一. 前言
上文我们分析了字符设备,本文接着分析块设备。我们首先分析块设备的基本结构体,然后分析块设备生成、加载的整个过程,最后分析块设备的直接I/O访问和缓存I/O访问。
二. 块设备基本结构体
上文中我们分析了字符设备驱动程序的抽象结构体cdev和管理cdev的结构体cdev_map,在块设备中会相对复杂一些,因为涉及到一个概念:伪文件系统bdevfs。在此之下主要有三个结构体:对块设备或设备分区的抽象结构体block_device,对磁盘的通用描述gendisk以及磁盘分区描述hd_struct。其中block_device和hd_struct一一互相关联,而gendisk统一管理众多hd_struct。当虚拟文件系统需要使用该块设备时,则会利用block_device去gendisk中寻找对应的hd_struct从而实现读写等访问操作。除了这三个结构体以外,同字符设备驱动一样,块设备也有对gendisk的管理结构体bdev_map,同样是kobj_map结构体。
这里首先说明一下伪文件系统。在前文中我们已经分析了文件系统,而文件系统的精髓所在是让用户可以通过文件描述符来对指定的inode进行一系列的操作。伪文件系统和普通文件系统的区别在于,其inode对用户不可访问,即仅在内核态可见,从用户层的视角来看该文件系统并不存在。伪文件系统的作用是对一些操作系统中的元素进行封装,和普通的文件统一接口,如块设备bdevfs,管道文件pipefs,套接字socketfs等。通过这种方式的统一封装,才实现了Linux一切皆文件的思想。
bdevfs对应的超级块名为blockdev_superblock,初始化工作在系统初始化时调用bdev_cache_init()完成。所有表示块设备的 inode 都保存在伪文件系统 bdevfs 中以方便块设备的管理。Linux 将块设备的 block_device 和 bdev 文件系统的块设备的 inode通过 struct bdev_inode 进行关联。
struct super_block *blockdev_superblock __read_mostly;
static struct file_system_type bd_type = {
.name = "bdev",
.mount = bd_mount,
.kill_sb = kill_anon_super,
};
void __init bdev_cache_init(void)
{
int err;
static struct vfsmount *bd_mnt;
bdev_cachep = kmem_cache_create("bdev_cache", sizeof(struct bdev_inode),
0, (SLAB_HWCACHE_ALIGN|SLAB_RECLAIM_ACCOUNT|
SLAB_MEM_SPREAD|SLAB_ACCOUNT|SLAB_PANIC),
init_once);
err = register_filesystem(&bd_type);
if (err)
panic("Cannot register bdev pseudo-fs");
bd_mnt = kern_mount(&bd_type);
if (IS_ERR(bd_mnt))
panic("Cannot create bdev pseudo-fs");
blockdev_superblock = bd_mnt->mnt_sb; /* For writeback */
}
struct bdev_inode {
struct block_device bdev;
struct inode vfs_inode;
};
下面先看看block_device结构体,其实和char_device有很多相似之处,如设备号bd_dev,打开用户数统计bd_openers等,从这里可以看到块设备的抽象结构体会直接和超级块以及对应的特殊inode关联,而且和hd_struct一一关联。其中bd_disk指向对应的磁盘gendisk,需要使用时通过hd_struct获取对应的磁盘分区信息并使用,请求队列bd_queue会传递给gendisk。
struct block_device {
dev_t bd_dev; /* not a kdev_t - it's a search key */
int bd_openers;
struct inode * bd_inode; /* will die */
struct super_block * bd_super;
......
struct block_device * bd_contains;
unsigned bd_block_size;
u8 bd_partno;
struct hd_struct * bd_part;
/* number of times partitions within this device have been opened. */
unsigned bd_part_count;
int bd_invalidated;
struct gendisk * bd_disk;
struct request_queue * bd_queue;
struct backing_dev_info *bd_bdi;
struct list_head bd_list;
......
} __randomize_layout;
gendisk代表通用磁盘抽象,major 是主设备号,first_minor 表示第一个分区的从设备号,minors 表示分区的数目。disk_name 给出了磁盘块设备的名称。struct disk_part_tbl 结构里是一个 struct hd_struct 的数组,用于表示各个分区。struct block_device_operations fops 指向对于这个块设备的各种操作。struct request_queue queue 表示在这个块设备上的请求队列。所有的块设备,不仅仅是硬盘 disk,都会用一个 gendisk 来表示,然后通过调用链 add_disk()->device_add_disk()->blk_register_region(),将 dev_t 和一个 gendisk 关联起来并保存在 bdev_map 中。
struct gendisk {
/* major, first_minor and minors are input parameters only,
* don't use directly. Use disk_devt() and disk_max_parts().
*/
int major; /* major number of driver */
int first_minor;
int minors; /* maximum number of minors, =1 for
* disks that can't be partitioned. */
char disk_name[DISK_NAME_LEN]; /* name of major driver */
char *(*devnode)(struct gendisk *gd, umode_t *mode);
......
struct disk_part_tbl __rcu *part_tbl;
struct hd_struct part0;
const struct block_device_operations *fops;
struct request_queue *queue;
void *private_data;
int flags;
struct rw_semaphore lookup_sem;
struct kobject *slave_dir;
......
};
static struct kobj_map *bdev_map;
static inline void add_disk(struct gendisk *disk)
{
device_add_disk(NULL, disk);
}
/**
* device_add_disk - add partitioning information to kernel list
* @parent: parent device for the disk
* @disk: per-device partitioning information
*
* This function registers the partitioning information in @disk
* with the kernel.
*/
void device_add_disk(struct device *parent, struct gendisk *disk)
{
......
blk_register_region(disk_devt(disk), disk->minors, NULL,
exact_match, exact_lock, disk);
.....
}
/*
* Register device numbers dev..(dev+range-1)
* range must be nonzero
* The hash chain is sorted on range, so that subranges can override.
