从网上下载一本书籍来看,结果却是书籍页数几百页还没有目录,要想找到自己想看的部分还的自己徒手去翻,哇。。。。。这时心态就崩了,你识别是也遇到过这种情况。很多下载下来的pdf文档都是扫描版的,一般都没有目录,这样看起来就比较麻烦,所以就必须通过某些捷径办法来获得目录了。。。。。哎,由于我们能力有限无法支持原版,所以只能通过一些小手段了。。。。
利用python生成PDF文档目录
首先介绍一种适合程序员的方法,只需要有 python 编程环境即可,不需要安装第三方 PDF 软件。
事前准备:安装 python 第三方库 PyPDF2
首先安装 python 第三方库 PyPDF2:pip install PyPDF2
注意:原版 PyPDF2 在读取某些 PDF 时存在 bug,需要根据
https://github.com/mstamy2/PyPDF2/issues/368 中提到的方法对源代码进行简单的修改,即把${PYTHON_PATH}/site-packages/PyPDF2/pdf.py中的dest = Destination(NameObject("/"+title + " bookmark"), pageRef, NameObject(fit), *zoomArgs)
改成
dest = Destination(NullObject(), pageRef,NameObject(fit), *zoomArgs)
然后创建包含以下代码的脚本(假设命名为 PDFbookmark.py):
import re
import sys
from distutils.version import LooseVersion
from os.path import exists, splitext
from PyPDF2 import PdfFileReader, PdfFileWriter
is_python2 = LooseVersion(sys.version) < '3'
def _get_parent_bookmark(current_indent, history_indent, bookmarks):
assert len(history_indent) == len(bookmarks)
if current_indent == 0:
return None
for i in range(len(history_indent) - 1, -1, -1):
# len(history_indent) - 1 ===> 0
if history_indent[i] < current_indent:
return bookmarks[i]
return None
def addBookmark(pdf_path, bookmark_txt_path, page_offset):
if not exists(pdf_path):
return "Error: No such file: {}".format(pdf_path)
if not exists(bookmark_txt_path):
return "Error: No such file: {}".format(bookmark_txt_path)
with open(bookmark_txt_path, 'r', encoding='utf-8') as f:
bookmark_lines = f.readlines()
reader = PdfFileReader(pdf_path)
writer = PdfFileWriter()
writer.cloneDocumentFromReader(reader)
maxPages = reader.getNumPages()
bookmarks, history_indent = [], []
# decide the level of each bookmark according to the relative indent size in each line
# no indent: level 1
# small indent: level 2
# larger indent: level 3
# ...
for line in bookmark_lines:
line2 = re.split(r'\s+', unicode(line.strip(), 'utf-8')) if is_python2 else re.split(r'\s+', line.strip())
if len(line2) == 1:
continue
indent_size = len(line) - len(line.lstrip())
parent = _get_parent_bookmark(indent_size, history_indent, bookmarks)
history_indent.append(indent_size)
title, page = ' '.join(line2[:-1]), int(line2[-1]) - 1
if page + page_offset >= maxPages:
return "Error: page index out of range: %d >= %d" % (page + page_offset, maxPages)
new_bookmark = writer.addBookmark(title, page + page_offset, parent=parent)
bookmarks.append(new_bookmark)
out_path = splitext(pdf_path)[0] + '-new.pdf'
with open(out_path,'wb') as f:
writer.write(f)
return "The bookmarks have been added to %s" % out_path
if __name__ == "__main__":
import sys
args = sys.argv
if len(args) != 4:
print("Usage: %s [pdf] [bookmark_txt] [page_offset]" % args[0])
else:
print(addBookmark(args[1], args[2], int(args[3])))
补充:
上述代码中的 page_offset 一般设成 0 即可,它只会在特殊的情况下使用,即 PDF 自带的目录中页码和实际页码存在偏差(通常是一个固定的偏移)的情况,这时只需要将 page_offset 改成实际相应的偏差页数即可。
添加书签/目录
准备一个 txt 文本文件(假设命名为 toc.txt),在其中手动录入需要添加的目录,或者从文本型 PDF 中直接复制出目录,采用类似下面格式即可:
Introduction 14
I. Interview Questions 99
Data Structures 100
Chapter 1 | Arrays and Strings 100
Hash Tables 100
StringBuilder 101
