info)) == null) {
return null;
}
if (!"1".equals(props.getProperty(NUM_HOSTS_PROPERTY_KEY))) {
return connectFailover(url, info);
}
....
}因为我们的url没有loadbalance和replication模式的前缀,而且url里包括了超过一组的ip:port,所以程序进入connectFailover方法。
private java.sql.Connection connectFailover(String url, Properties info) throws SQLException {
Properties parsedProps = parseURL(url, info);
if (parsedProps == null) {
return null;
}
// People tend to drop this in, it doesn't make sense
parsedProps.remove("roundRobinLoadBalance");
int numHosts = Integer.parseInt(parsedProps.getProperty(NUM_HOSTS_PROPERTY_KEY));
List<String> hostList = new ArrayList<String>();
for (int i = 0; i < numHosts; i++) {
int index = i + 1;
hostList.add(parsedProps.getProperty(HOST_PROPERTY_KEY + "." + index) + ":" + parsedProps.getProperty(PORT_PROPERTY_KEY + "." + index));
}
return FailoverConnectionProxy.createProxyInstance(hostList, parsedProps);
}该方法先从属性对象里抽取出url内所有的ip:port组合放进新集合里,然后调用FailoverConnectionProxy#createProxyInstance方法。在前文《Mysql Connector/J 源码分析(普通Connection)》里我们发现,Connectionor/J 这个包里很喜欢通过静态块做一些事情,FailoverConnectionProxy也不例外,它也有通过静态块做了一些准备工作:
static {
if (Util.isJdbc4()) {
try {
INTERFACES_TO_PROXY = new Class<?>[] { Class.forName("com.mysql.jdbc.JDBC4MySQLConnection") };
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
} else {
INTERFACES_TO_PROXY = new Class<?>[] { MySQLConnection.class };
}
}因为现在用的Connectionor/J 的版本是5.1.46,所以Util#isJdbc4方法会返回真值。静态块的工作就是加载了JDBC4MySQLConnection接口进入虚拟机,并保存在INTERFACES_TO_PROXY静态变量里。
FailoverConnectionProxy#createProxyInstance方法如下:
public static Connection createProxyInstance(List<String> hosts, Properties props) throws SQLException {
FailoverConnectionProxy connProxy = new FailoverConnectionProxy(hosts, props);
return (Connection) java.lang.reflect.Proxy.newProxyInstance(Connection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}这里的java.lang.reflect.Proxy.newProxyInstance非常显眼,这不就是使用了动态代理吗?这条命令的签名里的第二个参数是接口数组,第三个参数是InvocationHandler接口的实现类,说人话就是接口数组里的每个接口的每条方法,都会被InvocationHandler接口的实现类进行代理。在此处的意思是被创建的动态代理,它被调用JDBC4MySQLConnection接口相关的每一条方法的时候,都会调用FailoverConnectionProxy实例对象的invoke方法。
我们先通过UML图观察JDBC4MySQLConnection接口的继承关系:
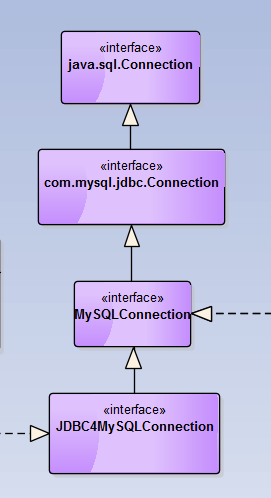
从上图的继承关系可知,java.sql.Connection到JDBC4MySQLConnection所有的方法都会被代理。

FailoverConnectionProxy没有直接实现InvocationHandler接口,是由它的父类MultiHostConnectionProxy实现该接口,所以父类重载了invoke方法,该方法会调用invokeMore方法,由于子类FailoverConnectionProxy已经重载了该方法,因此在程序运行中实际上会调用FailoverConnectionProxy#invokeMore方法,这是多态特性的决定的,从设计模式上也可理解为此处采用了模板模式。
现在我们知道了failover是采用了动态代理的方式,结果官方的介绍,调用方持有的Connection就是来自于FailoverConnectionProxy#createProxyInstance创建的动态代理。但是到现在为止,我们还没看到普通Connection的身影,在《Mysql Connector/J 源码分析(普通Connection)》里,我们看到在普通Connection的构造函数包括与Mysql服务器进行Socket和SSLSocket通讯连接的建立,那么在FailoverConnectionProxy的构造函数里会不会与普通Connection产生联系呢,我们继续看看它的构造函数:
private FailoverConnectionProxy(List<String> hosts, Properties props) throws SQLException {
super(hosts, props);
ConnectionPropertiesImpl connProps = new ConnectionPropertiesImpl();
connProps.initializeProperties(props);
this.secondsBeforeRetryPrimaryHost = connProps.getSecondsBeforeRetryMaster();
this.queriesBeforeRetryPrimaryHost = connProps.getQueriesBeforeRetryMaster();
this.failoverReadOnly = connProps.getFailOverReadOnly();
this.retriesAllDown = connProps.getRetriesAllDown();
this.enableFallBackToPrimaryHost = this.secondsBeforeRetryPrimaryHost > 0 || this.queriesBeforeRetryPrimaryHost > 0;
pickNewConnection();
this.explicitlyAutoCommit = this.currentConnection.getAutoCommit();
}在构造函数里,它首先调用了父类带双参数的构造函数:
MultiHostConnectionProxy(List<String> hosts, Properties props) throws SQLException {
this();
initializeHostsSpecs(hosts, props);
}我们再进入MultiHostConnectionProxy的无参构造函数:
MultiHostConnectionProxy() throws SQLException {
this.thisAsConnection = getNewWrapperForThisAsConnection();
}