*/
void blk_register_region(dev_t devt, unsigned long range, struct module *module,
struct kobject *(*probe)(dev_t, int *, void *),
int (*lock)(dev_t, void *), void *data)
{
kobj_map(bdev_map, devt, range, module, probe, lock, data);
}
struct hd_struct 表示磁盘的某个分区。在 hd_struct 中,比较重要的成员变量保存了如下的信息:从磁盘的哪个扇区开始,到哪个扇区结束,磁盘分区信息,引用数等。
struct hd_struct {
sector_t start_sect;
/*
* nr_sects is protected by sequence counter. One might extend a
* partition while IO is happening to it and update of nr_sects
* can be non-atomic on 32bit machines with 64bit sector_t.
*/
sector_t nr_sects;
......
struct device __dev;
struct kobject *holder_dir;
int policy, partno;
struct partition_meta_info *info;
......
struct disk_stats __percpu *dkstats;
......
struct percpu_ref ref;
struct rcu_work rcu_work;
};
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1DCaqGqt-1598018998535)(https://static001.geekbang.org/resource/image/85/76/85f4d83e7ebf2aadf7ffcd5fd393b176.png)]
理清了块设备中的关键结构体之间的关系后,我们按照和字符设备一样的顺序来分析块设备的工作原理和工作流程,首先分析块设备的挂载,接着分析块设备的打开,最后分析块设备的操作,包括直接I/O访问和带缓存的I/O访问。
三. 块设备队列结构
在上节中我们提到了block_device中的成员变量struct request_queue *bd_queue会传递给gendisk,该请求队列用于接收并处理来自用户发起的I/O请求。在每个块设备的驱动程序初始化的时候会生成一个 request_queue。这里会以一个列表的方式存储众多的结构体request,每一个request对应一个请求。这里还有两个重要的函数,一个是 make_request_fn() 函数,用于生成 request;另一个是 request_fn() 函数,用于处理 request。
struct request_queue {
/*
* Together with queue_head for cacheline sharing
*/
struct list_head queue_head;
struct request *last_merge;
struct elevator_queue *elevator;
......
request_fn_proc *request_fn;
make_request_fn *make_request_fn;
......
}
struct request {
struct list_head queuelist;
......
struct request_queue *q;
......
struct bio *bio;
struct bio *biotail;
......
}
在request结构体中最重要的是bio结构体,在 bio 中bi_next 是链表中的下一项,struct bio_vec 指向一组页面。
struct bio {
struct bio *bi_next; /* request queue link */
struct block_device *bi_bdev;
blk_status_t bi_status;
......
struct bvec_iter bi_iter;
unsigned short bi_vcnt; /* how many bio_vec's */
unsigned short bi_max_vecs; /* max bvl_vecs we can hold */
atomic_t __bi_cnt; /* pin count */
struct bio_vec *bi_io_vec; /* the actual vec list */
......
};
struct bio_vec {
struct page *bv_page;
unsigned int bv_len;
unsigned int bv_offset;
}
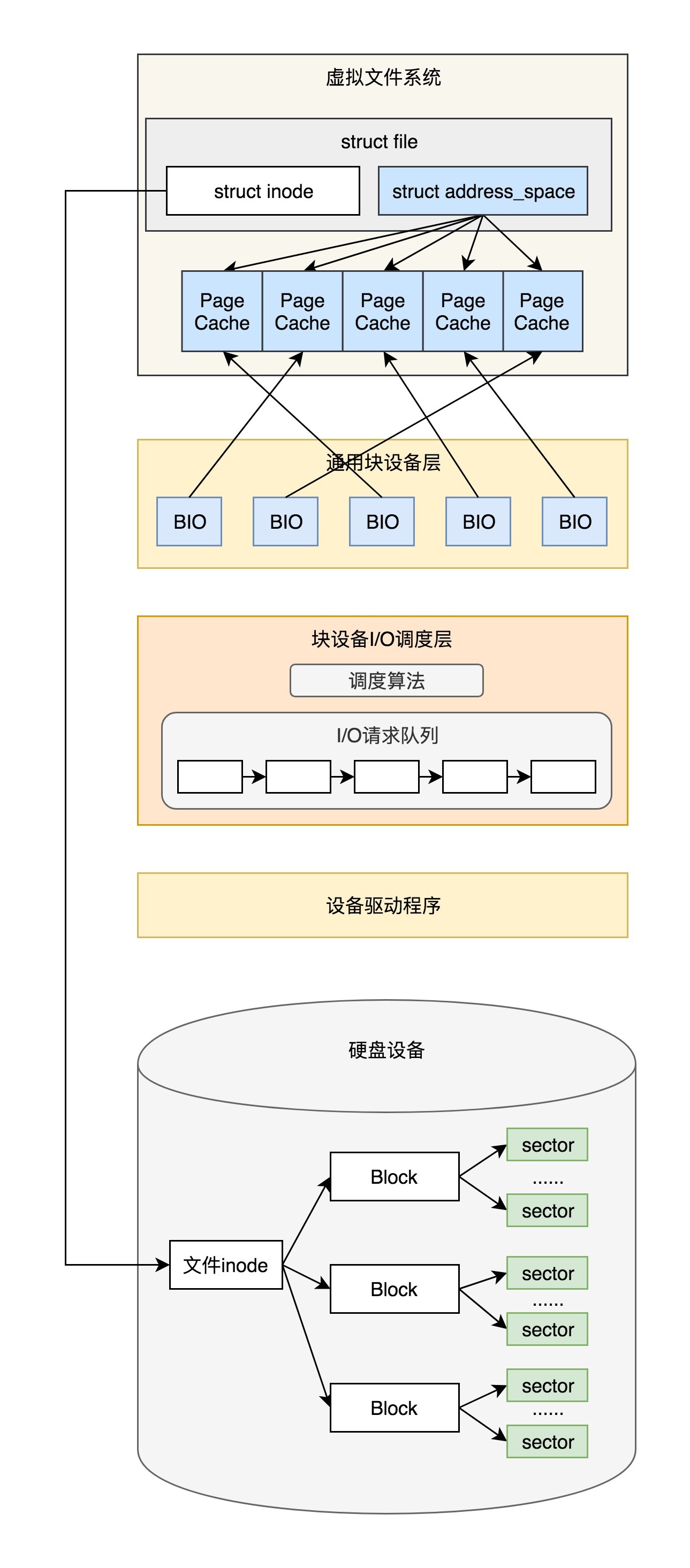
四. 请求队列的初始化
以 scsi 驱动为例。在初始化设备驱动的时候,会调用 scsi_alloc_queue(),把 request_fn() 设置为 scsi_request_fn()。同时还会调用 blk_init_allocated_queue()->blk_queue_make_request(),把 make_request_fn() 设置为 blk_queue_bio()。
/**
* scsi_alloc_sdev - allocate and setup a scsi_Device
* @starget: which target to allocate a &scsi_device for
* @lun: which lun
* @hostdata: usually NULL and set by ->slave_alloc instead
*
* Description:
* Allocate, initialize for io, and return a pointer to a scsi_Device.
