移动互联网打破了传统门户网站的交流屏障,社交软件则架起了信息之间无障碍沟通的桥梁。
根据《2019年社交行业研究报告》显示,目前市面上的社交软件一共有6000多个,包括内容社交、工具社交、场景社交三个方面。
现今,社交软件不仅仅是普通的交友软件,它本质上是一种传递信息的媒介,并具有极大的包容性、复杂性、广泛性。成千上万个社交软件散布在网络世界的各个角落,它所带来的改变足以带动整个互联网时代信息交流的变迁。
它容许并鼓励全球不同地域的用户注册登录,每一位用户都可以自由发言尽情创作,以信息分享为核心,进行个性交流、评论转发、在线直播、扩列交友、知识创作等操作,所以它是数字化信息传播的重要落地典范。但是这把双刃剑,同时也存在着很多令人头疼的安全风控隐患。
社交行业挑战升级
伴随着产业互联网数字化的不断推进,社交软件的容错性也越来越低。
以信息传播为载体的6000+社交软件在分类上成树状图分布。主要以知识性内容社交分享(知乎、CSDN、微博、抖音、快手等)、即时通讯社交聊天(微信、探探、陌陌等)、各行业垂直场景社交交流(脉脉、马蜂窝等)三类为主。

面对这些多场景多渠道社交形式,显而易见,有交流的地方一定会有文本内容,并且在某些社交平台上,却存在一些共性风控问题。如频繁出现暴恐、涉政、低俗、辱骂等违法违规内容,以及发布黑产广告导流等违规信息,这不仅违反了网络安全的和谐秩序,也对用户造成了恶劣的观感体验,造成正常用户流失。
从根本原因上去剖析,除了小部分原因是用户自身的行为违规,大部分原因是由于一些黑产分子将社交软件看成了自己的“吸金池”。且作案手法层出不穷:游戏点金、杀猪盘、恶意营销薅羊毛、黄牛倒卖机票火车票演唱会门票…
在国家监管部门的指导下,社交平台也采取了一系列处罚措施。
2020年8月,微博管理方关闭了109个黑产导流账号;斗鱼关停违规直播间525个、封禁账号571个;武汉市指导某直播平台依法依规关闭违规直播间525个,封禁违规用户账号571个,清理标题党136个。
截止2020年9月,全国网信系统同电信部门处罚违法网站6907家,有关网站平台依法关闭各类违法违规群组86万余个…因此,国家对社交软件的内容监管要求也越来越严。
各类社交平台违规内容的不断频发,黑产团伙花样百出的作案手法,使得内容审核挑战的不断升级,给社交软件带来很大的生存压力。
黑产攻防之战愈演愈烈,针对如何解决此类问题,数美人工智能研究院结合行业背景,对智能文本识别技术进行了深入研究和开发,通过自研天净智能内容过滤引擎来应对挑战。
社交软件内容精准过滤器:数美智能文本审核
数美人工智能研究院发现,社交软件的文本审核主要聚焦在直播视频弹幕、论坛灌水发帖、产品评论留言、头像昵称签名、垃圾广告群发、游戏频道聊天六大方面。
对于不同的应用场景,就对智能文本的语义识别精准度、识别范围广泛性、多语种识别等方面要求极高。对此,数美科技智能文本过滤通过建立完善用户画像系统和特色智能语义分析功能,结合多场景、多维度判定,支持涉政违禁、低俗污秽、广告导流风险识别。

