目录
1.为什么要分片存储
用户量大的时候会出现单台服务器不够用、读写瓶颈凸显、处理效率低等问题,因此需要分片存储技术。
业务示例:公司用户量3千万,用户基本信息缓存到redis中,需要10G内存,如何设计Redis缓存架构?
- 3千万用户,各个业务场景对用户信息的访问量很大。(单台redis示例的读写瓶颈凸显)
- 单redis实例管理10G内存,必然影响处理效率。
- redis的内存需求可能超过机器的最大内存。(一台服务器不够用。)
2.官方集群方案
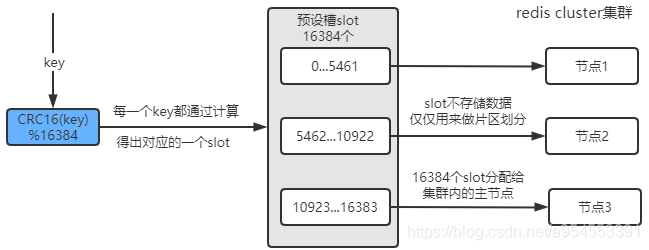
redis cluster是Redis的分布式集群解决方案,在3.0版本推出后有效地解决了redis分布式方面的需求
实现了数据在多个Redis节点之间自动分片、故障自动转移、扩容机制等功能。
图示:

3.集群搭建步骤
(1)环境信息
centos7
redis6
(2)整体集群信息
直接一台机器上实现伪集群,设置不同的端口。
192.168.11.131(6381-6386共6个端口)
(3)每个服务器上安装下载redis
可以参照redis官网步骤
#安装到/usr/local/redis目录中 安装的文件只有一个bin目录
make install PREFIX=/usr/local/redis
#创建配置文件和data存放目录
mkdir /usr/local/redis/conf /usr/local/redis/data
(4)准备6个redis.conf配置文件
(下文示例中使用redis.conf根据不同端口来命名,方便一台机器上构建伪集群)
#配置文件进行了精简
#后台启动的意思
daemonize yes
#端口号(如果同一台服务器上启动,注意修改为不同端口
port 6381
#IP绑定,redis不建议对公网开放,直接绑定0.0.0.0可以
bind 0.0.0.0
#redis数据文件存放的目录
dir /usr/local/redis/data
#开启AOF
appendonly yes
#开启集群
cluster-enabled yes
#会自动生成在上面配置的dir目录下
cluster-config-file nodes-6381.conf
cluster-node-timeout 5000
#这个文件会自动生成(如果同一台服务器上启动,注意修改为不同端口)
pidfile "/var/run/redis_6381.pid"
启动6个Redis实例
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6381.conf
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6382.conf
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6383.conf
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6384.conf
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6385.conf
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6386.conf
测试启动实例的情况

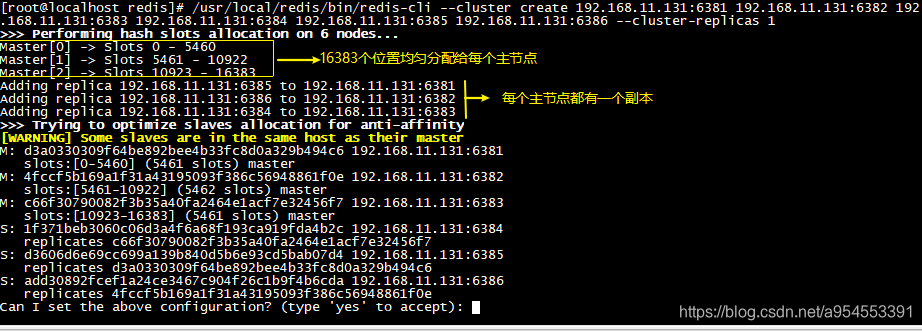
(5)创建cluster
/usr/local/redis/bin/redis-cli --cluster create 192.168.11.131:6381 192.168.11.131:6382 192.168.11.131:6383 192.168.11.131:6384 192.168.11.131:6385 192.168.11.131:6386 --cluster-replicas 1
(6)集群校验和测试
[root@localhost redis]# /usr/local/redis/bin/redis-cli -c -h 192.168.11.131 -p 6381
192.168.11.131:6381> cluster nodes

查看一个key属于哪一个节点
CLUSTER KEYSLOT key

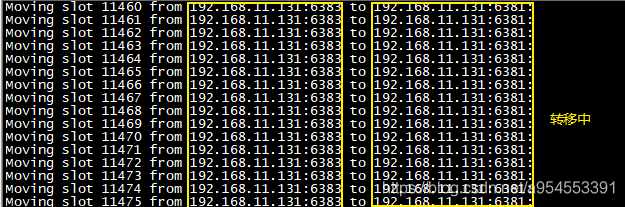
(7)集群slot数量整理reshard
当不同服务器内存大小不一致的时候,可以通过移动槽,来实现资源的合理利用。
#可以调调整,部分节点多放一点slot(槽或者位置)
/usr/local/redis/bin/redis-cli --cluster reshard <host>:<port> --cluster-from <node-id> --cluster-to <node-id> --cluster-slots <number of slots> --cluster-yes
例如:将6383服务器移动1000个槽给6381服务器
/usr/local/redis/bin/redis-cli --cluster reshard 192.168.11.131 6381 --cluster-from c66f30790082f3b35a40fa2464e1acf7e32456f7 --cluster-to d3a0330309f64be892bee4b33fc8d0a329b494c6 --cluster-slots 1000 --cluster-yes
重新检查集群
[root@localhost redis]# /usr/local/redis/bin/redis-cli --cluster check 192.168.11.131:6382