* Stores the @shost, @channel, @id, and @lun in the scsi_Device, and
* adds scsi_Device to the appropriate list.
*
* Return value:
* scsi_Device pointer, or NULL on failure.
**/
static struct scsi_device *scsi_alloc_sdev(struct scsi_target *starget,
u64 lun, void *hostdata)
{
struct scsi_device *sdev;
sdev = kzalloc(sizeof(*sdev) + shost->transportt->device_size,
GFP_ATOMIC);
......
sdev->request_queue = scsi_alloc_queue(sdev);
......
}
struct request_queue *scsi_alloc_queue(struct scsi_device *sdev)
{
struct Scsi_Host *shost = sdev->host;
struct request_queue *q;
q = blk_alloc_queue_node(GFP_KERNEL, NUMA_NO_NODE);
if (!q)
return NULL;
q->cmd_size = sizeof(struct scsi_cmnd) + shost->hostt->cmd_size;
q->rq_alloc_data = shost;
q->request_fn = scsi_request_fn;
q->init_rq_fn = scsi_init_rq;
q->exit_rq_fn = scsi_exit_rq;
q->initialize_rq_fn = scsi_initialize_rq;
//调用blk_queue_make_request(q, blk_queue_bio);
if (blk_init_allocated_queue(q) < 0) {
blk_cleanup_queue(q);
return NULL;
}
__scsi_init_queue(shost, q);
......
return q
}
在 blk_init_allocated_queue() 中,除了初始化 make_request_fn() 函数,还要做一件很重要的事情,就是初始化 I/O 的电梯算法。
int blk_init_allocated_queue(struct request_queue *q)
{
q->fq = blk_alloc_flush_queue(q, NUMA_NO_NODE, q->cmd_size);
......
blk_queue_make_request(q, blk_queue_bio);
......
/* init elevator */
if (elevator_init(q, NULL)) {
......
}
......
}
电梯算法类型对应的结构体struct elevator_type为主要有以下几类:
elevator_noop:Noop 调度算法是最简单的 IO 调度算法,它将 IO 请求放入到一个 FIFO 队列中,然后逐个执行这些 IO 请求。iosched_deadline:Deadline 算法要保证每个 IO 请求在一定的时间内一定要被服务到,以此来避免某个请求饥饿。为了完成这个目标,算法中引入了两类队列,一类队列通过红黑树对请求按起始扇区序号进行排序,称为sort_list,按照此队列传输性能会比较高;另一类队列对请求按它们的生成时间进行排序,由链表来组织,称为fifo_list,并且每一个请求都有一个期限值。iosched_cfq:熟悉的 CFQ 完全公平调度算法。所有的请求会在多个队列中排序。同一个进程的请求,总是在同一队列中处理。时间片会分配到每个队列,通过轮询算法,我们保证了 I/O 带宽,以公平的方式,在不同队列之间进行共享。
elevator_init() 中会根据名称来指定电梯算法,如果没有选择,那就默认使用 iosched_cfq。
五. 块设备的挂载
块设备需要通过挂载才能在合适的位置被用户访问操控,挂载逻辑可以简单的如下描述:
- 挂载到
/dev的devtmpfs文件系统,对应操作为def_blk_fops,但是通常并不适用 - 挂载到某文件夹下(如home),以供用户真正的使用该块设备:
- 根据
/dev/xxx名字找到该块设备block_device并打开:找到在devtmpfs文件系统中的对应dentry和inode,并由此找到block_device- 查找函数为
lookup_bdev(),找到inode后调用bd_acquire()去获取block_device() bd_acquire()->bdget(),使用inode的i_rdev,即设备号进行查找- 该查找过程实际在伪文件系统
bdevfs:blockdev_superblock中进行,i_rdev会对应bdevfs中的一个bdev_inode,并由此获取到block_device
- 查找函数为
- 根据打开的设备填充
ext4的超级块,并以此为基础建立整套文件系统ext4fs
- 根据
下面具体分析每一步过程。块设备和字符设备一样通过mknod加载ko文件并挂载在/dev目录下的文件系统devtmpfs中。我们会为这个块设备文件分配一个特殊的 inode,这一点和字符设备也是一样的。只不过字符设备走 S_ISCHR 这个分支,对应 inode 的 file_operations 是 def_chr_fops;而块设备走 S_ISBLK 这个分支,对应的 inode 的 file_operations 是 def_blk_fops。这里要注意,inode 里面的 i_rdev 被设置成了块设备的设备号 dev_t。
void init_special_inode(struct inode *inode, umode_t mode, dev_t rdev)
{
inode->i_mode = mode;
if (S_ISCHR(mode)) {
inode->i_fop = &def_chr_fops;
inode->i_rdev = rdev;
} else if (S_ISBLK(mode)) {
inode->i_fop = &def_blk_fops;
inode->i_rdev = rdev;
} else if (S_ISFIFO(mode))
inode->i_fop = &pipefifo_fops;
else if (S_ISSOCK(mode))
; /* leave it no_open_fops */
}
挂载到某个文件夹下同样采用mount系统调用,实际会调用文件系统对应的挂载函数,如ext4的挂载函数ext4_mount()。这里的blkdev_get_by_path()最终实现了block_device的查找,而sget()完成文件系统超级块的填充。
static struct dentry *ext4_mount(struct file_system_type *fs_type, int flags,
const char *dev_name, void *data)
{
return mount_bdev(fs_type, flags, dev_name, data, ext4_fill_super);
}
struct dentry *mount_bdev(struct file_system_type *fs_type,
int flags, const char *dev_name, void *data,
int (*fill_super)(struct super_block *, void *, int))
{
struct block_device *bdev;
struct super_block *s;
fmode_t mode = FMODE_READ | FMODE_EXCL;
int error = 0;
if (!(flags & SB_RDONLY))
mode |= FMODE_WRITE;
bdev = blkdev_get_by_path(dev_name, mode, fs_type);
......
