html代码如下
<h1>登鹳雀楼</h1>
<div class="poem-detail-header-info">
<a class="poem-detail-header-author" href="/s?wd=王之涣">
<span class="poem-info-gray">【作者】</span>王之涣
</a>
<span class="poem-detail-header-author">
<span class="poem-info-gray">【朝代】</span>唐
</span>
<div class="body-means-change">
译文对照
</div>
</div>
<div class="poem-detail-separator"></div>
<div class="poem-detail-item-content">
<p class="poem-detail-main-text" id="body_p">
<span id="body_1_0" data="means_1_0"><em><span class='body-zhushi-span' data='"\u592a\u9633\u3002"'>白日</span><span class='body-zhushi-span' data='"\u4f9d\u508d\u3002"'>依</span>山尽,</em></span><span id="body_1_1" data="means_1_1">黄河入海流。</span> </p>
<p id="means_p" class="poem-detail-main-text body-means-p">
<span id="means_1_0" data="body_1_0">夕阳依傍着西山慢慢地沉没,</span><span id="means_1_1" data="body_1_1">滔滔黄河朝着东海汹涌奔流。</span> </p>
<p class="poem-detail-main-text" id="body_p">
<span id="body_2_0" data="means_2_0"><span class='body-zhushi-span' data='"\u60f3\u8981\u5f97\u5230\u67d0\u79cd\u4e1c\u897f\u6216\u8fbe\u5230\u67d0\u79cd\u76ee\u7684\u7684\u613f\u671b\uff0c\u4f46\u4e5f\u6709\u5e0c\u671b\u3001\u60f3\u8981\u7684\u610f\u601d\u3002"'>欲</span><span class='body-zhushi-span' data='"\u5c3d\uff0c\u4f7f\u8fbe\u5230\u6781\u70b9\u3002"'>穷</span>千里目,</span><span id="body_2_1" data="means_2_1"><span class='body-zhushi-span' data='"\u66ff\u3001\u6362\u3002\uff08\u4e0d\u662f\u901a\u5e38\u7406\u89e3\u7684\u201c\u518d\u201d\u7684\u610f\u601d\uff09"'>更</span>上一层楼。</span> </p>