MySQLConnection getNewWrapperForThisAsConnection() throws SQLException {
if (Util.isJdbc4() || JDBC_4_MS_CONNECTION_CTOR != null) {
return (MySQLConnection) Util.handleNewInstance(JDBC_4_MS_CONNECTION_CTOR, new Object[] { this }, null);
}
return new MultiHostMySQLConnection(this);
}
此处出现了JDBC_4_MS_CONNECTION_CTOR静态变量,估计是MultiHostConnectionProxy的静态块已赋值。我们先看看它的声明以及赋值:
private static Constructor<?> JDBC_4_MS_CONNECTION_CTOR;
static {
if (Util.isJdbc4()) {
try {
JDBC_4_MS_CONNECTION_CTOR = Class.forName("com.mysql.jdbc.JDBC4MultiHostMySQLConnection")
.getConstructor(new Class[] { MultiHostConnectionProxy.class });
} catch (SecurityException e) {
throw new RuntimeException(e);
} catch (NoSuchMethodException e) {
throw new RuntimeException(e);
} catch (ClassNotFoundException e) {
throw new RuntimeException(e);
}
}
}果不出其然,正是MultiHostConnectionProxy的静态块做了事情。我们回到MultiHostConnectionProxy的无参构造函数,它通过反射构造了JDBC4MultiHostMySQLConnect对象,并赋值给thisAsConnection属性。
JDBC4MultiHostMySQLConnection的一个参数且类型为MultiHostConnectionProxy的构造函数如下:
public JDBC4MultiHostMySQLConnection(MultiHostConnectionProxy proxy) throws SQLException {
super(proxy);
}它没做什么事情,直接调用父类的一个参数且类型为MultiHostConnectionProxy的构造函数,它的父类是MultiHostMySQLConnection,我们接着看它的构造函数:
public class MultiHostMySQLConnection implements MySQLConnection {
protected MultiHostConnectionProxy thisAsProxy;
public MultiHostMySQLConnection(MultiHostConnectionProxy proxy) {
this.thisAsProxy = proxy;
}
....
}在MultiHostConnectionProxy的构造函数里,把MultiHostConnectionProxy对象保存为自己的thisAsProxy属性。此时MultiHostConnectionProxy的真正身份是FailoverConnectionProxy对象。
到目前为止,在构造FailoverConnectionProxy的同时,也构造了JDBC4MultiHostMySQLConnection对象,它们互相知道彼此的存在。我们先继续观察MultiHostConnectionProxy的双参数构造函数还做了什么事情:
MultiHostConnectionProxy(List<String> hosts, Properties props) throws SQLException {
this();
initializeHostsSpecs(hosts, props);
}
int initializeHostsSpecs(List<String> hosts, Properties props) {
this.autoReconnect = "true".equalsIgnoreCase(props.getProperty("autoReconnect")) || "true".equalsIgnoreCase(props.getProperty("autoReconnectForPools"));
this.hostList = hosts;
int numHosts = this.hostList.size();
this.localProps = (Properties) props.clone();
this.localProps.remove(NonRegisteringDriver.HOST_PROPERTY_KEY);
this.localProps.remove(NonRegisteringDriver.PORT_PROPERTY_KEY);
for (int i = 0; i < numHosts; i++) {
this.localProps.remove(NonRegisteringDriver.HOST_PROPERTY_KEY + "." + (i + 1));
this.localProps.remove(NonRegisteringDriver.PORT_PROPERTY_KEY + "." + (i + 1));
}
this.localProps.remove(NonRegisteringDriver.NUM_HOSTS_PROPERTY_KEY);
return numHosts;
}在它的initializeHostsSpecs方法里,根据url获取autoReconnect属性值和对本地属性删除了一些属性。这里还有一个重要的操作是将ip:port组合集合设置为hostList属性值。它代表了将来failover操作可选择的范围。
最后, 我们回到FailoverConnectionProxy的双参数构造函数,看看父类构造完后还做了什么工作:
private FailoverConnectionProxy(List<String> hosts, Properties props) throws SQLException {
super(hosts, props);
ConnectionPropertiesImpl connProps = new ConnectionPropertiesImpl();
connProps.initializeProperties(props);
this.secondsBeforeRetryPrimaryHost = connProps.getSecondsBeforeRetryMaster();
this.queriesBeforeRetryPrimaryHost = connProps.getQueriesBeforeRetryMaster();
this.failoverReadOnly = connProps.getFailOverReadOnly();
this.retriesAllDown = connProps.getRetriesAllDown();
this.enableFallBackToPrimaryHost = this.secondsBeforeRetryPrimaryHost > 0 || this.queriesBeforeRetryPrimaryHost > 0;
pickNewConnection();
this.explicitlyAutoCommit = this.currentConnection.getAutoCommit();
}此处还取出failover模块的专有属性(secondsBeforeRetryPrimaryHost, queriesBeforeRetryPrimaryHost, failoverReadOnly, retriesAllDown),这些属性都可能在url上设置,当然了,不设置的话也有默认值。此处比较显眼的是pickNewConnection(),该方法是FailoverConnectionProxy重载了父类MultiHostConnectionProxy的pickNewConnection方法,MultiHostConnectionProxy#pickNewConnection方法只是一个虚方法。我们进去观察一下FailoverConnectionProxy#pickNewConnection:
@Override
synchronized void pickNewConnection() throws SQLException {
