第一章,创建一个EC2实例
首先需要注册一个AWS的账号,在账号的服务中找到EC2。
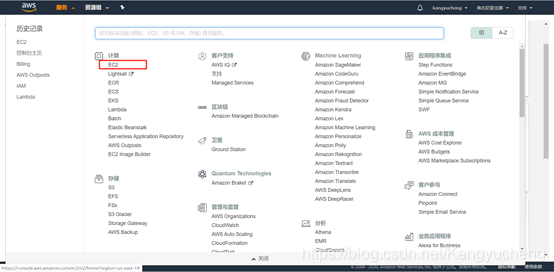
可以看到我们的账号里面目前是没有实例的。点击橘黄色按钮【启动实例】

第一步,选择操作系统,本人选择Amazon Linux。点击【下一步】

但是这个并不重要,选择什么操作系统都可以。只要你熟悉相应的操作系统就好。
第二步,选择操作系统,本人选择免费的那个,当然,这个配置也很低。土豪随意。点击【下一步】

第三四五步保持默认,全部点击下一步。
到第六步。分配安全组,这里面只有我一个用户,因此就选现有的安全组就好了。点击【审核和启动】。

第七步点击启动,会弹出对话框。

这里面如果之前没有创建过,可以先创建一个。密钥名称按照自己的想法输入一个就好了。然后把密钥的文件保存好。

成功

第二章,与EC2实例通信
本地的系统与EC2通信是需要SSH的。如果是MAC系统那么可以直接通过命令行来搞就行了。如果是windows建议还是搞个工具,比如MobaXterm。

完成安装后打开。
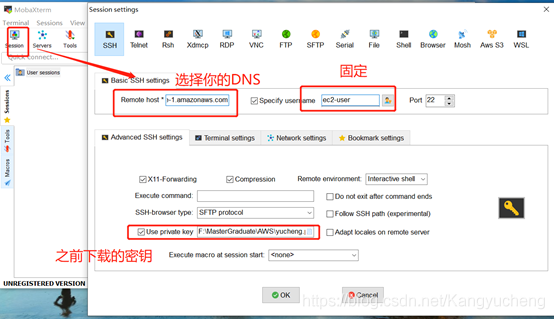
其中DNS如下图所示。

在然后就会发现,咦,怎么连不上呢???????????

我们去看看安全组的规则,验证是否有允许流量从您的计算机到端口 22 (SSH) 的规则。

点击后面的【default】

可以看到,这里面的来源需要更改一下,点击编辑,可以根据自己的需求来设定。比如设置成【我的IP】,那就会自动获取你的IP,然后点击保存。个人认为设置成【任何位置】也是可以的。

然后在去重新连接

第三章,环境部署
首先看一下实例的类型是32位还是64位,

1.安装Miniconda。
由于本人的工程是python3完成的,因此,选择如图所以

将下载好的文件传入EC2

执行
bash Miniconda3-latest-Linux-x86_64.sh
然后将conda添加到环境变量
export PATH=~/miniconda3/bin:$PATH
输入
conda list 测试一下是否安装成功,如果有正常的一堆输出那就是安装好了。
2.开始安装python的相关的环境,此处环境就需要自己配置了,本人用到的几个常用的包。
conda create -n scrapy python=3.7.5
conda install scrapy
conda install beautifulsoup4
conda install lxml
conda install selenium
先安装chrom。3.如果用到了webdriver的也要安装webdriver。
wget https://dl.google.com/linux/direct/google-chrome-stable_current_x86_64.rpm
sudo yum install google-chrome-stable_current_x86_64.rpm
google-chrome-stable -version![]()
查看version,找到与之对应的webdriver
http://chromedriver.storage.googleapis.com/index.html

将driver也拷贝到ec2中,记得将driver与自己的爬虫结合起来
4.将工程拷贝到虚拟机的目录下面。运行就可以了。