<p id="means_p" class="poem-detail-main-text body-means-p">
提取效果
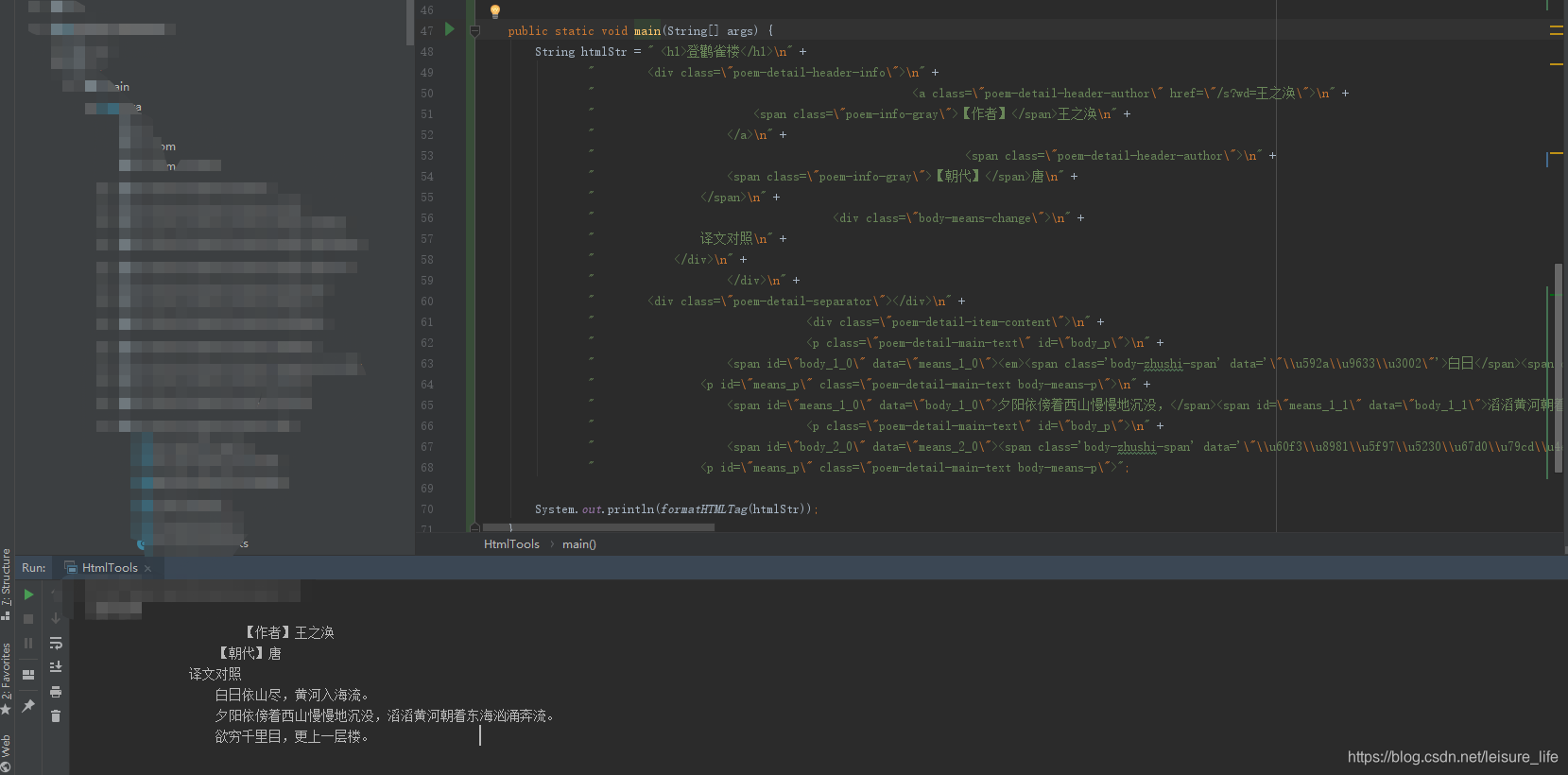
java代码
private static final String regEx_script = "<script[^>]*?>[\\s\\S]*?<\\/script>"; // 定义script的正则表达式
private static final String regEx_style = "<style[^>]*?>[\\s\\S]*?<\\/style>"; // 定义style的正则表达式
private static final String regEx_html = "<[^>]+>"; // 定义HTML标签的正则表达式
/**
* @param htmlStr
* @return 删除Html标签
*/
public static String formatHTMLTag(String htmlStr) {
Pattern p_script = Pattern.compile(regEx_script, Pattern.CASE_INSENSITIVE);
Matcher m_script = p_script.matcher(htmlStr);
htmlStr = m_script.replaceAll(""); // 过滤script标签
Pattern p_style = Pattern.compile(regEx_style, Pattern.CASE_INSENSITIVE);
Matcher m_style = p_style.matcher(htmlStr);
htmlStr = m_style.replaceAll(""); // 过滤style标签
htmlStr = htmlStr.replaceAll("<br\\/>", "\n");// 换行替换
htmlStr = htmlStr.replaceAll("</p>", "\n");// 段落替换
Pattern p_html = Pattern.compile(regEx_html, Pattern.CASE_INSENSITIVE);
Matcher m_html = p_html.matcher(htmlStr);
htmlStr = m_html.replaceAll(""); // 过滤html标签
htmlStr = htmlStr.replaceAll(" ", "");
htmlStr = htmlStr.replaceAll("&", "&");
Pattern p = Pattern.compile("(\r?\n(\\s*\r?\n)+)");//多个换行替换成一个
Matcher m = p.matcher(htmlStr);
htmlStr = m.replaceAll("\r\n");
return htmlStr; // 返回文本字符串
}