if (this.isClosed && this.closedExplicitly) {
return;
}
if (!isConnected() || readyToFallBackToPrimaryHost()) {
try {
connectTo(this.primaryHostIndex);
} catch (SQLException e) {
resetAutoFallBackCounters();
failOver(this.primaryHostIndex);
}
} else {
failOver();
}
}因为现在构造阶段,程序会直去执行connectTo方法。但这里我们留意下this.primaryHostIndex变量,从其命名看,就是指向主设备的下标,而这个属性的初始值为0。官网对url的规范如下:
jdbc:mysql://[primary host][:port],[secondary host 1][:port][,[secondary host 2][:port]]...[/[database]]»
[?propertyName1=propertyValue1[&propertyName2=propertyValue2]...]从中不难看出主设备放在第一组的ip:port,后面都是后备的。所以参数this.primaryHostIndex对应着第一组的ip:port。
我们继续看FailoverConnectionProxy#connectTo方法:
private synchronized void connectTo(int hostIndex) throws SQLException {
try {
switchCurrentConnectionTo(hostIndex, createConnectionForHostIndex(hostIndex));
} catch (SQLException e) {
if (this.currentConnection != null) {
StringBuilder msg = new StringBuilder("Connection to ").append(isPrimaryHostIndex(hostIndex) ? "primary" : "secondary").append(" host '")
.append(this.hostList.get(hostIndex)).append("' failed");
this.currentConnection.getLog().logWarn(msg.toString(), e);
}
throw e;
}
}在connectTo方法里,hostIndex被用在两处,此时它的值为0。
swithchCurrentConnectionTo方法的第二个参数是由createConnectionForHostIndex方法生成url某一组ip:port的连接,在当前,就是要生成第一组ip:port的连接。我们先进入createConnectionForHostIndex方法一探究竟:
synchronized ConnectionImpl createConnectionForHostIndex(int hostIndex) throws SQLException {
return createConnectionForHost(this.hostList.get(hostIndex));
}
synchronized ConnectionImpl createConnectionForHost(String hostPortSpec) throws SQLException {
Properties connProps = (Properties) this.localProps.clone();
....
ConnectionImpl conn = (ConnectionImpl) ConnectionImpl.getInstance(hostName, Integer.parseInt(portNumber), connProps, dbName,
"jdbc:mysql://" + hostName + ":" + portNumber + "/");
conn.setProxy(getProxy());
return conn;
}createConnectionForHostIndex最终调用createConnectionForHost函数构造了一个普通的Connection。
我们进入FailoverConnectionProxy#switchCurrentConnectionTo方法看下:
private synchronized void switchCurrentConnectionTo(int hostIndex, MySQLConnection connection) throws SQLException {
invalidateCurrentConnection();
boolean readOnly;
if (isPrimaryHostIndex(hostIndex)) {
readOnly = this.explicitlyReadOnly == null ? false : this.explicitlyReadOnly;
} else if (this.failoverReadOnly) {
readOnly = true;
} else if (this.explicitlyReadOnly != null) {
readOnly = this.explicitlyReadOnly;
} else if (this.currentConnection != null) {
readOnly = this.currentConnection.isReadOnly();
} else {
readOnly = false;
}
syncSessionState(this.currentConnection, connection, readOnly);
this.currentConnection = connection;
this.currentHostIndex = hostIndex;
}此处将刚刚创建的普通Connection保存为currentConnection属性,与该连接对应的ip:port组号保存为currentHostIndex属性。而中间关于readOnly变量的取值,可参考官网的描述,暂时不再详述。
2.2 小结
我们重新把目光放回FailoverConnectionProxy#createProxyInstance方法:
public static Connection createProxyInstance(List<String> hosts, Properties props) throws SQLException {
FailoverConnectionProxy connProxy = new FailoverConnectionProxy(hosts, props);
return (Connection) java.lang.reflect.Proxy.newProxyInstance(Connection.class.getClassLoader(), INTERFACES_TO_PROXY, connProxy);
}这两行代码做了以下操作:
- 构造FailoverConnectionProxy代理对象
- 构造JDBC4MultiHostMySQLConnection对象,并且它与FailoverConnectionProxy代理对象互知彼此。
- 构造普通Connection连接,作为FailoverConnectionProxy代理对象的当前连接对象。
- 构造动态代理Connection,返回给调用方。
最后我们通过UML类图展示各主要角色的关系:

了解了逻辑结构后,接下来一起看看failover机制是如何运作的。
三、Failover的运行机制
3.1 正常执行
3.1.1 一般情况
如前文所述,如果获取连接的过程正常的话,得到的Connection对象是被动态代理过的,所以调用它的接口方法时,都会进入FailoverConnectionProxy#invokeMore方法体。
@Override
public synchronized Object invokeMore(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
Object result = null;
try {
result = method.invoke(this.thisAsConnection, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
....
