1.虚拟地址空间
进程地址空间需要隔离,防止恶意的程序修改其它程序的内存数据,因此计算机中引入虚拟地址空间。
虚拟地址空间布局
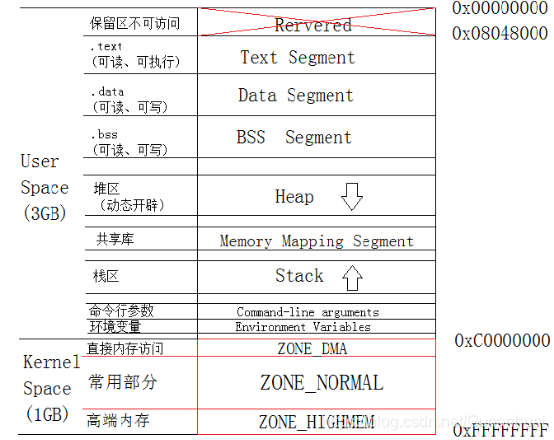
| .text(代码段) | 可执行代码、只读变量、字符串常量 |
|---|---|
| .data(数据段) | 已初始化且初值非0的全局变量和静态变量(全局和局部) |
| .bss | 未初始化或初始值为0的全局变量和静态变量。如果变量都已初始化,则bss段被清零 |
| heap(堆) | 动态申请的内存 |
| 共享库 | 程序运行时被动态加载到内存中使用(Linux下为.so文件,widow下为.DLL文件) |
| stack(栈) | 程序运行时需要在这里做数据运算,存储临时数据(局部变量、局部只读变量、函数参数、返回地址等),开辟函数栈等。Linux下,栈是高地址往低地址开辟的。对于函数栈来说,函数运行完毕就释放内存。 |
| 命令行参数 | 类似ps -eLf 中-eLf就是命令行参数,而ps是可执行程序。 |
| 环境变量 | linux下的PATH,HOME等的环境变量(子进程会继承父进程的环境变量) |
| ZONE_DMA | 直接访问区,16M |
| ZONE_NORMAL | 常用区,映射页目录表,892M |
| 高端内存区 | 大于1G的文件的映射 |
2.编译链接原理
编译和链接:
1)预编译(生成*.i文件)
1>将所有的“#define”删除,并且展开所有宏;
2>处理掉所有条件预编译指令,如:“#if”、“#ifdef”、“#elif”、“#else”、“#endif”;
3>处理“#include”指令,这是一个递归过程;
4>删除所有的注释“//”和“/* */”;
5>添加行号和文件名标识;
6>保留所有的#pragma编译器指令,待编译器使用;
2)编译(生成*.s文件)
把预处理完的文件进行一系列的词法分析,语法分析,语义分析及优化后生成相对应的汇编代码文件。
3)汇编(生成*.o文件,也叫目标文件)
汇编器是将汇编代码转变成机器可以执行的指令,每一个汇编语句几乎都对应一条机器指令。
4)链接(生成*.exe文件,也叫可执行文件)
1>地址和空间分配;
2>符号解析;
3>符号重定位;
.o文件简单的文件格式布局


.bss不占用目标文件的空间
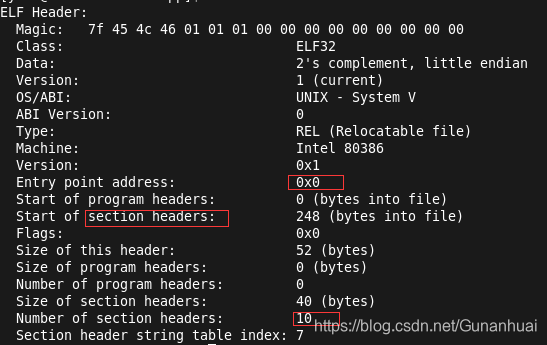
可以看到ELF Header中有一个叫做section headers的段,这个段保存了目标文件中每个段的详细信息,包括段的大小,起始偏移等等信息。编译器只要访问这个段就可以知道每个段的详细信息。.bss虽然不占空间但是.bss段的详细信息都被保存在section headers中.