针对不同的社交场景,数美智能文本过滤采用语义分析技术和多种文本识别模型和策略、以及文本处理技术,包括采用基于敏感词库的名单服务。基于深度学习的NLP模型,用户画像的行为分析,实时分布式规则引擎、统计引擎等,对海量文本数据进行学习和训练,能够精准识别语义并进行风险判断。
涉政违规识别
实时同步网安、网信办等有关部门监管要求,持续更新数十万量级的敏感词库,通过灵活的名单匹配
(白名单、黑名单、忽略名单、变体名单等)和智能NLP模型,精准有效识别文本中的涉政违规风险。
包括领导人名、敏感事件、禁书禁片、邪教迷信、政府机构、反动分裂、违禁品、暴力恐怖、英雄烈士、热点事件等,并支持业务场景的敏感词个性化设置、变体识别(同音字、形近字、拼音、插入混淆、影射等)及多种灵活匹配方式。
低俗违规识别
通过积累大量行业语料,基于NLP技术训练低俗和辱骂等模型,结合低俗敏感词库,精准识别文本中不合规的低俗污秽等内容。并将该内容分为多个等级,灵活适应不同应用、场景、角色的个性化审核标准。
智能NLP模型和色情敏感词相结合,多角度全方位进行拦截,且支持自定义敏感词名单。并利用智能语义识别技术,对同一个词在不同语境中产生对应的判别结果。
广告导流识别
主要针对广告导流黑产团伙在社交软件中发布的大量垃圾广告、诈骗广告,利用智能文字变体识别能力,可以精准识别欺诈广告、导流广告,支持广告法合规性检查,减少违规风险,上万种主流联系方式(微信、QQ、手机号、网址、公众号、百度搜索、微博、广告法合规等)变体特征库。
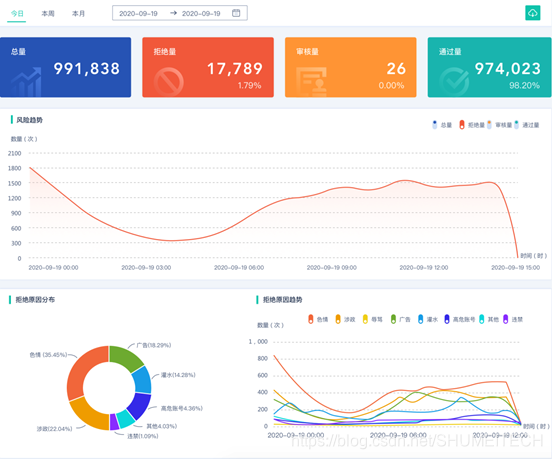
汉语文化博大精深,同一个词在不同语境中意义差别极大,传统敏感词匹配技术的准确率很难达到精准高效审核的要求。数美智能文本过滤识别准确率高达99%以上,可对文本进行快速处理,极大降低误杀率,并减少人工审核成本,有效杜绝线上风险。
在技术指标上,数美智能文本过滤API平均响应时间低于50ms,最大响应时间500ms,超时率低于0.1%,吞吐大于100QPS,还可根据需求水平扩展。并可支持UTF8多语言文本字符编码,文本内容限制为不超过1MB、2万字。
数美核心技术优势:文本分类NLP模型
数美智能文本过滤采用了word2vec词向量、fasttext文本分类等技术,基于海量文本语料训练NLP模型。
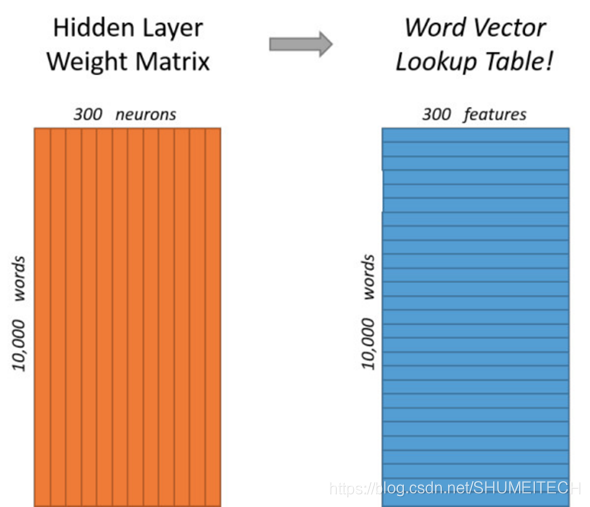
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。它通过学习文本来用词向量的方式表征词的语义信息,即通过一个嵌入空间使得语义上相似的单词在该空间内距离很近。
Embedding其实就是一个映射,将单词从原先所属的空间映射到新的多维空间中,也就是把原先词所在空间嵌入到一个新的空间中去。
其中,在Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。

fastText资料库,能针对文本表达和分类帮助建立量化的解决方案,fastText结合了自然语言处理和机器学习中最成功的理念。这些包括了使用词袋以及n-gram 袋表征语句,还有使用子字(subword)信息,并通过隐藏表征在类别间共享信息。
另外,数美人工智能研究院采用了一个softmax层级(利用了类别不均衡分布的优势)来加速运算过程。这些不同概念被用于两个不同任务:有效文本分类和学习词向量表征。在文本处理领域中深度神经网络近来大受欢迎,但是它们训练以及测试过程十分缓慢,这也限制了它们在大数据集上的应用,fastText却能够直接解决这个问题。
fastText 专注于文本分类。这使得在特别大型的数据集上,它能够被快速训练。使用一个标准多核 CPU,就得到了在10分钟内训练完超过10亿词汇量模型的结果。此外,fastText还能在五分钟内将50万个句子分成超过30万个类别。
数美人工智能研究院长期深耕在智能文本识别NLP模型训练和开发中,不断和黑产欺诈团伙抗争,并从内容、行为、画像多维度协同AI,精准有效识别违规内容,形成了一站式智能风控引擎。数美科技作为一家专业从事AI风控解决方案提供商,也会持续为全球千家社交行业客户在线业务保驾护航。