return result;
}以conn.setAutoCommit(false)为例,这里是通过反射机制触发方法被执行。而执行的主体是thisAsConnection属性,而根据前文描述,该属性保存的JDBC4MultiHostMySQLConnect对象。那么,该对象理论上是重载了setAutoCommit方法。然而在该类里找不到setAutoCommit方法,但可以在它的父类MultiHostMySQLConnection找得到该方法的定义:
public void setAutoCommit(boolean autoCommitFlag) throws SQLException {
getActiveMySQLConnection().setAutoCommit(autoCommitFlag);
}
public MySQLConnection getActiveMySQLConnection() {
synchronized (this.thisAsProxy) {
return this.thisAsProxy.currentConnection;
}
}根据前文MultiHostMySQLConnection的thisAsProxy属性就是FailoverConnectionProxy对象,所以setAutoCommit方法实际上通过代理类的当前连接来执行,也就是最终都是通过普通Connection来执行。
在MultiHostMySQLConnection里还可以发现其他java.sql.Connection接口方法的实现都是通过这种方式来处理。
根据java.sql.Connection接口的声明,Connection#setAutoCommit没有返回值,所以result = method.invoke(this.invokeOn, args)执行后result为空值,接下来proxyIfReturnTypeIsJdbcInterface方法对于空值不作任何处理,所以invokeMore方法最终返回的是空值。对于conn.setAutoCommit(false)命令来说,返回的空值没有影响。
如果执行的是conn.createStatement()命令,根据java.sql.Connection的接口声明,Connection#createStatement方法返回Statement实例。执行完result = method.invoke(this.thisAsConnection, args)后,result保存的是Statement对象。随后的proxyIfReturnTypeIsJdbcInterface方法会对它进行处理:
Object proxyIfReturnTypeIsJdbcInterface(Class<?> returnType, Object toProxy) {
if (toProxy != null) {
if (Util.isJdbcInterface(returnType)) {
Class<?> toProxyClass = toProxy.getClass();
return Proxy.newProxyInstance(toProxyClass.getClassLoader(), Util.getImplementedInterfaces(toProxyClass), getNewJdbcInterfaceProxy(toProxy));
}
}
return toProxy;
} 方法会调用Util#isJdbcInterface方法,检查返回值类型的类路径(本例是Statement对象),如果以
java.sql、javax.sql、com.mysql.jdbc为前缀的话,就对这个对象做动态代理。Proxy.newProxyInstance的第二、第三个方法需要留意下:
- Util#getImplementedInterfaces,故名思义,就是取出实例对象的实现的接口,包括它的父类。
- getNewJdbcInterfaceProxy方法被FailoverConnectionProxy所重载,所以会使用内部类FailoverJdbcInterfaceProxy对实例对象进行代理,它的父类JdbcInterfaceProxy实现了InvocationHandler接口。
所以,conn.createStatement()方法返回的Statement对象被FailoverJdbcInterfaceProxy动态代理。Statement对象的每个接口行为都会触发FailoverJdbcInterfaceProxy#invoke方法。这样做设计的目的,就是需要将Statement对象执行时出现的SQLException异常被捕获,然后执行MultiHostConnectionProxy#dealWithInvocationException方法。后面会讲述该方法的作用。
3.1.2 特殊情况
除了上述正常执行情况下,还存在一种情况,在执行Connection动态代理的接口方法时,会提前更换连接,然后再执行接口方法,我们把目光放在FailoverConnectionProxy#invokeMore方法:
@Override
public synchronized Object invokeMore(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
if (this.isClosed && !allowedOnClosedConnection(method)) {
if (this.autoReconnect && !this.closedExplicitly) {
this.currentHostIndex = NO_CONNECTION_INDEX; // Act as if this is the first connection but let it sync with the previous one.
pickNewConnection();
this.isClosed = false;
this.closedReason = null;
} else {
String reason = "No operations allowed after connection closed.";
if (this.closedReason != null) {
reason += (" " + this.closedReason);
}
throw SQLError.createSQLException(reason, SQLError.SQL_STATE_CONNECTION_NOT_OPEN, null /* no access to a interceptor here... */);
}
}
Object result = null;
try {
result = method.invoke(this.thisAsConnection, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
....
return result;
}在invokeMore方法体里,4个判定条件必须同时为真就会执行pickNewConnection方法,提前更换连接:
- this.isClose为真
- !allowedOnClosedConnection(method)为真
- this.autoReconnect
- !this.closedExplicitly
对于isClose属性,我们观察它被设置为true的地方是在MultiHostConnectionProxy#invoke方法里。
public synchronized Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
if (METHOD_CLOSE.equals(methodName)) {
doClose();
this.isClosed = true;
this.closedReason = "Connection explicitly closed.";
this.closedExplicitly = true;
return null;
}
if (METHOD_ABORT_INTERNAL.equals(methodName)) {
doAbortInternal();
this.currentConnection.abortInternal();
this.isClosed = true;
this.closedReason = "Connection explicitly closed.";
return null;
}
if (METHOD_ABORT.equals(methodName) && args.length == 1) {
doAbort((Executor) args[0]);
this.isClosed = true;
this.closedReason = "Connection explicitly closed.";
return null;
}
....
}调用方调用指定的方法时,isClosed属性就会被设置为true。对于被调用的方法整理如下:
| 常量 | 常量值 | 声明方法的接口 |
| METHOD_CLOSE | close | java.sql.Connection |
| METHOD_ABORT_INTERNAL | abortInternal | com.mysql.jdbc.Connection |
| METHOD_ABORT | abort | java.sql.Connection |
我们可以看到,这些方法被调用后,不仅isClose属性被设置为true,而且直接返回null。所以这里暗示出,在执行了这行方法之后,再调用其他的Connection接口方法时才进行前面的逻辑判定。比如:先执行conn.close()命令,然后再执行conn.createStatement()命令。
对于!allowedOnClosedConnection(method)为真的判断条件,其实是只要调用方不是调用连接以下方法就符合。现对于被调用的方法整理如下:
| 常量 | 常量值 | 声明方法的接口 |
| METHOD_GET_AUTO_COMMIT | getAutoCommit | java.sql.Connection |
| METHOD_GET_CATALOG | getCatalog | java.sql.Connection |
| METHOD_GET_TRANSACTION | getTransactionIsolation | java.sql.Connection |
| METHOD_GET_SESSION_MAX_ROWS | getSessionMaxRows | com.mysql.jdbc.Connection |
这些命令对应的数据已经在当前连接建立的时候,从Mysql获取到了,所以不需要实时地连接到Mysql获取。
对于autoReconnect,默认值为false,但用户可以在url上添加autoReconnect=true或者autoReconnectForPools=true选项来更新。
对于!this.closedExplicitly,我们首先观察closedExplicitly设置为ture的地方。对于被调用的方法整理如下:
| 常量 | 常量值 | 声明方法的接口 |
| METHOD_CLOSE | close | java.sql.Connection |
所以,只要调用方调用的不是连接的close方法,即可满足。
综上所述,只要调用方调用连接的abortInternal或者abort方法,并且在url上添加autoReconnect=true或者autoReconnectForPools=true选项,然后再调用比如createStatement方法 就会执行pinkNewConnection方法,更换连接。也就是说,此处提供给调用方主动提出更换连接的机会。
根据官网的描述,对于autoReconnect和autoReconnectForPools的期望挺大的:
Although not recommended, you can make the driver perform failovers without invalidating the active Statement or ResultSet instances by setting either the parameter autoReconnect or autoReconnectForPools to true. This allows the client to continue using the same object instances after a failover event, without taking any exceptional measures.
