数据的特征抽取
A:特征抽取实例演示
通过演示得出结论:
- 特征抽取针对非连续型数据
- 特征抽取对文本等进行特征值化
注:特征值化是为了计算机更好的去理解数据。
B:sklearn特征抽取API
sklearn.feature_extraction模块,可以用于从包含文本和图片的数据集中提取特征,以便支持机器学习算法使用。
注意:Feature extraction与Feature Selection是完全不同的:前者将专有数据(文本或图片)转换成机器学习中可用的数值型特征;后者则是用在这些特征上的机器学习技术。
C:字典特征抽取
作用:对字典数据进行特征值化
类:sklearn.feature_extraction.DictVectorizer
以下来自:https://www.cnblogs.com/hufulinblog/p/10591339.html
将特征与值的映射字典组成的列表转换成向量。
DictVectorizer通过使用scikit-learn的estimators,将特征名称与特征值组成的映射字典构成的列表转换成Numpy数组或者Scipy.sparse矩阵。
当特征的值是字符串时,这个转换器将进行一个二进制One-hot编码。One-hot编码是将特征所有可能的字符串值构造成布尔型值。
例如:特征f有一个值ham,一个值spam,转换后会变成两个特征f=ham和f=spam.
注意:转换器只会将字符串形式的特征转换成One-hot编码,数值型的不会转换。
一个字典中样本没有的特征在结果矩阵中的值是0.
构造参数:
class sklearn.feature_extraction.DictVectorizer(dtype=<class‘numpy.float64’>, separator=’=’, sparse=True, sort=True)
dtype:callable, 可选参数, 默认为float。特征值的类型,传递给Numpy.array或者Scipy.sparse矩阵构造器作为dtype参数。
separator:string,可选参数,默认为"="。当构造One-hot编码的特征值时要使用的分割字符串。分割传入字典数据的键与值的字符串,生成的字符串会作为特征矩阵的列名。
sparse: boolearn, 可选参数,默认为True。transform是否要使用scipy产生一个sparse矩阵。DictVectorizer的内部实现是将数据直接转换成sparse矩阵,如果sparse为False, 再把sparse矩阵转换成numpy.ndarray型数组。
sort:boolearn,可选参数,默认为True。在拟合时是否要多feature_names和vocabulary_进行排序。
属性:
vocabulary_: 特征名称和特征索引的映射字典。
feature_names_: 一个包含所有特征名称的,长度为特征名称个数的列表。
方法:
fit(X,y=None): 计算出转换结果中feature name与列索引之间的对照字典vocabulary_,同时会计算出特征名称列表 feature_names_。这里的参数y没有任何作用。(X:字典或者包含字典的迭代器,返回值:返回sparse矩阵)
fit_transform(X,y=None): 包含fit函数的功能,并且会将X转换成矩阵。
get_feature_names(): 返回feature_names_ (返回类别名称)
get_params(deep=True): 返回当前DictVectorizer对象的构造参数。
inverse_transform(X[,dict_type]): 将矩阵还原成特征字典列表。还原出来的字典跟原数据并不是完全一样。传入的X必须是这个DictVectorizer经过transform或者fit_transform产生的X。(X:array数组或者sparse矩阵,返回值:转换之前数据格式)
restrict(support, indicies=False): 根据传入的support参数,对特征矩阵进行筛选。
**set_params(params): 设置DictVectorizer的参数
transform(X): 将X转换为numpy.ndarray或者Scipy.sparse (按照原先的标准转换)
流程:
1、实例化类DictVectorizer。
2、调用fit_transform方法输入数据并转换。
案例1:
from sklearn.feature_extraction import DictVectorizer
def dictvec():
"""
字典数据抽取
:return:
"""
#实例化
dict = DictVectorizer(sparse=False)
#调用fit_transform
data = dict.fit_transform([{
'city': '北京','temperature': 100}, {
'city': '上海','temperature':60}, {
'city': '深圳','temperature': 30}])
print("--------------get_feature_names-----------------------------------------------")
print(dict.get_feature_names())
print("--------------data,含有该feature_names的为1,否则为0,最终的目标值是实际的值-----")
print(data)
print("--------------inverse_transform:通过特征抽取的结果还原原来的数据---------------")
print(dict.inverse_transform(data))
return None
if __name__ == "__main__":
dictvec()
输出结果:
--------------get_feature_names-----------------------------------------------
['city=上海', 'city=北京', 'city=深圳', 'temperature']
--------------data,含有该feature_names的为1,否则为0,最终的目标值是实际的值-----
[[ 0. 1. 0. 100.] 0. 1. 0:表示有'city=北京'这个特征,'temperature'的值为100.
[ 1. 0. 0. 60.]
[ 0. 0. 1. 30.]]
