误用一:把缓存作为服务于服务之间数据传递的媒介
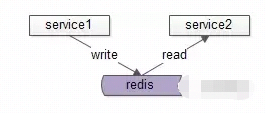
服务1和服务2约定好key和value,通过缓存传递数据;服务1将数据写入缓存,服务2从缓存读取数据,达到两个服务通信的目的。
存在问题:
-
数据管道,数据通知场景,MQ更加合适:思想是让专业的软件干专业的事情,nginx做反向代理,db做固话,cache做缓存,mq做通道
-
多个服务关联同一个缓存实例,会导致服务耦合:
a. 两个服务要约定好key的格式,value的格式,要保证两个服务的redis的IP和相关配置一致,如果一方改动,另外一方也要改动,所以耦合了。b. 约定好同一个key,可能会产生数据覆盖,导致数据不一致;或者会导致删除key的时候误删另外一个服务的某些key。
c. 不同服务的业务模式、数据量、并发量不一样,会导致两个服务之间相互影响,例如service-A数据量大,占用了cache的绝大部分内存,会导致service-B的热数据全部被挤出cache,导致cache失效;又例如service-A并发量高,占用了cache的绝大部分连接,会导致service-B拿不到cache的连接,从而服务异常。
误用二:使用缓存未考虑雪崩
常规缓存玩法,如下图所示:服务先读缓存,缓存命中则返回,缓存不命中,则读数据库
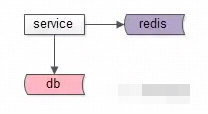
存在问题:如果redis这个单点挂掉了,那么所有的请求都落到db层,如果db层扛不住,那么系统就彻底不可用了,这个就叫雪崩。
所以上面的设计一定是做过容量评估后,可以容忍redis这个单点挂掉的,才能执行这个方案。如果说可能会有雪崩的可能(即redis挂掉,db必然扛不住),那么要实施如下两个方案中的任意一个方案。
方案一:缓存高可用:冗余 + 自动故障转移
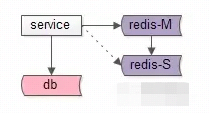
如上图,如果M实例挂了,可以流量自动转移到S。
方案二:缓存水平切分
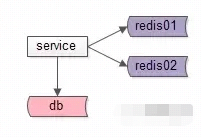
如上图,使用缓存水平切分(推荐使用一致性哈希算法进行水平切分),一个缓存实例挂掉后,不至于所有的流量都压到数据库上。
误用三:调用方缓存数据
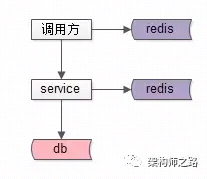
如上图:
服务提供方使用缓存,向调用方屏蔽底层的复杂性,这个是没问题的
服务调用方,也缓存一份数据,先读自己的缓存,再决定是否调用服务
存在问题:
- 调用方需要关注数据获取的复杂性,属于耦合的问题
- 服务层db修改,淘汰redis缓存,难以通知调用方淘汰cache,从而导致数据不一致。
- 如果服务通过MQ的方式通知调用方,这个设计更坑,下游服务要依赖上游的调用方,这个就违反了分层架构设计里面的不能反向依赖原则。
误用四:多服务共用缓存实例
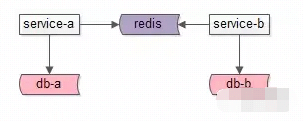
如上图,服务a和服务b公用一个缓存实例(不是通过这个缓存实例交换数据)
存在问题:
- 可能导致key冲突,彼此冲掉对方的数据
- 不同服务对应的数据量,吞吐量不一样,公共一个实例会导致一个服务把另一个服务的热数据挤出去,或者一方误用了redis导致另一服务不可用。
- 共用一个实例,会导致服务之间耦合,与微服务架构中的“数据库,缓存私有”的设计原则相悖。
正确姿势:
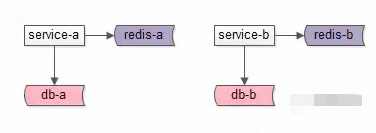
如上图:各个府服务私有化自己的数据存储,对上游屏蔽底层的复杂性
总结:
- 服务于服务之间不要通过缓存传递数据,如果传递数据,请用MQ,专业的软件干专业的事情。
- 容量评估的时候,如果缓存挂掉,可能会导致雪崩,此时要么做缓存高可用,要么做缓存的水平切分
- 调用方不宜再单独使用缓存存储服务底层的数据,容易出现数据不一致,以及反向依赖。
- 不同服务,缓存实例要做垂直拆分。
参考
- https://www.jianshu.com/p/3613d55fb843