处理重复数据
import pandas as pd
data = {
'a': ['one', 'one', 'two', 'two', 'two', 'three', 'four'],
'b': ['1', '1', '2', '2', '2', '3', '4'],
'c': ['5', '6', '7', '8', '9', '10', '11']
}
df = pd.DataFrame(data)
# 前面是否已经出现过该元素
print(df.duplicated('a'))
print(df.duplicated('b'))
print(df.duplicated('c'))
# 如果有重复的,第一个算重复
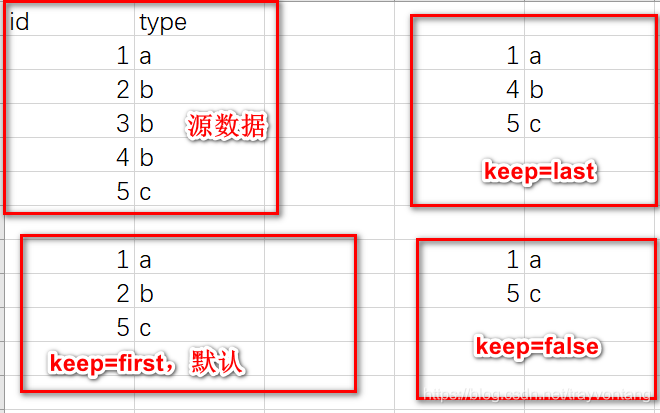
print(df.duplicated('a', keep='last'))
# 如果有重复的,最后一个算重复
print(df.duplicated('b', keep='first'))
# 如果有重复的,都算重复
print(df.duplicated('c', keep=False))
# 删除重复行
print(df.drop_duplicates('a'))
print(df.drop_duplicates('a', keep='last'))
print(df.drop_duplicates('a', keep='first'))
print(df.drop_duplicates('a', keep=False))
# 使用a、b这2列都一样才算重复
print(df.duplicated(['a', 'b']))
print(df.drop_duplicates(['a', 'b']))
print(df[~df.duplicated()])
# 删除a列中重复的行
print(df[~df.a.duplicated()])
# df[~df.index.duplicated(keep='last')]
# df[~df.index.duplicated(keep=False)]
处理空值
当空值相加的时候,只要有一个是空值得到的就是空值,sum,mean等函数默认是跳过空值的的,
可以通过df.cumsum(skipna=False)这样的方式来不跳过空值。
因为空值为带来一些不确定性,所以我们一般会先处理空值。
判断空值
判断空值有2个函数,isna判断是否为空,notna判断是否为非空
这2个函数有pandas静态函数和DataFrame实例方法。
import pandas as pd
import numpy as np
np.random.seed(147258369)
data = np.random.randint(0, 20, (3, 2))
df = pd.DataFrame(data, index=['a', 'c', 'f'], columns=['A', 'B'])
df['C'] = df['A'] - 5
df['D'] = df['A'] + 5
df = df.reindex(['a', 'b', 'c', 'd', 'f', 'g'])
print(df)
# 判断值是否为空
print(pd.isna(df['A']))
print(df.isna())
# 判断值是否为非空
print(pd.notna(df['B']))
print(df.notna())
填充空值
import pandas as pd
import numpy as np
np.random.seed(147258369)
data = np.random.randint(0, 20, (3, 2))
df = pd.DataFrame(data, index=['a', 'c', 'f'], columns=['A', 'B'])
df['C'] = df['A'] - 5
df['D'] = df['A'] + 5
df = df.reindex(['a', 'b', 'c', 'd', 'f', 'g'])
print(df)
# 填充0
tmp = df.copy()
print(tmp.fillna(0))
# 填充字符串
tmp = df.copy()
print(tmp['A'].fillna('missing'))
# 使用列前一个值来填充,下面3个填充方式是等价的
tmp = df.copy()
print(tmp.fillna(method='pad'))
tmp = df.copy()
print(tmp.fillna(method='ffill'))
tmp = df.copy()
print(tmp.ffill())
# 使用后一个值填充,只填充一个值
tmp = df.copy()
print(tmp.fillna(method='bfill', limit=1))
# 下面3中方式是等价的
tmp = df.copy()
print(tmp.fillna(method='bfill'))
tmp = df.copy()
print(tmp.fillna(method='backfill'))
tmp = df.copy()
print(tmp.bfill())
# 使用均值填充
tmp = df.copy()
print(tmp.fillna(df.mean()))
tmp = df.copy()
print(tmp.fillna(df.mean()['A':'B']))
tmp = df.copy()
print(tmp.where(pd.notna(df), df.mean(), axis='columns'))
删除空值
import pandas as pd
import numpy as np
np.random.seed(147258369)
data = np.random.randint(0, 20, (3, 2))
df = pd.DataFrame(data, index=['a', 'c', 'f'], columns=['A', 'B'])
df['C'] = df['A'] - 5
df['D'] = df['A'] + 5
df = df.reindex(['a', 'b', 'c', 'd', 'f', 'g'])
print(df)
tmp = df.copy()
print(tmp['A'].dropna())
tmp = df.copy()
print(tmp.dropna())
# 删除所有有空值的行
tmp = df.copy()
print(tmp.dropna(how='any'))
tmp = df.copy()
print(tmp.dropna(how='all'))
# 删除有空值的行
tmp = df.copy()
print(tmp.dropna(axis=0))
# 删除有空值的列
tmp = df.copy()
print(tmp.dropna(axis=1))