--------------inverse_transform:通过特征抽取的结果还原原来的数据---------------
[{
'city=北京': 1.0, 'temperature': 100.0}, {
'city=上海': 1.0, 'temperature': 60.0}, {
'city=深圳': 1.0, 'temperature': 30.0}]
案例2:
from sklearn.feature_extraction import DictVectorizer
# 设置sparse=False获得numpy ndarray形式的结果
v = DictVectorizer(sparse=False)
D = [{
"foo": 1, "bar": 2}, {
"foo": 3, "baz": 1}]
# 对字典列表D进行转换,转换成特征矩阵
X = v.fit_transform(D)
# 特征矩阵的行代表数据,列代表特征,0表示该数据没有该特征
print(X)
# 获取特征列名
print(v.get_feature_names())
# inverse_transform可以将特征矩阵还原成原始数据
print(v.inverse_transform(X) == D)
# 直接进行转换,不先进行拟合的话,无法识别新的特征
print(v.transform([{
"foo": 4, "unseen_feature": 3}]))
输出结果:
[[2. 0. 1.]
[0. 1. 3.]]
['bar', 'baz', 'foo']
True
[[0. 0. 4.]]
配合特征选择:
from sklearn.feature_extraction import DictVectorizer
from sklearn.feature_selection import SelectKBest,chi2
# 设置sparse=False获得numpy ndarray形式的结果
v = DictVectorizer(sparse=False)
D = [{
"foo": 1, "bar": 2}, {
"foo": 3, "baz": 1}]
# 对字典列表D进行转换,转换成特征矩阵
X = v.fit_transform(D)
# 特征矩阵的行代表数据,列代表特征,0表示该数据没有该特征
print(X)
# 获取特征列名
print(v.get_feature_names())
# 得到一个筛选器,使用卡方统计筛选出最好的2个特征
support = SelectKBest(chi2, k=2).fit(X, [0, 1])
# 进行筛选,筛选的结果会自动覆盖原有的特征矩阵
print(v.restrict(support.get_support()))
print(v.get_feature_names())
输出结果为:
[[2. 0. 1.]
[0. 1. 3.]]
['bar', 'baz', 'foo']
DictVectorizer(dtype=<class 'numpy.float64'>, separator='=', sort=True,
sparse=False)
['bar', 'foo']
D:文本特征抽取
作用:对文本数据进行特征值化
类:sklearn.feature_extraction.text.CountVectorizer
CountVectorizer()函数只考虑每个单词出现的频率;然后构成一个特征矩阵,每一行表示一个训练文本的词频统计结果。其思想是,先根据所有训练文本,不考虑其出现顺序,只将训练文本中每个出现过的词汇单独视为一列特征,构成一个词汇表(vocabulary list),该方法又称为词袋法(Bag of Words)。
CountVectorizer语法:
CountVectorizer(max_df=1.0,min_df=1,…)
-
返回词频矩阵
-
CountVectorizer.fit_transform(X,y)
X:文本或者包含文本字符串的可迭代对象
返回值:返回sparse矩阵 -
CountVectorizer.inverse_transform(X)
X: array数组或者sparse矩阵
**返回值:**转换之前数据格式 -
CountVectorizer.get_feature_names()
**返回值:**单词列表
流程:
1、实例化类CountVectorizer
2、调用fit_transform方法输入数据并转换
注意返回格式,利用toarray()进行sparse矩阵转换array数组
案例:
from sklearn.feature_extraction.text import CountVectorizer
texts = ["orange banana apple grape","banana apple apple","grape", "orange apple"]
cv = CountVectorizer()
cv_fit = cv.fit_transform(texts)
print("------------cv.get_feature_names()-----------------")
print(cv.get_feature_names())
"""
结果为:
['apple', 'banana', 'grape', 'orange']
"""
print("-----------------cv.vocabulary_--------------------")
print(cv.vocabulary_)
"""
结果是:
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
这里是根据首字母顺序,将texts变量中所有单词进行排序,按照单词首字母排序的顺序:
apple 序号:0
banana 序号:1
grape 序号:2
orange 序号:3
"""
print("-----------------cv_fit----------------------------")
print(cv_fit)
"""
结果是:
(0, 3) 1
(0, 1) 1
(0, 0) 1
(0, 2) 1
(1, 1) 1
(1, 0) 2
(2, 2) 1
(3, 3) 1
(3, 0) 1
其中括号里面的第一列表示的是字符串的序号,以下针对第一列进行说明
0:表示字符串"orange banana apple grape"
1:表示字符串"banana apple apple"
2:表示字符串"grape"
3:表示字符串"orange apple"
组合起来:
(0, 3) 1 表示第一个字符串"orange banana apple grape"中出现orange的次数是1
(0, 1) 1 表示第一个字符串"orange banana apple grape"中出现banana的次数是1
依次类推
(1, 0) 2 表示第一个字符串"banana apple apple"中出现apple的次数是2
...