s = sget(fs_type, test_bdev_super, set_bdev_super, flags | SB_NOSEC,
bdev);
......
return dget(s->s_root);
......
}
EXPORT_SYMBOL(mount_bdev);
blkdev_get_by_path()实际调用lookup_bdev()根据设备路径 /dev/xxx 得到 block_device,接着调用 blkdev_get()打开该设备。
struct block_device *blkdev_get_by_path(const char *path, fmode_t mode,
void *holder)
{
struct block_device *bdev;
int err;
bdev = lookup_bdev(path);
......
err = blkdev_get(bdev, mode, holder);
......
if ((mode & FMODE_WRITE) && bdev_read_only(bdev)) {
blkdev_put(bdev, mode);
return ERR_PTR(-EACCES);
}
return bdev;
}
lookup_bdev() 这里的 pathname 是设备的文件名,例如 /dev/xxx。这个文件是在 devtmpfs 文件系统中的,kern_path() 可以在这个文件系统里面,一直找到它对应的 dentry。接下来,d_backing_inode() 会获得 inode。这个 inode 就是那个 init_special_inode 生成的特殊 inode,接下来bd_acquire() 通过这个特殊的 inode找到 struct block_device。
struct block_device *lookup_bdev(const char *pathname)
{
struct block_device *bdev;
struct inode *inode;
struct path path;
......
error = kern_path(pathname, LOOKUP_FOLLOW, &path);
......
inode = d_backing_inode(path.dentry);
......
bdev = bd_acquire(inode);
......
}
bd_acquire()最主要的就是调用 bdget()函数,根据特殊inode的设备号i_rdev去进行查找工作。
static struct block_device *bd_acquire(struct inode *inode)
{
struct block_device *bdev;
......
bdev = bdget(inode->i_rdev);
if (bdev) {
spin_lock(&bdev_lock);
if (!inode->i_bdev) {
/*
* We take an additional reference to bd_inode,
* and it's released in clear_inode() of inode.
* So, we can access it via ->i_mapping always
* without igrab().
*/
bdgrab(bdev);
inode->i_bdev = bdev;
inode->i_mapping = bdev->bd_inode->i_mapping;
}
spin_unlock(&bdev_lock);
}
return bdev;
}
bdget()函数根据设备号dev在伪文件系统bdev中查找对应的block_device,这里使用的是BDEV_I(),实际上也是常见的container_of()。
struct block_device *bdget(dev_t dev)
{
struct block_device *bdev;
struct inode *inode;
inode = iget5_locked(blockdev_superblock, hash(dev),
bdev_test, bdev_set, &dev);
if (!inode)
return NULL;
bdev = &BDEV_I(inode)->bdev;
if (inode->i_state & I_NEW) {
bdev->bd_contains = NULL;
bdev->bd_super = NULL;
bdev->bd_inode = inode;
bdev->bd_block_size = i_blocksize(inode);
bdev->bd_part_count = 0;
bdev->bd_invalidated = 0;
inode->i_mode = S_IFBLK;
inode->i_rdev = dev;
inode->i_bdev = bdev;
inode->i_data.a_ops = &def_blk_aops;
mapping_set_gfp_mask(&inode->i_data, GFP_USER);
spin_lock(&bdev_lock);
list_add(&bdev->bd_list, &all_bdevs);
spin_unlock(&bdev_lock);
unlock_new_inode(inode);
}
return bdev;
}
成功找到了对应的block_device后,下一步则是调用 blkdev_get()打开该设备,该函数实际调用__blkdev_get()打开设备。该部分逻辑大致归纳如下:
- 调用
get_gendisk(),根据block_device获取gendisk - 根据获取到的
partno- 如果
partno为0,则说明打开的是整个设备而不是分区,那我们就调用disk_get_part()获取gendisk中的分区数组,然后调用block_device_operations里面的open()函数打开设备。 - 如果
partno不为 0,也就是说打开的是分区,那我们就调用bdget_disk()获取整个设备的block_device,赋值给变量struct block_device *whole,然后调用递归__blkdev_get(),打开whole代表的整个设备,将bd_contains设置为变量whole。
- 如果
int blkdev_get(struct block_device *bdev, fmode_t mode, void *holder)
{
......
res = __blkdev_get(bdev, mode, 0);
......
}
static int __blkdev_get(struct block_device *bdev, fmode_t mode, int for_part)
{
struct gendisk *disk;
......
disk = bdev_get_gendisk(bdev, &partno);
......
if (!bdev->bd_openers) {
first_open = true;
bdev->bd_disk = disk;
bdev->bd_queue = disk->queue;
bdev->bd_contains = bdev;
bdev->bd_partno = partno;
if (!partno) {
ret = -ENXIO;
bdev->bd_part = disk_get_part(disk, partno);
......
if (disk->fops->open) {
ret = disk->fops->open(bdev, mode);
......