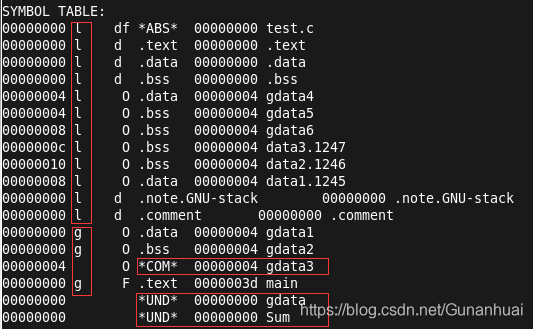
可以看到gdata3并不是存放在.bss段。这个数据存在COM这个块中,这个和C语言中的强弱符号有关
强符号:全局的已初始化的符号 弱符号:全局的未初始化的符号 强弱符号的选取规则:
1.两个强符号 编译报错
2.一个强符号 一个弱符号 选择强符号
3.两个弱符号 根据不同编译器处理方式不同
一个项目可能有多个源文件。编译阶段都是每个文件单独编译的。可能在其他文件中存在强符号,所以没办法在编译期间确定具体的符号。因此将本文件的弱符号存放在COM块,而不是.bss段。
符号解析和符号重定位
符号解析
在每个文件符号引用(引用外部符号)的地方找到符号的定义。这就是符号解析
符号重定位
先看下链接前生成的汇编代码
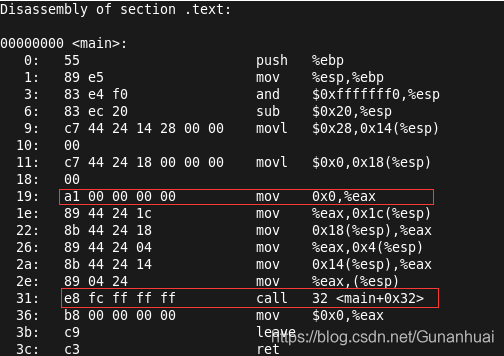
这两处分别是 0000 0000代表链接前编译器给gdata给出的地址,FF FF FF FC表示链接前编译器给Sum函数给出的函数的入口地址。这两个地址都是无效的地址。再看看链接后这两条地址
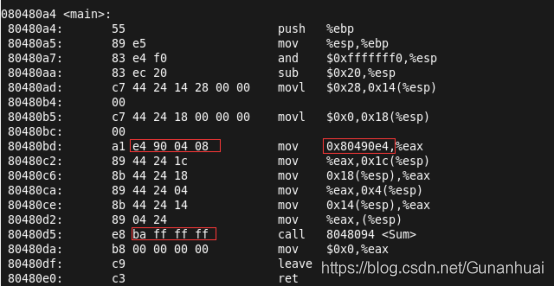
这两个地址变成gdata的具体虚拟地址和Sum函数的相对位移偏移量。而符号重定向就是对.o文件中.text段指令中的无效地址给出具体的虚拟地址或者相对位移偏移量。
我们来看看可执行文件的头部信息
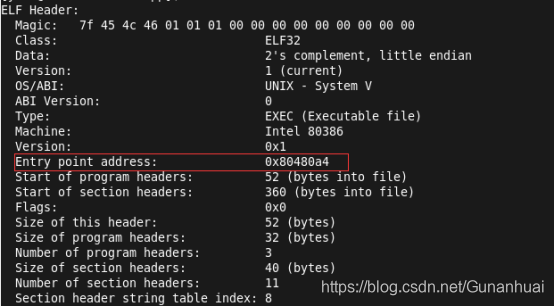
可以看到这个时候这个程序的入口地址已经给定080480A4这个就是main函数的入口地址。现在程序就可以运行了。