但在通过查询autoReconnect赋值的代码以及进一步分析连接的机制时,会发现这两个属性并不是决定继续使用同一个Statement或者ResultSet的因素。根本原因是使用了动态代理,从而使得调用方一直持有着动态代理的Statement和ResultSet对象。后继章节会有这些介绍。
3.2 异常处理
从官网的描述可以理解到,failover就是要解决出现底层连接异常时造成调用方当前操作崩掉的问题。我们从连接的构造阶段和连接的使用阶段进行探讨,并且每个阶段我们都尝试分析通讯异常和数据异常发生后分别会有什么不同的处理。
3.2.1 构造连接阶段
从FailoverConnectionProxy的构造函数开始跟踪调用链会来到FailoverConnectionProxy#pickNewConnection方法:
@Override
synchronized void pickNewConnection() throws SQLException {
if (this.isClosed && this.closedExplicitly) {
return;
}
if (!isConnected() || readyToFallBackToPrimaryHost()) {
try {
connectTo(this.primaryHostIndex);
} catch (SQLException e) {
resetAutoFallBackCounters();
failOver(this.primaryHostIndex);
}
} else {
failOver();
}
}因为在《Mysql Connector/J 源码分析(普通Connection)》一文里已经知道,通讯异常和数据异常都会统一被封装成SQLException。在构造FailoverConnectionProxy时出现通讯异常,那么此处会捕获该异常,然后执行failover的操作,这说明url的第一个ip:port组合未能够正常连上,需要尝试连接第二组组合;如果出现的是数据异常,比如用户名与密码错误,此处同样执行failover方法,难道同样的用户名与密码,在第二台服务器上就会成功?
private synchronized void failOver(int failedHostIdx) throws SQLException {
int prevHostIndex = this.currentHostIndex;
int nextHostIndex = nextHost(failedHostIdx, false);
int firstHostIndexTried = nextHostIndex;
SQLException lastExceptionCaught = null;
int attempts = 0;
boolean gotConnection = false;
boolean firstConnOrPassedByPrimaryHost = prevHostIndex == NO_CONNECTION_INDEX || isPrimaryHostIndex(prevHostIndex);
do {
try {
firstConnOrPassedByPrimaryHost = firstConnOrPassedByPrimaryHost || isPrimaryHostIndex(nextHostIndex);
connectTo(nextHostIndex);
if (firstConnOrPassedByPrimaryHost && connectedToSecondaryHost()) {
resetAutoFallBackCounters();
}
gotConnection = true;
} catch (SQLException e) {
lastExceptionCaught = e;
if (shouldExceptionTriggerConnectionSwitch(e)) {
int newNextHostIndex = nextHost(nextHostIndex, attempts > 0);
if (newNextHostIndex == firstHostIndexTried && newNextHostIndex == (newNextHostIndex = nextHost(nextHostIndex, true))) { // Full turn
attempts++;
try {
Thread.sleep(250);
} catch (InterruptedException ie) {
}
}
nextHostIndex = newNextHostIndex;
} else {
throw e;
}
}
} while (attempts < this.retriesAllDown && !gotConnection);
if (!gotConnection) {
throw lastExceptionCaught;
}
}该方法里有一个do while循环体,保持在循环体里运行的条件是:
- url里的ip:port集合清单执行的遍数未超过retriesAllDown值。整份清单执行一遍算一次,不管清单里有多少ip:port组合。但每一遍是否会尝试连接url里第一组的ip:port,还要看是否满足secondsBeforeRetryMaster和queriesBeforeRetryMaster设置的值。
- 还没建立起连接
假如清单历遍次数达到了retriesAllDown值,就不再尝试建立连接,将通讯异常向上抛。这时侯上层的pickNewConnection方法没有捕获异常的行为,所以该异常直达调用方。
在do while循环体里会计算好要建立连接的ip:port组合,然后根据ip和port建立Socket或者SSLSocket连接。因为failover解决的问题是遇到通讯异常时能够建立新的连接,但是底层的逻辑将通讯异常与数据异常都封装成SQLException,那么如何判断或者说在哪里判断这个异常就是通讯异常呢?这个判断在shouldExceptionTriggerConnectionSwitch方法里实现:
@Override
boolean shouldExceptionTriggerConnectionSwitch(Throwable t) {
if (!(t instanceof SQLException)) {
return false;
}
String sqlState = ((SQLException) t).getSQLState();
if (sqlState != null) {
if (sqlState.startsWith("08")) {
// connection error
return true;
}
}
// Always handle CommunicationsException
if (t instanceof CommunicationsException) {
return true;
}
return false;
}在该方法里,只要是CommunicationsException通讯异常就返回true。当该方法返回true后,do while循环体会尝试建立下一组ip:port组合的连接。但是如果该异常属于数据异常,比如用户名与密码错误了,这个方法就会返回false,那么上层的failover方法就会将异常往更上层pinkNewConnection方法抛,并且退出 do while循环体。
在构造连接阶段,如果遇到通讯异常,FailoverConnectionProxy会挨个尝试url里每个ip:port组合建立新的连接。在试过指定遍数后,如果仍未能成功建立连接,才向调用方抛出异常;如果遇到数据异常,比如用户名与密码错误,就会相对早地向调用方抛出异常。这里用“相对早”,而不是“马上”,是因为底层的ConnectionImpl抛出数据异常后被pickNewOne方法体捕获,然后调用failover方法,failover方法里尝试新的ip:port并捕获到异常后判断出它是数据异常,然后才往上抛,所以“用户名或密码错误”的问题是经过两次的尝试才抛给调用方。如果在pickNewOne方法体捕获到异常后,立即判断该异常类型,如果属于数据异常,然后直接将异常往上抛,则可免去一次连接了。
3.2.2 连接使用阶段
failover使用了动态代理技术,即执行任何一条指定接口的方法都会进入InvocationHandler接口实现类的invoke方法。在此处FailoverConnectionProxy的父类MultiHostConnectionProxy实现该接口并重载invoke方法,而方法体内最终会调用FailoverConnectionProxy的invokeMore方法:
@Override
public synchronized Object invokeMore(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
Object result = null;
try {
result = method.invoke(this.thisAsConnection, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
....