}
} else {
struct block_device *whole;
whole = bdget_disk(disk, 0);
......
ret = __blkdev_get(whole, mode, 1);
......
bdev->bd_contains = whole;
bdev->bd_part = disk_get_part(disk, partno);
......
bd_set_size(bdev, (loff_t)bdev->bd_part->nr_sects << 9);
set_init_blocksize(bdev);
}
if (bdev->bd_bdi == &noop_backing_dev_info)
bdev->bd_bdi = bdi_get(disk->queue->backing_dev_info);
} else {
if (bdev->bd_contains == bdev) {
ret = 0;
if (bdev->bd_disk->fops->open)
ret = bdev->bd_disk->fops->open(bdev, mode);
/* the same as first opener case, read comment there */
if (bdev->bd_invalidated) {
if (!ret)
rescan_partitions(bdev->bd_disk, bdev);
else if (ret == -ENOMEDIUM)
invalidate_partitions(bdev->bd_disk, bdev);
}
if (ret)
goto out_unlock_bdev;
}
}
bdev->bd_openers++;
if (for_part)
bdev->bd_part_count++;
......
}
get_gendisk()逻辑如下
block_device是指向整个磁盘设备的。这个时候,我们只需要根据dev_t,在bdev_map中将对应的gendisk拿出来就好。block_device是指向某个分区的。这个时候我们要先得到hd_struct,然后通过hd_struct,找到对应的整个设备的gendisk,并且把partno设置为分区号。
/**
* get_gendisk - get partitioning information for a given device
* @devt: device to get partitioning information for
* @partno: returned partition index
*
* This function gets the structure containing partitioning
* information for the given device @devt.
*/
struct gendisk *get_gendisk(dev_t devt, int *partno)
{
struct gendisk *disk = NULL;
if (MAJOR(devt) != BLOCK_EXT_MAJOR) {
struct kobject *kobj;
kobj = kobj_lookup(bdev_map, devt, partno);
if (kobj)
disk = dev_to_disk(kobj_to_dev(kobj));
} else {
struct hd_struct *part;
part = idr_find(&ext_devt_idr, blk_mangle_minor(MINOR(devt)));
if (part && get_disk(part_to_disk(part))) {
*partno = part->partno;
disk = part_to_disk(part);
}
}
return disk;
}
最终的block_device的打开调用的open()函数定义在驱动层,如在 drivers/scsi/sd.c 里面,也就是 MODULE_DESCRIPTION(“SCSI disk (sd) driver”)。成功打开设备之后,就会调用sget()利用block_device填写super_block,从而完成挂载。注意,调用 sget() 的时候,有一个参数是一个函数 set_bdev_super()。这里面将 block_device 设置进了 super_block。而 sget 要做的就是分配一个 super_block,然后调用 set_bdev_super 这个 callback 函数。这里的 super_block 是 ext4 文件系统的 super_block。
static int set_bdev_super(struct super_block *s, void *data)
{
s->s_bdev = data;
s->s_dev = s->s_bdev->bd_dev;
s->s_bdi = bdi_get(s->s_bdev->bd_bdi);
return 0;
}
/**
* sget - find or create a superblock
* @type: filesystem type superblock should belong to
* @test: comparison callback
* @set: setup callback
* @flags: mount flags
* @data: argument to each of them
*/
struct super_block *sget(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags,
void *data)
{
......
return sget_userns(type, test, set, flags, user_ns, data);
}
/**
* sget_userns - find or create a superblock
* @type: filesystem type superblock should belong to
* @test: comparison callback
* @set: setup callback
* @flags: mount flags
* @user_ns: User namespace for the super_block
* @data: argument to each of them
*/
struct super_block *sget_userns(struct file_system_type *type,
int (*test)(struct super_block *,void *),
int (*set)(struct super_block *,void *),
int flags, struct user_namespace *user_ns,
void *data)
{
struct super_block *s = NULL;
struct super_block *old;
int err;
......
if (!s) {
s = alloc_super(type, (flags & ~MS_SUBMOUNT), user_ns);
......
}
err = set(s, data);
......
s->s_type = type;
strlcpy(s->s_id, type->name, sizeof(s->s_id));
list_add_tail(&s->s_list, &super_blocks);
hlist_add_head(&s->s_instances, &type->fs_supers);
spin_unlock(&sb_lock);
get_filesystem(type);
register_shrinker(&s->s_shrink);
return s;
}
至此,我们完成了块设备的加载。下图所示为整个挂载流程和结构图。由此开始,ext4文件系统的超级块初始化完毕,对上层来说只需要调用超级块即可,而底层的block_device则是不可见的,由此我们实现了字符设备和块设备接口的统一。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Ufq0Y16-1598018998542)(https://static001.geekbang.org/resource/image/62/20/6290b73283063f99d6eb728c26339620.png)]
六. 块设备的访问
在前文中我们有提到ext4文件系统最终调用ext4_file_write_iter(),它将I/O调用分为了直接I/O和缓存I/O
- 直接I/O:最终我们调用的是
generic_file_direct_write(),这里调用的是mapping()->a_ops()->direct_IO(),实际调用的是ext4_direct_IO(),往设备层写入数据。 - 缓存I/O:最终我们会将数据从应用拷贝到内存缓存中,但是这个时候,并不执行真正的 I/O 操作。它们只将整个页或其中部分标记为脏。写操作由一个
timer触发,那个时候才调用wb_workfn()往硬盘写入页面。接下来的调用链为:wb_workfn()->wb_do_writeback()->wb_writeback()->writeback_sb_inodes()->__writeback_single_inode()->do_writepages()。在do_writepages()中,我们要调用mapping->a_ops->writepages,但实际调用的是ext4_writepages(),往设备层写入数据。
本节由此开始,分析文件的写入最后在块设备上如何实现。
6.1 直接I/O访问
直接I/O访问从ext4_direct_IO()开始,实际会根据读、写类型调用相应的函数。这里我们只分析写函数。
static ssize_t ext4_direct_IO(struct kiocb *iocb, struct iov_iter *iter)
{
......
if (iov_iter_rw(iter) == READ)
ret = ext4_direct_IO_read(iocb, iter);
else
ret = ext4_direct_IO_write(iocb, iter);
......
