本教程均为本人的学习笔记,如果有误,请指正,感谢大家查看。
一、 索引简介
1. 索引的作用
MySQL索引的建立对于MySQL的高效运行是很重要的,创建索引后,数据库就不会进行全表查询,而是通过了类似于目录检索的方式来进行查询,直接定位到相关数据,索引可以大大提高MySQL的检索速度,比较常用的有:主键索引,唯一索引,普通索引等。
本质:索引是帮助MySQL高效获取数据的排好序的数据结构。
2. 索引的创建方式
#表结构存在时创建索引
CREATE INDEX indexName ON mytable(username(length));
#或
ALTER table tableName ADD INDEX indexName(columnName)
#建表时创建索引
CREATE TABLE mytable(
ID INT NOT NULL,
username VARCHAR(16) NOT NULL,
INDEX [indexName] (username(length))
);
#删除索引
DROP INDEX [indexName] ON mytable;
二、 常用的树形结构简介
MySQL索引使用的是B+Tree,接下来让我们分析一下每种属性结构的优劣。
1. 二叉树(Binary Search Trees)
树形结构每一个父节点都最多只有两个子节点,插入数据时与父节点进行比对,如果大于则插入在右边,如果小于则插入在左边:

而搜索时只需要通过比较父节点,即可快速定位到子节点:

如图所示,如果不使用索引,数据库就会进行全表查找,找到9这个节点我们可能需要进行最多7次查找,而使用二叉树作为索引,则只需要进行三次比对查找即可。
但是mysql并没有将二叉树作为索引方式,让我们看一下二叉树结构的偶然情况:

如果我们的数据始终递增/递减,则使用二叉树时,子节点数据会始终加在父节点的右边/左边,在查询时,依旧会出现全表扫描的情况!
2.红黑树(Red-Black Trees)
红黑树的基本原理与二叉树相同,不过红黑树与二叉树相比较加入了自动平衡算法,如果树形结构两边节点出现单边失衡,则会自动重组树形结构,保证两边平衡,所以红黑树算是一种“二叉平衡树”(与真正的二叉平衡树相比,红黑树不会保证所有节点平衡,避免过多的重组树形结构导致资源浪费)!
现在让我们看一下刚才情况:

红黑树的自动平衡算法弥补了二叉树的缺陷,但是mysql依旧没有将红黑树作为mysql索引的结构,比如图中例子,虽然有自动平衡算法,但是数据库依旧需要非常频繁的读取磁盘来判断子节点的位置,而系统直接与磁盘交互是非常缓慢的过程,所以mysql不使用红黑树作为索引结构!
3.B树(B Trees)
B树
既然频繁的从磁盘读取内容非常缓慢,那么我们就直接将多个数据作为一个节点存储,该节点的子节点同样存储多条数据,从磁盘读取节点时,直接将多条数据一并读出并比较即可。

B树的诞生主要是为了减少查询是系统与磁盘的交互次数,将一定量的数据直接全部读取到内存中一次比较即可,而我们mysql就是使用B树的变种B+树进行索引存储。
三、B+树详解(B+ Trees)

B+树是B树的变种形式,主要改变为父节点只存储叶子结点的引用和索引列,而所有数据只在叶子结点存储,虽然会出现数据的冗余,但提升了整棵树的存储能力。

从此图中我们可以看到,如此多的数据,将一定数量的数据作为一个节点读入内存,只需要最多与磁盘交互三次即可查询到,系统与内存的交互速度远远高于与磁盘交互。所以mysql使用B+树作为索引结构。
举个例子:设置一个长整数型的ID作为主键索引,现在让我们来计算一下一棵树的容量!
先查看一下mysql对于每个节点的大小设置:
SHOW GLOBAL STATUS LIKE 'INNODB_PAGE_SIZE'
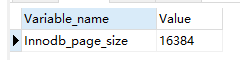
mysql中默认每个节点默认大小为16384字节(16KB)。
长整型ID所占大小为8字节,B+树每个数据后面都会存储一个地址指向叶子节点的数据(6字节)
父节点每个节点可以存储的索引数量:
16384/(8+6)=1170个索引。
暂且计算树高在3层,极限情况下,所可以存储的数据量为:
1170 * 1170 = 1368900个叶子结点
每个叶子结点大小为16kb,则可存储的数据量为:
1170117016 =21902400kb = 20GB的数据
如果每条数据大小为1kb,则可存储数据条数为:
1170117016/(16/1)=21902400条
也就是说,大概2千万条数据,只需要查找三次即可找到,这就是B+树作为数据库索引查找迅速地原因!
B+树查找过程:
1.从磁盘中一次性读取16kb大小的一个节点文件,节点中包含了索引列的数据和下层节点的引用地址(如果是长整数型ID,则一次读取1170条数据)
2.逐个比较读取的数据(树形结构会将父节点的数据按照相等的间距排列),当查找的值在两个数据范围中间则向下寻找其子节点。
3.如果不是叶子节点,按照第(1)部继续比较,并查找子结点,如果是叶子结点,则比较叶子结点,查找数据。
比如:

