快速排序是一种应用非常广泛的算法,它流行的原因首先就是快,在时间复杂度为O(NlogN)的几种算法中,它的效率较高,此外它的实现简单并且能够原地排序(不实用辅助数组),与归并一样,快速排序也使用了分治的思想,因此貌似很多公司面试都喜欢考这个。
基本思想
1、先从数列中取出一个数作为切分元素。
2、对数组进行切分,比切分元素小的数放在左边,比它大的放在右边。
3、对左右区间重复第二步(递归地),直到区间只有一个数。
如图:

算法的关键部分是切分的过程,如下,它实现了对数组的原址重排。
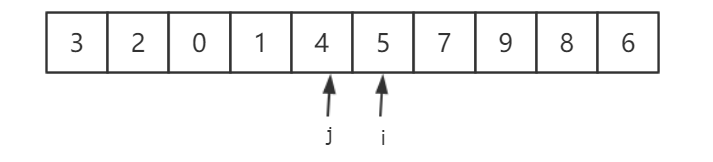
切分开始前,我们将数组打乱后,选取第一个元素 4 为切分元素,此时两个指针 i、j 分别指向位置待切分元素的两端。

首先,我们将 i 向右移动直到发现一个大于 4 的值 6,再将 j 向左移直到发现一个 小于 4 的值 0,并将它们两个交换。
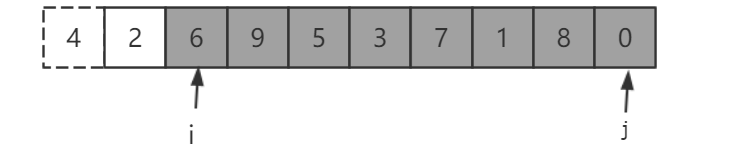
继续将 i 右移,j 左移,并将 9 和 1 交换,可以看到 i 走过的区域都是小于 4 的,同样 j 走过的区域都是大与 4 的。
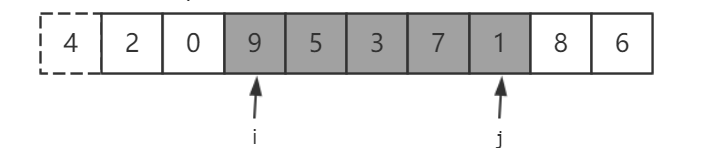
继续移动 i 和 j ,并将 5 和 3 交换。
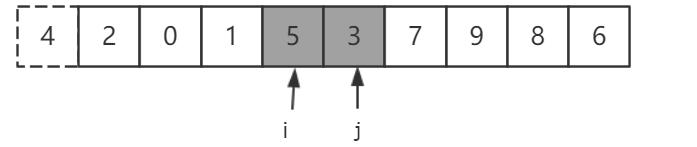
继续移动i 和 j,此时 i 已经和 j 相遇过了,交换 j 和 切分元素 4。
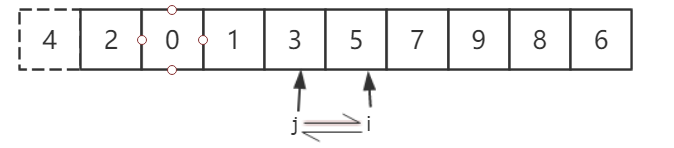
得到切分后的数组。
快速排序的切分方法的内循环用递增的索引将数组元素和一个定值比较,这种简洁性也是快速排序的一个优点,很难得排序算法中有这么小的内循环。归并排序和希尔排序一般都比快速排序慢,因为它们还要再内循环中移动数据
上个动图来直观感受一下排序的过程
代码实现
mport java.util.Random;
public class QuickSort {
public static void main(String[] args) {
Random ra = new Random();
int a [] = new int[15];
for(int i=0;i<15;i++) { //15个随机元素的数组,保证输入是随机的,就不用将数组打乱了
a[i] = ra.nextInt(15)-5;
}
sort(a); //调用sort来驱动quickSort()
for(int num:a) {
System.out.print(num+" ");
}
}
private static void sort(int[] a) { //quickSort的驱动例程,如果输入不是随机的话
quickSort(a, 0, a.length-1); //可以在这里调用方法把数组打乱
}
private static void quickSort(int[] a,int left,int right){
if(right<=left) return;
int p = partition(a, left, right); //切分
quickSort(a, left, p-1); //对左半部分排序
quickSort(a, p+1, right); //对右半部分排序
}
private static int partition(int[] a, int left, int right) {
int i = left;
int j = right+1;
int p = a[left];
while(true) { //将 i 右移,j 左移,找到合适元素停下,并交换元素
while(a[++i] < p) if(i==right) break;
while(a[--j] > p) if(j==left) break;
if(i>=j) break; //当 i、j 相遇后结束
exchange(a, i, j);
}
exchange(a, left, j); //最后一步,将 j 和 切分元素交换
return j;
}
private static void exchange(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
保持随机性
为什么快速排序要先把元素的顺序打乱?
因为保持元素的随机性让我们能够将排序的时间控制在O(NlogN),如果输入的数据是预排序了的话(预先排序的数据很常见),如果我们不将它打乱,那么根据排序的过程,我们每次都会选取第一个数作为切分的元素,那么每一次切分过程中,某一边只会有一个数,并且这种情况会发生在每一次递归排序中,此时排序的时间将会是 N2级别的,然而算法实际上并没有发挥出什么作用,这就很尴尬了。
切分元素选取
因此你可能会想,为何我们要把数组打乱再取第一个元素,将数组随机排列所用的开销也不小啊,不如直接取中间的数好了。
这种想法类似于取数组的中位数切分,切分元素的最好的选择自然是数组的中值,但是算出这个中值同样也相当耗费时间,使用这种方法的的效果还不如选取随机的元素,有研究结果表示,取随机的分割元素,平均下来一般也会在中值附近。
算法改进
1、使用插入排序
众所周知,对于小规模的数组,快速排序是不如插入排序的,因此在对小数组排序的时候应该自动切换到插入排序。
2、三向切分(较多重复元素)
实际应用中我们的输入数组可能包含许多重复元素,如我们可能需要将用户资料按照生日、性别排序,此时我们的算法就会有点愚钝,比如一个子数组中全都是重复元素,那我们其实不用对它再排序了,可是快速排序会继续将它排序,递归地做着一遍又一遍的无用功。
三向切分的快速排序通过维护四个指针,将数组切分为三个部分,分别大于、小于、等于切分元素,使得该算法在面对大量重复元素的排序时将时间从线性对数级别降低到了线性级别。
总结
虽然快速排序很快,但是这是要考虑综合情况的,对于大规模的随机数列,它的排序时间能比同样是基于元素比较的归并排序还快,但是对于小规模数列,它的效率可能还不如插入排序,亦或是输入序列部分排序的话,它的表现也会不如插入排序。