}
static ssize_t ext4_direct_IO_write(struct kiocb *iocb, struct iov_iter *iter)
{
struct file *file = iocb->ki_filp;
struct inode *inode = file->f_mapping->host;
struct ext4_inode_info *ei = EXT4_I(inode);
ssize_t ret;
loff_t offset = iocb->ki_pos;
size_t count = iov_iter_count(iter);
......
ret = __blockdev_direct_IO(iocb, inode, inode->i_sb->s_bdev, iter,
get_block_func, ext4_end_io_dio, NULL, dio_flags);
......
}
ext4_direct_IO_write() 调用 __blockdev_direct_IO(),这里的inode->i_sb->s_bdev即为我们挂载时填充的block_device。__blockdev_direct_IO() 会调用 do_blockdev_direct_IO(),在这里面我们要准备一个 struct dio 结构和 struct dio_submit 结构,用来描述将要发生的写入请求。
static inline ssize_t
do_blockdev_direct_IO(struct kiocb *iocb, struct inode *inode,
struct block_device *bdev, struct iov_iter *iter,
get_block_t get_block, dio_iodone_t end_io,
dio_submit_t submit_io, int flags)
{
......
dio = kmem_cache_alloc(dio_cache, GFP_KERNEL);
dio->flags = flags;
dio->i_size = i_size_read(inode);
dio->inode = inode;
if (iov_iter_rw(iter) == WRITE) {
dio->op = REQ_OP_WRITE;
dio->op_flags = REQ_SYNC | REQ_IDLE;
if (iocb->ki_flags & IOCB_NOWAIT)
dio->op_flags |= REQ_NOWAIT;
} else {
dio->op = REQ_OP_READ;
}
sdio.blkbits = blkbits;
sdio.blkfactor = i_blkbits - blkbits;
sdio.block_in_file = offset >> blkbits;
sdio.get_block = get_block;
dio->end_io = end_io;
sdio.submit_io = submit_io;
sdio.final_block_in_bio = -1;
sdio.next_block_for_io = -1;
dio->iocb = iocb;
dio->refcount = 1;
sdio.iter = iter;
sdio.final_block_in_request =
(offset + iov_iter_count(iter)) >> blkbits;
......
sdio.pages_in_io += iov_iter_npages(iter, INT_MAX);
retval = do_direct_IO(dio, &sdio, &map_bh);
.....
}
do_direct_IO ()里面有两层循环,第一层循环是依次处理这次要写入的所有块。对于每一块,取出对应的内存中的页 page,在这一块中有写入的起始地址 from 和终止地址 to,所以第二层循环就是依次处理 from 到 to 的数据,调用 submit_page_section()提交到块设备层进行写入。
static int do_direct_IO(struct dio *dio, struct dio_submit *sdio,
struct buffer_head *map_bh)
{
const unsigned blkbits = sdio->blkbits;
const unsigned i_blkbits = blkbits + sdio->blkfactor;
int ret = 0;
while (sdio->block_in_file < sdio->final_block_in_request) {
struct page *page;
size_t from, to;
page = dio_get_page(dio, sdio);
from = sdio->head ? 0 : sdio->from;
to = (sdio->head == sdio->tail - 1) ? sdio->to : PAGE_SIZE;
sdio->head++;
while (from < to) {
unsigned this_chunk_bytes; /* # of bytes mapped */
unsigned this_chunk_blocks; /* # of blocks */
......
ret = submit_page_section(dio, sdio, page,
from,
this_chunk_bytes,
sdio->next_block_for_io,
map_bh);
......
sdio->next_block_for_io += this_chunk_blocks;
sdio->block_in_file += this_chunk_blocks;
from += this_chunk_bytes;
dio->result += this_chunk_bytes;
sdio->blocks_available -= this_chunk_blocks;
if (sdio->block_in_file == sdio->final_block_in_request)
break;
......
}
}
}
submit_page_section() 会调用 dio_bio_submit(),进而调用 submit_bio() 向块设备层提交数据。其中参数 struct bio 是将数据传给块设备的通用传输对象。
/**
* submit_bio - submit a bio to the block device layer for I/O
* @bio: The &struct bio which describes the I/O
*/
blk_qc_t submit_bio(struct bio *bio)
{
......
return generic_make_request(bio);
}
6.2 缓存I/O访问
缓存I/O调用从ext4_writepages()开始,这里首先通过mpage_prepare_extent_to_map()完成bio的初始化,然后通过ext4_ion_submit()提交I/O请求。
static int ext4_writepages(struct address_space *mapping,
struct writeback_control *wbc)
{
......
struct mpage_da_data mpd;
struct inode *inode = mapping->host;
struct ext4_sb_info *sbi = EXT4_SB(mapping->host->i_sb);
......
mpd.do_map = 0;
mpd.io_submit.io_end = ext4_init_io_end(inode, GFP_KERNEL);
ret = mpage_prepare_extent_to_map(&mpd);
/* Submit prepared bio */
ext4_io_submit(&mpd.io_submit);
......
}
这里比较重要的一个数据结构是 struct mpage_da_data。这里面有文件的 inode、要写入的页的偏移量,还有一个重要的 struct ext4_io_submit,里面有通用传输对象 bio。在 ext4_writepages() 中,mpage_prepare_extent_to_map() 用于初始化这个 struct mpage_da_data 结构,调用链为:mpage_prepare_extent_to_map()->mpage_process_page_bufs()->mpage_submit_page()->ext4_bio_write_page()->io_submit_add_bh()。
struct mpage_da_data {
struct inode *inode;
......
pgoff_t first_page; /* The first page to write */
pgoff_t next_page; /* Current page to examine */
pgoff_t last_page; /* Last page to examine */
struct ext4_map_blocks map;
struct ext4_io_submit io_submit; /* IO submission data */
unsigned int do_map:1;
};
struct ext4_io_submit {
......
