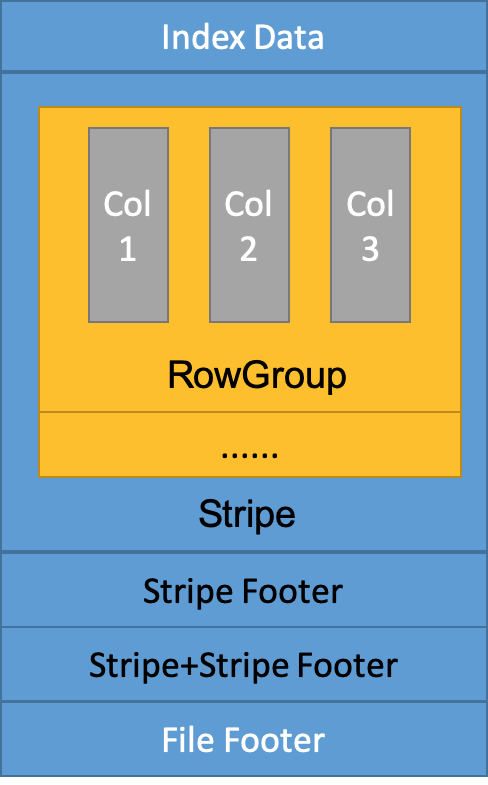
ORC 文件格式
ORC 文件分成多个 Stripe,Stripe 里又分为多个 RowGroup,每个 RowGroup 包含文件中的所有列的一部分数据,每个 RowGroup 默认有 10000 行元组。查询时只在 RowGroup 层做过滤,检查各个列中是否可能存在结果。十分粗粒度,不能保证读出来的每一行都满足条件。
ORC 读取流程
OrcFile.createReader() 时读取文件的 Footer 和 Metadata 信息,记录文件中的 Stripe,每个 Stripe 是包含所有列的一部分数据段。是 Orc 文件的最大的粒度。
-
创建一个 VectorizedRowBatch,这个东西主要负责存放查出来的数据。查询的schema里有几列,VectorizedRowBatch 中就有几列,每一列是原始数据类型的数组,默认长度 1024。
-
创建 RecordReaderImpl 对象,用来读数据,同时构造过滤器 SargApplier,创造 DataReader。
-
读取第一行满足要求的数据。RecordReaderImpl.advanceToNextRow(),读第一个 Stripe
-
读 Stripe 的流程: RecordReaderImpl.beginReadStripe()
- 读 StripeInformation,包括 Stripe Footer
- 对 Stripe 内的每一个 RowGroup 进行过滤: RecordReaderImpl.pickRowGroups(),生成一个 includedRowGroups。根据这个东西构造出需要读的数据的位置,并且把涉及到的数据的原始字节数组都读出来。
-
填充 batch: TreeReaderFactory.nextBatch()
- 最后还是要根据读出来的 RowGroup 填充 batch,batch是原始数据类型的数组,没有封装,很高效。
小坑
如果一个 batch 有两列,第一列是递增的1-100,第二列也是递增的1-100,查询过滤条件 第一列 < 50 and 第二列 > 60,这个 batch 也会读出来。