功能:文本实体标注,用于做ner nre等的训练测试集;
工具:python2
输入:
输出:
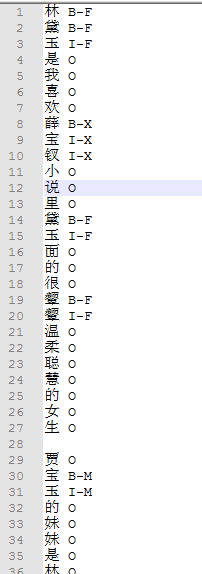
脚本:
#!/usr/bin/python
# -*- coding: utf-8 -*-
"""
@author:
@contact:
@context:对每行每个实体做清洗,其中每个实体需要从第一个字开始依次滑动遍历查找。
"""
import sys,xlrd
reload(sys)
sys.setdefaultencoding("utf-8")
#数据读入
data=xlrd.open_workbook(r'C:/Users/Administrator/Desktop/1/1.xlsx')
table = data.sheets()[0]
#数据的行列
nrows=table.nrows
ncols=table.ncols
L_final=[]
for k in range(1,nrows):
#下面缩进模块是对某一行的处理
text=table.row_values(k)[2]
text_list=list(text)
type_ner=range(0, len(text_list))
#第k行实体对应的类型
nrows_type=str(table.row_values(k)[1])#<type 'str'>
#看第k行实体个数
nrows_list_qukong=list(filter(None,table.row_values(k)))
nrows_len=len(nrows_list_qukong)
#for:对第k行的实体做标注
for i in range(3,nrows_len):
#缩进里是对第k行第i个实体做了完整遍历
entity=table.row_values(k)[i]
#计算实体元素的个数,unicode和非unicode(浮点)用不同的计算方式
if isinstance(entity, unicode)!=True:
len_a = len(list(str(int(entity))))
else:
len_a = len(list(entity))
search = str(entity)
start = 0
while True:
index = text.find(search, start)
if index == -1:
break
# print(index,index+len_a-1)
index_s = index
index_e = index+len_a
for j in range(0, len(text_list)):
if j in range(index_s, index_e):
if j==index_s:
type_ner[j] = str("B-"+ str(nrows_type) +"")
else:
type_ner[j] = str("I-"+ str(nrows_type) +"")
elif start !=0 or i>3:
print("非首次标注")
else:
type_ner[j] = str("O")
start = index + 1
# print(type_ner)
#对第k行遍历其他类型的实体
for entity in [u'薛宝钗']:
# 计算实体元素的个数,unicode和非unicode(浮点)用不同的计算方式
if isinstance(entity, unicode) != True:
len_a = len(list(str(int(entity))))
else:
len_a = len(list(entity))
search = str(entity)
start = 0
while True:
index = text.find(search, start)
if index == -1:
break
# print(index,index+len_a-1)
index_s = index
index_e = index + len_a
for j in range(0, len(text_list)):
if j in range(index_s, index_e):
if j == index_s:
type_ner[j] = str("B-X")
else:
type_ner[j] = str("I-X")
start = index + 1
final_result = []
for i in range(0, len(text_list)):
text_list = [str(x) for x in text_list]
type_ner = [str(x) for x in type_ner]
final = ' '.join([text_list[i], type_ner[i]])
final_result.append(final)
final_result.append(' ')
L_final=L_final+final_result
end = '\n'.join(L_final)
with open('etl_dataset.txt', 'w') as f:
f.write(end)