return result;
}(1)如果执行conn.setAutoCommit(false)命令时,出现了通讯异常或者数据异常,反射机制会抛出InvocationTargetException,在此处会进入MultiHostConnectionProxy#dealWithInvocationException方法:
void dealWithInvocationException(InvocationTargetException e) throws SQLException, Throwable, InvocationTargetException {
Throwable t = e.getTargetException();
if (t != null) {
if (this.lastExceptionDealtWith != t && shouldExceptionTriggerConnectionSwitch(t)) {
invalidateCurrentConnection();
pickNewConnection();
this.lastExceptionDealtWith = t;
}
throw t;
}
throw e;
}在该方法里我们又看到了shouldExceptionTriggerConnectionSwitch方法的调用。如果异常源于通讯异常,就会调用pickNewConnection方法,随后进入failover方法,该方法在“构造连接阶段”部分已经介绍过了,这里需要补充的是,如果此时failover抛出异常,那么invokeMore方法没有进一步捕获异常的操作,而父类MultiHostConnectionProxy#invoke方法里虽有捕获,但它做的事情是要不要对异常进行封装,最后依然是继续往上抛,所以异常会直接到调用方那:
public synchronized Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
try {
return invokeMore(proxy, method, args);
} catch (InvocationTargetException e) {
throw e.getCause() != null ? e.getCause() : e;
} catch (Exception e) {
// Check if the captured exception must be wrapped by an unchecked exception.
Class<?>[] declaredException = method.getExceptionTypes();
for (Class<?> declEx : declaredException) {
if (declEx.isAssignableFrom(e.getClass())) {
throw e;
}
}
throw new IllegalStateException(e.getMessage(), e);
}
}(2)如果执行conn.createStatement(),前文已讲述,返回的是经过FailoverJdbcInterfaceProxy代理的Statement对象。当执行Statement的接口方法时,会进入FailoverJdbcInterfaceProxy#invoke方法:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
boolean isExecute = methodName.startsWith("execute");
if (FailoverConnectionProxy.this.connectedToSecondaryHost() && isExecute) {
FailoverConnectionProxy.this.incrementQueriesIssuedSinceFailover();
}
Object result = super.invoke(proxy, method, args);
if (FailoverConnectionProxy.this.explicitlyAutoCommit && isExecute && readyToFallBackToPrimaryHost()) {
// Fall back to primary host at transaction boundary
fallBackToPrimaryIfAvailable();
}
return result;
}该方法会调用父类JdbcInterfaceProxy#invoke方法:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
if (METHOD_EQUALS.equals(method.getName())) {
// Let args[0] "unwrap" to its InvocationHandler if it is a proxy.