struct bio *io_bio;
ext4_io_end_t *io_end;
sector_t io_next_block;
};
在 io_submit_add_bh() 中,此时的 bio 还是空的,因而我们要调用 io_submit_init_bio()初始化 bio。
static int io_submit_init_bio(struct ext4_io_submit *io,
struct buffer_head *bh)
{
struct bio *bio;
bio = bio_alloc(GFP_NOIO, BIO_MAX_PAGES);
if (!bio)
return -ENOMEM;
wbc_init_bio(io->io_wbc, bio);
bio->bi_iter.bi_sector = bh->b_blocknr * (bh->b_size >> 9);
bio->bi_bdev = bh->b_bdev;
bio->bi_end_io = ext4_end_bio;
bio->bi_private = ext4_get_io_end(io->io_end);
io->io_bio = bio;
io->io_next_block = bh->b_blocknr;
return 0;
}
ext4_io_submit()提交 I/O请求和直接I/O访问一样,也是调用 submit_bio()
void ext4_io_submit(struct ext4_io_submit *io)
{
struct bio *bio = io->io_bio;
if (bio) {
int io_op_flags = io->io_wbc->sync_mode == WB_SYNC_ALL ?
REQ_SYNC : 0;
io->io_bio->bi_write_hint = io->io_end->inode->i_write_hint;
bio_set_op_attrs(io->io_bio, REQ_OP_WRITE, io_op_flags);
submit_bio(io->io_bio);
}
io->io_bio = NULL;
}
6.3 访问请求的提交,调度和处理
直接I/O访问和缓存I/O访问殊途同归,都会走到submit_bio()提交访问请求,该函数实际调用generic_make_request()。由于实际中块设备会分层次,如LVM上创建块设备等,因此这里会采取循环的方式依次从高层次向低层次发起访问请求。
每次 generic_make_request() 被当前任务调用的时候,将 current->bio_list 设置为 bio_list_on_stack,并在 generic_make_request() 的一开始就判断 current->bio_list 是否为空。
- 如果不为空,说明已经在
generic_make_request()的调用里面了,就不必调用make_request_fn()进行递归了,直接把请求加入到bio_list里面即可,这就实现了递归的及时退出。 - 如果
current->bio_list为空,则将current->bio_list设置为bio_list_on_stack后,进入do-while循环,获取请求队列并生成请求。
在 do-while 循环中先是获取一个请求队列 request_queue,接着在bio_list_on_stack[1] = bio_list_on_stack[0]语句中将之前队列里面遗留没有处理的保存下来,接着 bio_list_init() 将 bio_list_on_stack[0]设置为空,然后调用 make_request_fn(),在 make_request_fn() 里面如果有新的 bio 生成则会加到 bio_list_on_stack[0]这个队列里面来。
make_request_fn() 执行完毕后,可以想象 bio_list_on_stack[0]可能又多了一些 bio 了,接下来的循环中调用 bio_list_pop() 将 bio_list_on_stack[0]积攒的 bio 拿出来,分别放在两个队列 lower 和 same 中,顾名思义,lower 就是更低层次的块设备的 bio,same 是同层次的块设备的 bio。接下来我们能将 lower、same 以及 bio_list_on_stack[1] 都取出来,放在 bio_list_on_stack[0]统一进行处理。当然应该 lower 优先了,因为只有底层的块设备的 I/O 做完了,上层的块设备的 I/O 才能做完。
blk_qc_t generic_make_request(struct bio *bio)
{
/*
* bio_list_on_stack[0] contains bios submitted by the current
* make_request_fn.
* bio_list_on_stack[1] contains bios that were submitted before
* the current make_request_fn, but that haven't been processed
* yet.
*/
struct bio_list bio_list_on_stack[2];
blk_qc_t ret = BLK_QC_T_NONE;
......
if (current->bio_list) {
bio_list_add(¤t->bio_list[0], bio);
goto out;
}
bio_list_init(&bio_list_on_stack[0]);
current->bio_list = bio_list_on_stack;
do {
struct request_queue *q = bdev_get_queue(bio->bi_bdev);
if (likely(blk_queue_enter(q, bio->bi_opf & REQ_NOWAIT) == 0)) {
struct bio_list lower, same;
/* Create a fresh bio_list for all subordinate requests */
bio_list_on_stack[1] = bio_list_on_stack[0];
bio_list_init(&bio_list_on_stack[0]);
ret = q->make_request_fn(q, bio);
blk_queue_exit(q);
/* sort new bios into those for a lower level
* and those for the same level
*/
bio_list_init(&lower);
bio_list_init(&same);
while ((bio = bio_list_pop(&bio_list_on_stack[0])) != NULL)
if (q == bdev_get_queue(bio->bi_bdev))
bio_list_add(&same, bio);
else
bio_list_add(&lower, bio);
/* now assemble so we handle the lowest level first */
bio_list_merge(&bio_list_on_stack[0], &lower);
bio_list_merge(&bio_list_on_stack[0], &same);
bio_list_merge(&bio_list_on_stack[0], &bio_list_on_stack[1]);
}
......
bio = bio_list_pop(&bio_list_on_stack[0]);
} while (bio);
current->bio_list = NULL; /* deactivate */
out:
return ret;
}
根据上文请求队列的分析,make_request_fn() 函数实际用 blk_queue_bio()。blk_queue_bio() 首先做的一件事情是调用 elv_merge() 来判断,当前这个 bio 请求是否能够和目前已有的 request 合并起来成为同一批 I/O 操作,从而提高读取和写入的性能。如果没有办法合并,那就调用 get_request()创建一个新的 request,调用 blk_init_request_from_bio()将 bio 放到新的 request 里面,然后调用 add_acct_request()把新的 request 加到 request_queue 队列中。
static blk_qc_t blk_queue_bio(struct request_queue *q, struct bio *bio)
{
struct request *req, *free;
unsigned int request_count = 0;
......
switch (elv_merge(q, &req, bio)) {
case ELEVATOR_BACK_MERGE:
if (!bio_attempt_back_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_back_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_BACK_MERGE);
goto out_unlock;
case ELEVATOR_FRONT_MERGE:
if (!bio_attempt_front_merge(q, req, bio))
break;
elv_bio_merged(q, req, bio);
free = attempt_front_merge(q, req);
if (free)
__blk_put_request(q, free);
else
elv_merged_request(q, req, ELEVATOR_FRONT_MERGE);
goto out_unlock;
default:
break;
}
get_rq:
req = get_request(q, bio->bi_opf, bio, GFP_NOIO);
......
