利用pandas读入csv文件
read_csv()基本参数介绍
filepath_or_buffer:csv文件的路径和名称,str类型
sep: 分隔符,默认sep = ‘,’
header :列名称,默认‘infer’,当读入的csv有名称是可以不用设置,没有名称时设置为header = None
names :当header=None时,可以给各列名称赋值,默认 names=None
index_col:选取某列作为行的索引,默认index_col=None
usecols:选取固定的某列,默认usecols=None
skiprows:要跳过的行数(int)或者要跳过的行索引(list),默认skiprows= None
nrows:最大行数,默认nrows= None
encoding:编码格式,当有乱码提示utf-8有error时,需要更改编码格式,如‘ANSI’等,默认encoding=‘utf-8’
实例1 读取csv文件用Name添加标题
header = None的情况如下所示,
data = pd.read_csv('学生月考成绩表.csv',sep=',',header=None,names= ['Name','Name1','Name2','Name3','Name4','Name5','Name6'])
data
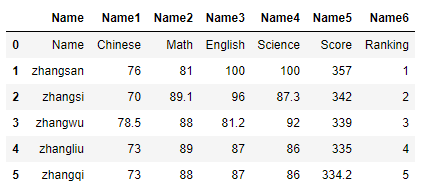
当header = 0时,原来的标题被重新命名
data = pd.read_csv('学生月考成绩表.csv',sep=',',header=0,names= ['Name','Name1','Name2','Name3','Name4','Name5','Name6'])
data

实例2 选取数据的某列作为行的索引
data = pd.read_csv('学生月考成绩表.csv',sep=',',index_col = 'Name')
data
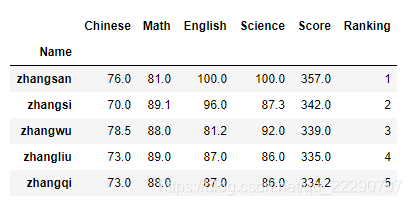
data = pd.read_csv('学生月考成绩表.csv',sep=',',index_col = 'Name')
data.loc['zhangsan','Ranking']

实例3 选取数据的固定列和行
选取第3列,第4行
data = pd.read_csv('学生月考成绩表.csv',sep=',',usecols=['Math'])
data

data = pd.read_csv('学生月考成绩表.csv',sep=',',usecols=['Math'],skiprows=[1,2,3,5])
data
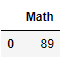
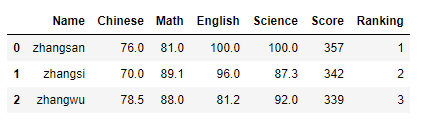
实例4 选取csv文件的最大行数
data = pd.read_csv('学生月考成绩表.csv',sep=',',nrows = 3) #提取前三行数据
data
实例5 读取csv文件时,编码格式的更改
现在把‘Name’一列全改为汉字格式,具体如下
data = pd.read_csv('学生月考成绩表.csv')
data
提示错误:UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xd5 in position 0: invalid continuation byte

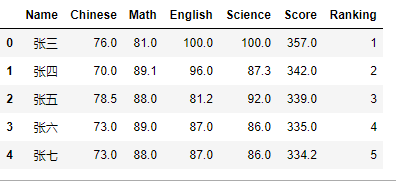
更改encoding类型,则显示正常。
data = pd.read_csv('学生月考成绩表.csv',encoding='ANSI')
data
参考
【1】 https://blog.csdn.net/qq_22290797/article/details/104706093