return args[0].equals(this);
}
synchronized (MultiHostConnectionProxy.this) {
Object result = null;
try {
result = method.invoke(this.invokeOn, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
return result;
}
}该方法与FailoverExceptionProxy的invokeMore处理类似。如果方法在执行过程中出现异常,就会以InvocationTargetException异常抛出,并在此处被捕获,然后执行MultiHostConnectionProxy#dealWithInvocationException方法:
void dealWithInvocationException(InvocationTargetException e) throws SQLException, Throwable, InvocationTargetException {
Throwable t = e.getTargetException();
if (t != null) {
if (this.lastExceptionDealtWith != t && shouldExceptionTriggerConnectionSwitch(t)) {
invalidateCurrentConnection();
pickNewConnection();
this.lastExceptionDealtWith = t;
}
throw t;
}
throw e;
}
abstract void pickNewConnection() throws SQLException;JdbcInterfaceProxy#invoke方法之所以能够直接调用MultiHostConnectionProxy#dealWithInvocationException方法,因为JdbcInterfaceProxy是MultiHostConnectionProxy的内部类。FailoverConnectionProxy、MultiHostConnectionProxy、FailoverJdbcInterfaceProxy、JdbcInterfaceProxy这几个类的设计还是挺有意思的。
在MultiHostConnectionProxy#dealWithInvocationException里,先判断InvocationTargetException被抛出的根本原因:
- 如果是由于通讯异常引起,那么就通过invalidateCurrentConnection方法关闭当前连接,然后调用pickNewConnection方法换一个连接。MultiHostConnectionProxy作为FailoverConnectionProxy的父类,它声明的pickNewConnection是虚方法,FailoverConnectionProxy重载了该方法,前文已对该方法的内容作过陈述,这里不展开说。在当前,MultiHostConnectionProxy的真实身份是FailoverConnectionProxy,所以MultiHostConnectionProxy#dealWithInvocationException调用的pickNewConnection方法会执行FailoverConnectionProxy#pickNewConnection方法。
- 如果是由于数据异常引起,就不作处理,异常会一直抛向调用方。
如果在pickNewConnection方法里又出现了异常,这时该项异常首先抛到JdbcInterfaceProxy#invoke方法,但此时已经没有进一步的捕获动作,所以异常会直接去到调用方。
假如MultiHostConnectionProxy#dealWithInvocationException里调用pickNewConnection方法能成功连上新的Mysql服务端,那么调用方持有的Statement对象可以继续使用,但它下次再执行SQL命令的时候,使用的是另一个连接对象了。
四、异常的影响
通过以上的分析,当异常发生后,FailoverExceptionProxy内部或者JdbcInterfaceProxy内部都有一个更换连接的机制,调用方持有的Connection动态代理对象或者Statement动态代理对象保持不变。根据我们的常识,如果遇到的是通讯异常,当前的事务必然结束,那么在成功更换连接的情况下,调用方能够感知到这种变化吗?
(1)FailoverExceptionProxy#invokeMore捕获InvocationTargetException后的处理:
@Override
public synchronized Object invokeMore(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
....
try {
result = method.invoke(this.thisAsConnection, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
if (METHOD_SET_AUTO_COMMIT.equals(methodName)) {
this.explicitlyAutoCommit = (Boolean) args[0];
}
if ((this.explicitlyAutoCommit || METHOD_COMMIT.equals(methodName) || METHOD_ROLLBACK.equals(methodName)) && readyToFallBackToPrimaryHost()) {
// Fall back to primary host at transaction boundary
fallBackToPrimaryIfAvailable();
}
return result;
}很明显,dealWithInvocationException命令成功执行后,返回的result一定为null值。如果此异常属于通讯异常,并且后续failover成功,这对于conn.setAutoCommit(false)是不利的,因为该接口定义的返回值为void,所以调用方不知道连接已经被更换了,并且新连接并没有执行setAutoCommit要做的操作;如果此异常属于通讯异常,MultiHostConnectionProxy#dealWithInvocationException方法会调用FailoverConnectionProxy#shouldExceptionTriggerConnectionSwitch方法,该方法判断出异常不是通讯异常,然后就把异常直接往调用方抛,所以调用方能马上感知到发生了业务异常。
(2)JdbcInterfaceProxy#invoke捕获InvocationTargetException后的处理
在实际运行中,是FailoverJdbcInterfaceProxy#invoke调用父类JdbcInterfaceProxy#invoke方法,父类有捕获异常的行为而FailoverJdbcInterfaceProxy没有。我们看看父类JdbcInterfaceProxy的捕获行为:
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
....
synchronized (MultiHostConnectionProxy.this) {
Object result = null;
try {
result = method.invoke(this.invokeOn, args);
result = proxyIfReturnTypeIsJdbcInterface(method.getReturnType(), result);
} catch (InvocationTargetException e) {
dealWithInvocationException(e);
}
return result;
}
}很明显,当异常为通讯异常时,如果dealWithInvocationException命令成功执行,返回的result一定为null值。对于ResultSet rs = stmt.executeQuery(sql)命令来说,可以判断rs变量是否为null值来判断是否发生了连接的更换;如果异常为数据异常,跟上一点描述的一样,调用方马上就感知得到。
综合以上论述,通讯异常的发生对于调用方来说不一定感知得到,对于事务类型的操作带来致命的危险,因为中途更换连接后,无法保证数据的一致性,后面关于failOverReadOnly选项会有更详细的介绍。
五、专有选项
failover模式有几个专有的选项,可添加到url,下面将从代码的角度来介绍它们的作用:
- retriesAllDown
如果当前的连接出现通讯异常会进入failover方法,它的作用是控制url里的ip:port组集合的被轮循的遍数。理论上整个ip:port组集合每个组合都试过一次算1次。但是第一组ip:port作为主服务器,是否尝试建立连接,还取决于secondsBeforeRetryMaster或者queriesBeforeRetryMaster这两个选项值。
- secondsBeforeRetryMaster和queriesBeforeRetryMaster
secondsBeforeRetryMaster是表示第一组ip:port对应的主服务器连不上后,要等待的毫秒数。queriesBeforeRetryMaster表示表示第一组ip:port对应的主服务器连不上后,隔了多少次SQL操作后才再尝试连接主服务器。
synchronized boolean readyToFallBackToPrimaryHost() {
return this.enableFallBackToPrimaryHost && connectedToSecondaryHost() && (secondsBeforeRetryPrimaryHostIsMet() || queriesBeforeRetryPrimaryHostIsMet());
}
//判断距离主服务器断开连接的时间长度
private synchronized boolean secondsBeforeRetryPrimaryHostIsMet() {
return this.secondsBeforeRetryPrimaryHost > 0 && Util.secondsSinceMillis(this.primaryHostFailTimeMillis) >= this.secondsBeforeRetryPrimaryHost;
}
//判断距离主服务器断开连接后执行的操作次数是否足够
private synchronized boolean queriesBeforeRetryPrimaryHostIsMet() {
return this.queriesBeforeRetryPrimaryHost > 0 && this.queriesIssuedSinceFailover >= this.queriesBeforeRetryPrimaryHost;
}在FailoverJdbcInterfaceProxy#invoke方法里对执行execute为前缀的方法进行queriesIssuedSinceFailover属性累加。根据上面代码块,它被用于与queriesBeforeRetryPrimaryHost进行比较:
@Override
public Object invoke(Object proxy, Method method, Object[] args) throws Throwable {
String methodName = method.getName();
boolean isExecute = methodName.startsWith("execute");
if (FailoverConnectionProxy.this.connectedToSecondaryHost() && isExecute) {
FailoverConnectionProxy.this.incrementQueriesIssuedSinceFailover();
}
Object result = super.invoke(proxy, method, args);
....