Chapter 2 | Linked Lists 104
Creating a Linked List 104
The "Runner" Technique 105
Additional Review Problems 193
唯一的要求是每一行的最后一项是页码(前面的空白符个数不限),并且相同级别的书签要采用相同的缩进量(空格或 tab 都可以)。
【注意】如果是在 Windows 上创建 txt 文档的话,需要注意将文件保存为 UTF-8 编码格式,不然的话其中的汉字用第 ①步的脚本读取出来就是乱码了。(Windows 上直接创建的 txt 文档一般默认都是 ANSI 编码格式)
然后在第 ① 步中创建的 PDFbookmark.py 所在目录下打开终端/命令提示符,运行以下代码即可:
其中最后一个参数 9 表示将 toc.txt 文件中的页码全部偏移 +9(即全部加上 9)
python ./PDFbookmark.py '/Users/Emrys/Desktop/demo 2015.pdf' '/Users/Emrys/Desktop/toc.txt' 9
运行之后,会在要添加目录的 PDF 文件同目录下面生成一个新的 PDF 文件,名字为 [原 PDF 文件名]-new.pdf。 演示效果如下:

【补充】:可能存在的问题
问题一:ValueError: {’/Type’: ‘/Outlines’, ‘/Count’: 0} is not in list
如果上面脚本要处理的 PDF 文件之前被其他 PDF 编辑器软件修改过目录/书签的话,可能会导致类似下面的报错:
Traceback (most recent call last):
File ".\PDFbookmark.py", line 70, in <module>
print(addBookmark(args[1], args[2], int(args[3])))
File ".\PDFbookmark.py", line 55, in addBookmark
new_bookmark = writer.addBookmark(title, page + page_offset, parent=parent)
File "C:\Anaconda3\lib\site-packages\PyPDF2\pdf.py", line 732, in addBookmark
outlineRef = self.getOutlineRoot()
File "C:\Anaconda3\lib\site-packages\PyPDF2\pdf.py", line 607, in getOutlineRoot
idnum = self._objects.index(outline) + 1
ValueError: {
'/Type': '/Outlines', '/Count': 0} is not in list
这种情况下,需要把 PyPDF2 源码中 pdf.py 文件的 getOutlineRoot() 函数修改一下。
(源码文件路径是 ${PYTHON_PATH}/site-packages/PyPDF2/pdf.py):
def getOutlineRoot(self):
if '/Outlines' in self._root_object:
outline = self._root_object['/Outlines']
try:
idnum = self._objects.index(outline) + 1
except ValueError:
if not isinstance(outline, TreeObject):
def _walk(node):
node.__class__ = TreeObject
for child in node.children():
_walk(child)
_walk(outline)
outlineRef = self._addObject(outline)
self._addObject(outlineRef.getObject())
self._root_object[NameObject('/Outlines')] = outlineRef
idnum = self._objects.index(outline) + 1
outlineRef = IndirectObject(idnum, 0, self)
assert outlineRef.getObject() == outline
else:
outline = TreeObject()
outline.update({
})
outlineRef = self._addObject(outline)
self._root_object[NameObject('/Outlines')] = outlineRef
return outline
问题二:RuntimeError: generator raised StopIteration
如果你在做了上述修改之后,运行脚本时遇到了 RuntimeError: generator raised StopIteration 的错误,请检查一下是不是 Python 版本大于等于 3.7(因为从 v3.7 版本之后,Python 对终止迭代的方式处理发生了变化,详情可以参考 PEP 479),如果是的话,请尝试使用 v3.7 之前版本的 Python 来运行上面的代码。
Python 导出 PDF 中目录/书签
import sys
from distutils.version import LooseVersion
from os.path import exists
from PyPDF2 import PdfFileReader
is_python2 = LooseVersion(sys.version) < '3'
def _parse_outline_tree(outline_tree, level=0):
"""Return List[Tuple[level(int), page(int), title(str)]]"""
ret = []
for heading in outline_tree:
if isinstance(heading, list):
# contains sub-headings
ret.extend(_parse_outline_tree(heading, level=level+1))
else:
ret.append((level, heading.page.idnum, heading.title))
return ret
def extractBookmark(pdf_path, bookmark_txt_path):
if not exists(pdf_path):
return "Error: No such file: {}".format(pdf_path)
if exists(bookmark_txt_path):
print("Warning: Overwritting {}".format(bookmark_txt_path))
reader = PdfFileReader(pdf_path)