(8)测试自动故障转移
- cluster集群不能保证数据一致,数据也可能丢失。
- 首先是运行客户端不断的写入或者读取数据,以便能够发现问题。
- 然后是模拟节点故障,找一个主节点关闭,主从故障切换过程中,
- 这个时间段的操作,客户端而言,只能失败。
6381下线,6382查看节点情况,6384升级为主节点;6381上线,6382查看节点情况,此时6381已经变成从节点。
#停掉6381
[root@localhost redis]# /usr/local/redis/bin/redis-cli -c -h 192.168.11.131 -p 6381
192.168.11.131:6381> shutdown
not connected>
#查看节点情况
[root@localhost redis]# /usr/local/redis/bin/redis-cli -c -h 192.168.11.131 -p 6382
192.168.11.131:6382> cluster nodes
#重新启动6381
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6381.conf

(9)手动故障转移
- 可能某个节点需要维护(机器下线、硬件升级、系统版本调整等),需要手动的实现转移。
- 在slave节点上执行命令
CLUSTER FAILOVER CLUSTER help可以看到帮助文档和简介。相对安全的做法
192.168.11.131:6381> ClUSTER FAILOVER
4.扩容和缩容
(1)扩容
#启动新节点
[root@localhost redis]# /usr/local/redis/bin/redis-server /usr/local/redis/conf/6387.conf
#加入到已经存在的集群作为master
[root@localhost redis]# /usr/local/redis/bin/redis-cli --cluster add-node 192.168.11.131:6387 192.168.11.131:6382
#本质就是发送一个新节点,通过CLUSTER MEET命令加入集群
#新节点没有分配hash槽,通过“8.集群slot数量整理reshard”分配
#加入到已经存在的集群作为slaver
[root@localhost redis]# /usr/local/redis/bin/redis-cli --cluster add-node 192.168.11.131:6387 192.168.11.131:6382 --cluster-salve
#可以手工指定master,否则就选择一个slaver数量较少的master
[root@localhost redis]# /usr/local/redis/bin/redis-cli --cluster add-node 192.168.11.131:6387 192.168.11.131:6382 --cluster-salve --cluster-master-id <node-id>
#还可以将空master,转换为slave
cluster replicate <master-node-id>
#检查集群
/usr/local/redis/bin/redis-cli --cluster check 192.168.11.131:6382
(2)缩容
#注意:删除master的时候要把数据清空或者分配给其他主节点
[root@localhost redis]# /usr/local/redis/bin/redis-cli --cluster del-node 192.168.11.131:6387 <node-id>
5.集群关心的问题
(1)增加了slot槽的计算,是不是比单机性能差?
共16384个槽,slots槽计算方式公开的,HASH_SLOT=CRC16(key) mod 16384。
为了避免每次都需要服务器计算重定向,优秀的Java客户端都实现了本地计算,并且缓存服务器slots分配,有变动时再更新本地内容,从而避免了多次重定向带来的性能损耗。
(2)redis集群大小,到底可以装多少数据?
理论上是可以做到16384个槽,每个槽对应一个实例,但是redis官方建议最大1000个实例。存储足够大了。
(3)集群节点间是怎样通信的?
每个Redis集群节点都有一个额外的TCP端口,每个节点使用TCP连接与每个其他节点连接。检测和故障转移这些步骤基本和哨兵模式类似。 (毕竟是同一个软件,同一个作者设计的)。
(4)ask和moved重定向的区别
重定向包括两种情况
- 若干确定slot不属于当前节点,redis会返回moved
- 若当前redis节点正处理slot迁移 ,则此代表请求对应的key暂时不在此节点,返回ask,告诉客户端本次请求重定向。
(5)数据倾斜和访问倾斜的问题
倾斜导致集群部分节点数据多,压力大。解决方案分为前期和后期:
- 前期是业务层面提前预测,哪些key是热点,在设计的过程中规避。
- 后期是slot迁移,尽量将压力分摊(slot调整有自动relbalance、reshared和手动)
(6)slot手动迁移怎么做?
迁移过程如下:
- 在迁移目的节点执行
cluster set slot <slot> IMPORTING <node ID>命令,指明需要迁移的slot和迁移源节点。 - 在迁移源节点执行
cluster set slot <slot> MINGRTING <node ID>
命令,指明需要迁移的slot和迁移目的节点。 - 在迁移源节点执行
cluster get key inslot获取slot的key列表。 - 在迁移源节点执行对每个key执行
migrate命令,该命令会同步把该key迁移到目的节点。 - 在迁移源节点反复执行
clsuter get key inslot命令,知道该slot的列表清空。 - 在迁移源节点和目的节点执行
cluster set slot <slot> NODE <node ID>,完成迁移操作。
(7)节点之间会交互信息、传递的消息包括槽信息,带来带宽消耗。
注意:避免使用大的一个集群,可以分为多个集群。
(8)Pub/Sub发布订阅机制
注意:对集群内任意的一个节点执行publish发布消息,这个消息会在集群中进行传播,其他节点接收到发布的消息。
(9)读写分离
- redis-cluster默认所有从节点上的读写,都会重定向到key对接槽的主节点上。
- 可以通过readonly设置当前连接可读,通过readwirte取消当前连接的刻度状态。
注意:主从节点依然存在数据不一致的问题。