}
//FailoverConnectionProxy#incrementQueriesIssuedSinceFailover有个累加动作
synchronized void incrementQueriesIssuedSinceFailover() {
this.queriesIssuedSinceFailover++;
}- autoReconnect和autoReconnectForPools
Although not recommended, you can make the driver perform failovers without invalidating the active Statement or ResultSet instances by setting either the parameter autoReconnect or autoReconnectForPools to true. This allows the client to continue using the same object instances after a failover event, without taking any exceptional measures.
根据官网的描述,只要在url添加了这两选项之一的设置,就能够在通讯异常发生后,调用方不需要弃用原来的Statement和ResultSet。根据上文分析Statement和ResultSet(ResultSet的类路径属于被JdbcInterfaceProxy代理的范围)是动态代理对象,如果遇到连接异常,与之相关的连接会被更换。在这个过程中,未发现autoReconnect和autoReconnectForPools发挥作用的地方。而根据前文"特殊情况"的介绍,当调用方主动调用连接的abort接口方法,才会使用到这两变量。所以这里出现了官网介绍与代码实现不一致的地方。
- failOverReadOnly
官网的描述如下:
Sequence A, with failOverReadOnly=true:
-
Connects to primary host in read/write mode
-
Sets
Connection.setReadOnly(true); primary host now in read-only mode -
Failover event; connects to secondary host in read-only mode
-
Sets
Connection.setReadOnly(false); secondary host remains in read-only mode -
Falls back to primary host; connection now in read/write mode
Sequence B, with failOverReadOnly=false
-
Connects to primary host in read/write mode
-
Sets
Connection.setReadOnly(true); primary host now in read-only mode -
Failover event; connects to secondary host in read-only mode
-
Set
Connection.setReadOnly(false); connection to secondary host switches to read/write mode -
Falls back to primary host; connection now in read/write mode
核心意思就是url的第一对ip:port(主服务器的Mysql)默认具有读写能力,而其他服务器的Mysql只能是读操作。当在url添加failOverReadOnly=false选项,在主服务器连接异常而使用别的服务器的连接时,如果调用方执行 Connection.setReadOnly(false),后续就可以更新数据了。
根据上面官网的描述,如果设置failOverReadOnly=true,如果主服务器连接断开,并且成功failover另一台服务器,那么调用方的写操作就失败,这对于调用方来说是相当不友好的。如果使用failOverReadOnly=false,就高枕无忧吗?我们看看下面的例子:
比如执行以下命令:
- conn.setAutoCommit(false); --正常
- stmt = conn.createStatement(); --正常
- stmt.executeUpdate("insert into transfer (id, accoutno, amount ) values (1,'张三',200") --正常
- stmt.executeUpdate("insert into transfer (id, accoutno, amount ) values (2,'李四',-100") --发生通讯异常,并更换连接
- stmt.executeUpdate("insert into transfer (id, accoutno, amount ) values (3,'王五',-100") --正常
当执行给李四扣100元的时候,出现通讯异常,会导致张三收到200元的事务在Mysql端回滚,即张三账户不会增加200元,而李四这笔扣款因异常的发生也没有执行,执行王五的扣款时,因为是新连接,连接默认使用自动提交,所以王五会被扣除100元。
要避免这种情况的发生,必须检查每条stmt.executeUpdate命令的返回值,如果为0必须放弃后面的命令。如果调用方时刻都得防着这种情况的发生,需要写不少的判断代码,程序猿们必然会闹起来。
那么failover的价值在哪呢?对于failOverReadOnly=true模式下,我真想不出有什么场景比较适用;对于failOverReadOnly=false,可以用于比如读数据文件这种场景,而且还要从代码上确保当发生连接异常时当前的数据操作能够向新的连接再进行一遍。Java语言一般用于开发规模比较大的系统,里面的场景多且复杂,难免会有强调数据一致性的场景,所以个人感觉failover模式的应用并不会普遍。
总结
本文先从结构上分析Failover机制的结构,然后再分析failover的运行原理。分析运行原理中分别介绍了正常运行的过程,以及出现异常的处理。异常处理是我们最为看重的地方,所以这里花耗的笔墨最多。本文使用了两个“区分”来介绍异常处理,一个“区分”是区分了连接了构造阶段和使用阶段,另一个“区分“是在不同阶段里碰到通讯异常以及数据异常的不同处理方式。我们发现,在使用阶段,如果是数据异常,调用方能够马上感知得到;如果是通讯异常,要看被调用的接口是否有返回值,如果有可以通过返回结果猜测命令发送过程中出现了通讯异常,如果没有返回值就感知不到了。最后以代码的方式分析failover模式的专有选项,从而发现failover对于事务型的操作无法保证数据的一致性。从而推断failover模式的使用场景。总的来说,failover模式不太适用于场景复杂的应用,那么loadbalance以及replication模式又会如何呢?请继续关注后面文章。