# List of ('Destination' objects) or ('Destination' object lists)
# [{'/Type': '/Fit', '/Title': u'heading', '/Page': IndirectObject(6, 0)}, ...]
outlines = reader.outlines
# List[Tuple[level(int), page(int), title(str)]]
outlines = _parse_outline_tree(outlines)
max_length = max(len(item[-1]) + 2 * item[0] for item in outlines) + 1
# print(outlines)
with open(bookmark_txt_path, 'w') as f:
for level, page, title in outlines:
level_space = ' ' * level
title_page_space = ' ' * (max_length - level * 2 - len(title))
if is_python2:
title = title.encode('utf-8')
f.write("{}{}{}{}\n".format(level_space, title, title_page_space, page))
return "The bookmarks have been exported to %s" % bookmark_txt_path
if __name__ == "__main__":
import sys
args = sys.argv
if len(args) != 3:
print("Usage: %s [pdf] [bookmark_txt]" % args[0])
else:
print(extractBookmark(args[1], args[2]))
以上代码来源【侵删】:
链接:https://www.zhihu.com/question/344805337/answer/1116258929
来源:知乎
FreePic2Pdf工具生成PDF文档目录
1. 软件下载
下载地址(https://pan.baidu.com/s/1kVHzVmf)密码:at9e
【注:该链接为VIP专属博文批量给pdf添加目录(最完整详细方法)提供,侵删】
软件面貌:
2. 将书籍的目录挂载到pdf步骤
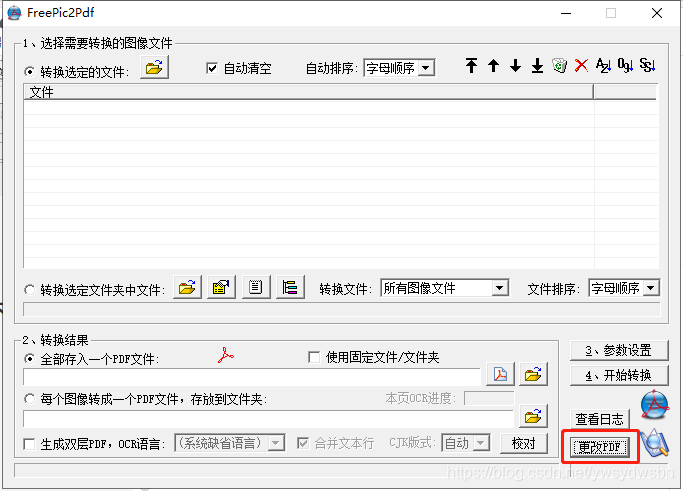
2.1 打开软件FreePic2PDF,点击右下角“更改pdf”
2.2 选择“从PDF取书签”→需要操作的pdf文件→点击开始
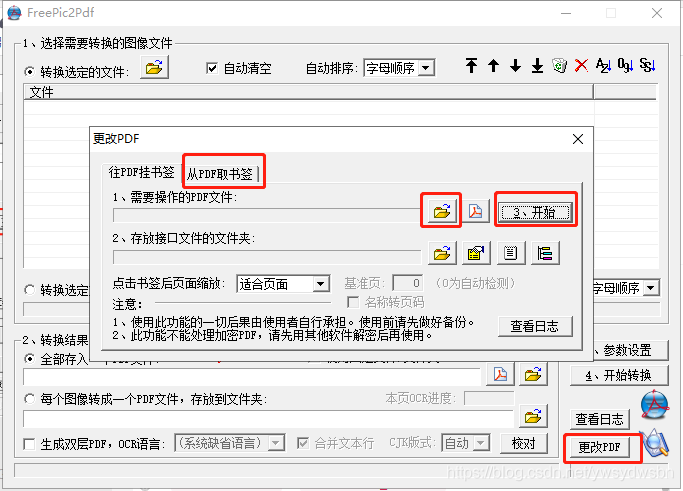
会在当前pdf文件相同目录下生成书签配置文件夹, 里面包含FreePic2Pdf.itf和 FreePic2Pdf_bkmk.txt文件
(*.txt文件会保存你pdf已经存在的书签信息,因为没书签,此时当然是空的或是一些不完整的书签信息)

2.3 复制PDF目录页面所有目录说明到文本编辑
接下来通过复制PDF目录页面所有目录说明到文本编辑 这里我用的是Notepad++这个编辑器。
格式一定要对,特别是页码和节标题之间是tab键,各级目录之间要正确!!!(这是最麻烦的一步,但是肯定比自己一个个搞书签快)如下:

把调整好格式的文本复制到刚才提取书签生成的FreePic2Pdf_bkmk.txt文件中。
2.4 将书签挂到pdf中
直接点击往pdf挂书签即可(此时应关闭该pdf文档),打开pdf再看看目录是否添加成功,没成功或是有些不对的地方,多半是txt文件的数据格式不一样,调整调整即可。
如下添加成功了,哈哈哈~~~~~~