blk_init_request_from_bio(req, bio);
......
add_acct_request(q, req, where);
__blk_run_queue(q);
out_unlock:
......
return BLK_QC_T_NONE;
}
elv_merge 尝试了三次合并。
- 调用
blk_try_merge()判断和上一次合并的request能不能再次合并,看看能不能赶上马上要走的这部电梯。在blk_try_merge()中主要做了这样的判断:- 如果
blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector,也就是说request的起始地址加上它的大小(其实是这个request的结束地址)和bio的起始地址能接得上,那就把bio放在request的最后,我们称为ELEVATOR_BACK_MERGE。 - 如果
blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector,也就是说request的起始地址减去bio的大小等于bio的起始地址,这说明bio放在request的最前面能够接得上,那就把bio放在request的最前面,我们称为ELEVATOR_FRONT_MERGE。 - 否则,那就不合并,我们称为
ELEVATOR_NO_MERGE。
- 如果
- 如果和上一个合并过的
request无法合并,则调用elv_rqhash_find()按照bio的起始地址查找request,看有没有能够合并的。如果有的话,因为是按照起始地址找的,应该接在其后面,所以是ELEVATOR_BACK_MERGE。 - 如果依然找不到,则调用
elevator_merge_fn()按照bio的结束地址试图合并。对于iosched_cfq,调用的是cfq_merge()。在这里面cfq_find_rq_fmerge()会调用elv_rb_find()函数。如果有的话,因为是按照结束地址找的,应该接在其前面,所以是ELEVATOR_FRONT_MERGE。
enum elv_merge elv_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct elevator_queue *e = q->elevator;
struct request *__rq;
......
if (q->last_merge && elv_bio_merge_ok(q->last_merge, bio)) {
enum elv_merge ret = blk_try_merge(q->last_merge, bio);
if (ret != ELEVATOR_NO_MERGE) {
*req = q->last_merge;
return ret;
}
}
......
__rq = elv_rqhash_find(q, bio->bi_iter.bi_sector);
if (__rq && elv_bio_merge_ok(__rq, bio)) {
*req = __rq;
return ELEVATOR_BACK_MERGE;
}
if (e->uses_mq && e->type->ops.mq.request_merge)
return e->type->ops.mq.request_merge(q, req, bio);
else if (!e->uses_mq && e->type->ops.sq.elevator_merge_fn)
return e->type->ops.sq.elevator_merge_fn(q, req, bio);
return ELEVATOR_NO_MERGE;
}
enum elv_merge blk_try_merge(struct request *rq, struct bio *bio)
{
......
if (blk_rq_pos(rq) + blk_rq_sectors(rq) == bio->bi_iter.bi_sector)
return ELEVATOR_BACK_MERGE;
else if (blk_rq_pos(rq) - bio_sectors(bio) == bio->bi_iter.bi_sector)
return ELEVATOR_FRONT_MERGE;
return ELEVATOR_NO_MERGE;
}
static enum elv_merge cfq_merge(struct request_queue *q, struct request **req,
struct bio *bio)
{
struct cfq_data *cfqd = q->elevator->elevator_data;
struct request *__rq;
__rq = cfq_find_rq_fmerge(cfqd, bio);
if (__rq && elv_bio_merge_ok(__rq, bio)) {
*req = __rq;
return ELEVATOR_FRONT_MERGE;
}
return ELEVATOR_NO_MERGE;
}
static struct request *
cfq_find_rq_fmerge(struct cfq_data *cfqd, struct bio *bio)
{
struct task_struct *tsk = current;
struct cfq_io_cq *cic;
struct cfq_queue *cfqq;
cic = cfq_cic_lookup(cfqd, tsk->io_context);
if (!cic)
return NULL;
cfqq = cic_to_cfqq(cic, op_is_sync(bio->bi_opf));
if (cfqq)
return elv_rb_find(&cfqq->sort_list, bio_end_sector(bio));
return NUL
}
设备驱动程序往设备里面写,调用的是请求队列 request_queue 的另外一个函数 request_fn()。对于 scsi 设备来讲,调用的是 scsi_request_fn()。在这里面是一个 for 无限循环,从 request_queue 中读取 request,然后封装更加底层的指令,给设备控制器下指令实施真正的 I/O 操作。
static void scsi_request_fn(struct request_queue *q)
__releases(q->queue_lock)
__acquires(q->queue_lock)
{
struct scsi_device *sdev = q->queuedata;
struct Scsi_Host *shost;
struct scsi_cmnd *cmd;
struct request *req;
/*
* To start with, we keep looping until the queue is empty, or until
* the host is no longer able to accept any more requests.
*/
shost = sdev->host;
for (;;) {
int rtn;
/*
* get next queueable request. We do this early to make sure
* that the request is fully prepared even if we cannot
* accept it.
*/
req = blk_peek_request(q);
......
/*
* Remove the request from the request list.
*/
if (!(blk_queue_tagged(q) && !blk_queue_start_tag(q, req)))
blk_start_request(req);
.....
cmd = req->special;
......
/*
* Dispatch the command to the low-level driver.
*/
cmd->scsi_done = scsi_done;
rtn = scsi_dispatch_cmd(cmd);
......
}
return;
......
}
总结
本文详细叙述了块设备的基本结构体以及块设备从挂载到访问的全部过程,由此可以对块设备有一个全面的了解。
源码资料
[1] block_device
[2] gendisk
[3] hd_struct
[4] bdev_cache_init
[5] ext4_direct_IO
参考资料
[1] wiki
[3] woboq
[4] Linux-insides
[5] 深入理解Linux内核
[6] Linux内核设计的艺术
[7] 极客时间 趣谈Linux操作系统
[8] Linux设备驱动程