"""
print("--------------cv_fit.toarray()---------------------")
print(cv_fit.toarray())
"""
结果为:
[[1 1 1 1]
[2 1 0 0]
[0 0 1 0]
[1 0 0 1]]
可以理解为:
{'orange': 3, 'banana': 1, 'apple': 0, 'grape': 2}
'apple' 'banana' 'grape' 'orange'
"orange banana apple grape" [[1 1 1 1]
"banana apple apple" [ 2 1 0 0]
"grape" [ 0 0 1 0]
"orange apple" [ 1 0 0 1]]
即行表示字符串,列表示单词
"""
再如案例:
from sklearn.feature_extraction.text import CountVectorizer,TfidfVectorizer
X_test = ['I am a student','You can’t even make this stuff up']
# stop_words=None表示不去掉停用词,若改为stop_words='english'则去掉停用词
count_vec=CountVectorizer(stop_words=None)
#训练count_vec中的属性,并返回数组
arr = count_vec.fit_transform(X_test).toarray()
print('vocabulary list:\n', count_vec.get_feature_names())
"""
输出的结果为:
['am', 'can', 'even', 'make', 'student', 'stuff', 'this', 'up', 'you']
"""
print('result array:\n',arr)
"""
输出结果为:
[[1 0 0 0 1 0 0 0 0] #这里表示am和student都出现了1次,其它的出现了0次
[0 1 1 1 0 1 1 1 1]] #这里表示am和student没出现,其它的单词都出现了一次
上面的数组的列对应:
['am', 'can', 'even', 'make', 'student', 'stuff', 'this', 'up', 'you']
上面的数组有两行,表示有2段字符串
"""
print('vocabulary_:\n', count_vec.vocabulary_)
"""
结果是:
{'am': 0, 'student': 4, 'you': 8, 'can': 1, 'even': 2, 'make': 3, 'this': 6, 'stuff': 5, 'up': 7}
0 4 8 1 等这些数值表示在单词在count_vec.get_feature_names()的顺序
"""
##########################################################
########## CountVectorizer同样适用于中文 ##################
##########################################################
X_test = ['中国 你 是 城市 都是 小区', '中国 你 小区 旅行 饮食 学校']
## 默认将所有单个汉字视为停用词;
count_vec=CountVectorizer(token_pattern=r"(?u)\b\w\w+\b")
arr = count_vec.fit_transform(X_test).toarray()
print('vocabulary list:\n', count_vec.get_feature_names())
"""
输出结果为:
vocabulary list:
['中国', '城市', '学校', '小区', '旅行', '都是', '饮食']
"""
print('result array:\n', arr)
"""
输出结果为:
result array:
[[1 1 0 1 0 1 0]
[1 0 1 1 1 0 1]]
"""
print('vocabulary_:\n', count_vec.vocabulary_)
"""
输出结果为:
vocabulary_:
{'中国': 0, '城市': 1, '都是': 5, '小区': 3, '旅行': 4, '饮食': 6, '学校': 2}
"""
再如:
# 文档进行特征值化
# 导入包
from sklearn.feature_extraction.text import CountVectorizer
def countvec():
"""
对文本进行特征值化
:return:
"""
cv = CountVectorizer()
data = cv.fit_transform(["人生 苦短,我 喜欢 python","人生漫长,不用 python"])
print(cv.get_feature_names())
print(data.toarray())
return None
if __name__ == "__main__":
countvec()
输出结果为:
['python', '不用', '人生', '人生漫长', '喜欢', '苦短']
[[1 0 1 0 1 1]
[1 1 0 1 0 0]]
注意:不支持单个中文字
另外如果文本是一段连续的话,这时候就需要对中文进行分词才能详细的进行特征值化
中文分词,使用:jieba分词
下载:
进入Anaconda Prompt里面执行下面的命令:
pip install jieba
使用方法:
import jieba
jieba.cut("我是一个好程序员")
注意:
返回值:词语生成器
案例:
from sklearn.feature_extraction.text import CountVectorizer
import jieba
def cutword():
con1 = jieba.cut("今天很残酷,明天更残酷,后天很美好,但绝大部分是死在明天晚上,所以每个人不要放弃今天")
con2 = jieba.cut("我们看到的从很远星系来的光是在几百万年之前发出的,这样当我们看到宇宙时,我们是在看它的过去。")
con3 = jieba.cut("如果只用一种方式了解某样事物,你就才会真正了解它。")
# 转换成列表
content1 = list(con1)
content2 = list(con2)
content3 = list(con3)
# 把列表转换成字符串
c1 = ' '.join(content1)