数据11在7-13之间,则向下寻找子节点,比较子节点,数据大于等于11,则按红线继续向下寻找,直至找到11。
叶子结点之间指针的作用

我们可以看到没个叶子结点都会存储指向相邻叶子结点的指针。
假设我们有这样一个SQL语句(其中age列为索引列)
select * from user where age >20
因为索引列是按照顺序排列好的,所以当找到20这个临界值后,后面的数据一定是符合要求的 ,有了叶子结点指针后,就可以通过指针快速定位不同节点中的数据,而不是返回父节点重新查找!
这也是mysql数据库不默认使用hash算法的原因之一(hash算法通过散列映射可以快速定位数据,查找速度很快,但无法适用于范围查找的情况)。
四、不同存储引擎B+树区别分析
mysql中提供了多种不同的存储引擎,存储引擎与数据表有关,mysql默认为innodb存储引擎,同时常用的还有myisam,不同存储引擎B+树的存储方式有略微区别。
1.聚集索引(聚簇索引)和非聚集索引区别
- 聚集索引: 数据直接按照索引的排序规则存储,叶子结点直接就是所有数据。
- 非聚集索引:索引单独存储,叶子结点只存储数据的引用。
2.myisam存储引擎
myisam存储引擎B+树的叶子结点只存储当前数据的引用,并不存储整个数据,并且索引文件与数据文件分开存放。
也就是说:myisam存储引擎的数据是单独存放的,并不会按照一定顺序进行排序,查找数据是,先从索引文件B+树查找叶子结点,叶子结点继续当前记录的地址,通过地址直接定方位到数据。
所以:myisam的索引是非聚集索引,一个表中一个亿没有任何索引(主键),同时相同的锁引树高可以存放更多的数据。
但是:myisam是通过指针再查找数据,相对较慢,而且myisam引擎本身不支持事务管理等很多功能,所以一般不常用!

3.innodb存储引擎
innodb存储引擎是将数据直接按照顺序存储在叶子节点上,找到叶子结点即是找到数据,数据按照主键索引排序后与索引存放在一起。
也就是说:innodb的索引与数据是存放在一起的,不需要再通过地址查找,查找时间更快,但相同树高存储数据更少。innodb使用的是是聚集索引(主键),所以必须按照一定顺序排序数据,这就要求数据表中一定要有主键,如果没有主键,mysql会自动建立隐藏主键来排序存储数据。

myisam存储引擎无论有多少主键,都是按照非聚集索引的方式存储,但innodb不同,主键是聚集索引,但其他索引并非聚集,而是建立额外的B+树,将索引列存储,叶子结点存储数据的主键,再根据主键索引查找数据。
也就是说:innodb的的其它索引查找时要查找两次,第一次先查找出数据对应的主键,在通过主键查找到对应数据!
这里普通索引不记录地址而是记录主键的原因是:innodb的数据是排序后的,在插入数据时,可能会导致整棵树的结构改变,进而影响数据的地址,而主键是永远不会变的,所以只能通过主键第二次查找找到数据。

另外,innodb的主键建议使用自增的整型数据,而不是用UUID。
因为自增整型数据对整棵树的影响较小,而UUID因为其hash值大小并不确定,所以可能左插一个右插一个,进而对整棵树的结构影响较大,速度较慢,而且,查找时比较UUID取hash,和直接比较整型数据,整型数据比较的更快速!
索引本质就是避免mysql查询数据是进行全表扫描,以类似于目录结构的形式快速查找数据,建立索引可以极大提高数据查找速度,但是过多的索引会占用磁盘空间造成浪费,合理的建立索引是非常必要的,希望本教程可以帮助大家更好地理解索引,谢谢观看。