c2 = ' '.join(content2)
c3 = ' '.join(content3)
return c1,c2,c3
def hanzivec():
"""
中文特征值化
:return:
"""
c1,c2,c3 = cutword()
print("----------------------c1,c2,c3--------------------------------")
print(c1,c2,c3)
cv = CountVectorizer()
data = cv.fit_transform([c1,c2,c3])
print("----------------------get_feature_names:----------------------")
print(cv.get_feature_names())
print("----------------------data.toarray:---------------------------")
print(data.toarray())
return None
if __name__ == "__main__":
hanzivec()
输出结果:
----------------------c1,c2,c3--------------------------------
今天 很 残酷 , 明天 更 残酷 , 后天 很 美好 , 但 绝大部分 是 死 在 明天 晚上 , 所以 每个 人 不要 放弃 今天 我们 看到 的 从 很 远 星系 来 的 光是在 几百万年 之前 发出 的 , 这样 当 我们 看到 宇宙 时 , 我们 是 在 看 它 的 过去 。 如果 只用 一种 方式 了解 某样 事物 , 你 就 才 会 真正 了解 它 。
----------------------get_feature_names:----------------------
['一种', '不要', '之前', '了解', '事物', '今天', '光是在', '几百万年', '发出', '只用', '后天', '如果', '宇宙', '我们', '所以', '放弃', '方式', '明天', '星系', '晚上', '某样', '残酷', '每个', '看到', '真正', '绝大部分', '美好', '过去', '这样']
----------------------data.toarray:---------------------------
[[0 1 0 0 0 2 0 0 0 0 1 0 0 0 1 1 0 2 0 1 0 2 1 0 0 1 1 0 0]
[0 0 1 0 0 0 1 1 1 0 0 0 1 3 0 0 0 0 1 0 0 0 0 2 0 0 0 1 1]
[1 0 0 2 1 0 0 0 0 1 0 1 0 0 0 0 1 0 0 0 1 0 0 0 1 0 0 0 0]]
TF-IDF
**TF-IDF的主要思想是:**如果某个词或短语在一篇文章中出现的概率高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
TF-IDF作用:用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度。
类:sklearn.feature_extraction.text.TfidfVectorizer
语法:
TfidfVectorizer(stop_words=None,…)
- 返回词的权重矩阵
TfidfVectorizer.fit_transform(X,y)
- **X:**文本或者包含文本字符串的可迭代对象
- **返回值:**返回sparse矩阵
TfidfVectorizer.inverse_transform(X)
X: array数组或者sparse矩阵
返回值: 转换之前数据格式
TfidfVectorizer.get_feature_names()
**返回值:**单词列表
案例:
from sklearn.feature_extraction.text import TfidfVectorizer
X_test = ['中国 你 是 城市 都是 小区', '中国 你 小区 旅行 饮食 学校']
# 默认将所有单个汉字视为停用词:
tfidf_vec=TfidfVectorizer(token_pattern=r"(?u)\b\w\w+\b")
arr = tfidf_vec.fit_transform(X_test).toarray()
print('vocabulary list:\n',tfidf_vec.get_feature_names())
"""
输出结果:
下面相当于是特征值
vocabulary list:
['中国', '城市', '学校', '小区', '旅行', '都是', '饮食']
"""
print('result array:\n',arr)
"""
下面的列代表是:['中国', '城市', '学校', '小区', '旅行', '都是', '饮食']
下面矩阵中有两行,即词的权重矩阵。
result array:
[[0.40993715 0.57615236 0. 0.40993715 0. 0.57615236 0. ]
[0.35520009 0. 0.49922133 0.35520009 0.49922133 0. 0.49922133]]
"""
机器学习原理这本书的介绍:
词频-逆向文件频率(TF-IDF)是一种在文本挖掘中广泛使用的特征向量化方法,它可以体现一个文档中词语在语料库中的重要程度。
词语由t表示,文档由d表示,语料库由D表示。词频TF(t,d)是词语t在文档d中出现的次数。文件频率DF(t,D)是包含词语的文档的个数。如果我们只使用词频来衡量重要性,很容易过度强调在文档中经常出现而并没有包含太多与文档有关的信息的词语,比如“a”,“the”以及“of”。如果一个词语经常出现在语料库中,它意味着它并没有携带特定的文档的特殊信息。逆向文档频率数值化衡量词语提供多少信息:
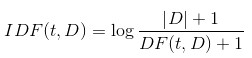
其中,|D|是语料库中的文档总数。由于采用了对数,如果一个词出现在所有的文件,其IDF值变为0。
TFIDF(t,d,D)=TF(t,d) *
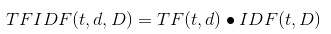
词频(Term Frequency):某关键词在文本中出现次数
逆文档频率(Inverse Document Frequency):大小与一个词的常见程度成反比
TF = 某个词在文章中出现的次数/文章的总词数
IDF = log(查找的文章总数 / (包含该词的文章数 + 1))
TF-IDF = TF(词频) x IDF(逆文档频率)