文章目录
1. 正则化
1.1 过拟合概念
就是模型在训练集上表现的过于完美
过拟合说明模型不够通用,如果将数据应用在新的数据上,得到的效果比在训练集上差,甚至要差很多
一般认为参数越小越好,参数很小的话如果数据变动很大将对结果产生更小的影响。
1.2 L2、L1正则化
1.2.1 L2正则化
惩罚函数表达式为
目标函数 加上惩罚函数
α为正则化超参数,又称权重衰减因子,取值范围在[0,正无穷)
加上惩罚项之后梯度更新 ,即
相比于未加L2正则项时
来说参数是不断减小的
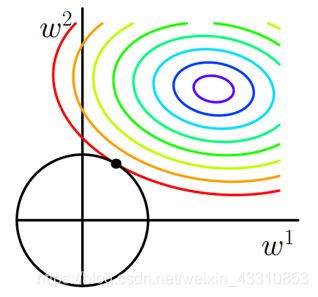
我们首先假设
惩罚函数
彩色部分为目标函数的等高线,越往中心(蓝色)代价函数
越小,加入乘法函数就是给参数加一个约束,使得
最小,比原来达到了减小参数的目的。另外在J和
第一次相交的地方取到最优解。如果超参数
越大,最优点将会增加靠近原点。
1.2.2 L1正则化
惩罚函数表达式为
设目标函数J添加L1正则项
,
为超参数
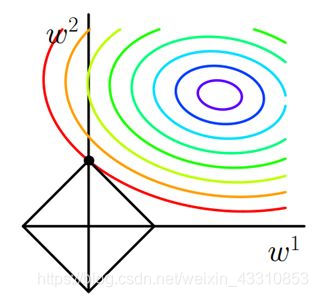
设
J与
交在
,这就是L1正则化产生稀疏模型的原因。
1.3 增加数据量
在一些领域(图像和语音识别)通过水平或者垂直翻转图像、裁剪、色彩变换、扩展和旋转等数据增强技术来增加数据量
利用生成对抗网络可以自动生成样本,并添加到训练集中
1.4 梯度裁剪
遇到目标函数悬崖地带梯度参数更新可以将参数抛出很远,效果不一定理想。
我们可以采用梯度裁剪,(也就是将梯度限制在一个确定的范围之内,就能避免参数被抛出很远或者远离极小值)[-limit,limit]
1.5 提前终止
训练过程在循环过程当验证误差没有进一步改善或者指定循环步数时停止循环,提前终止
例如当accuracy>0.98时终止循环
1.6 共享参数
L1正则化或者L2正则化是通过在目标函数增加惩罚项,使权重参数彼此靠近,使权重参数都向源点靠近
从另一个方面来说就是使权重参数彼此靠近,如通过某种约束强制某些参数相等,具体表现为训练模型时
共享一组参数,这种正则化方法称为共享参数,可以大大降低参数量,节约内存资源。
1.7 dropout
1.7.1 概念
在训练过程中按比例随机忽略或者屏蔽一些神经元,也就是说他们在正向传播过程对于下游神经元的贡献暂时消失了
反向传播时该神经元不会有权重的更新。通过传播过程,dropout将产生和L2范数相同的收缩权重的效果
复杂的协同适应:在训练的过程中神经元的权重针对某些特征进行调优会产生一些特殊化。周围的神经元会依赖这种特殊化
模型会因为训练数据过拟合而变得脆弱不堪。神经元在训练过程中这种依赖上下文的现象被称为复杂的协同适应
complex co-adaptation
加入了dropout后输入的特征都有可能被随机消除,随意该神经元不会再特别依赖于任何一个输入特征
也就是不会再给与任何一个输入设置过大的权重。网络模型对神经元特定的权重不那么敏感。反过来提高了模型的泛化能力
1.7.2 dropout的原则
(1):通常丢弃率在20%~50%比较好,比例太低效果不太好,比例太高会导致模型的欠学习
(2):在大的网络模型上应用,当dropout用在较大的网络模型时更有可能得到效果的提升,模型有更多的机会学习到多种独立的表征
(3):在输入层和隐藏层都是用dropout。对于不同层,设置的keep_prob也不同,一般来说神经元较少的层
会设置keep_prob为1.0或者接近1.0的数。神经元多的层,则会将keep_prob设置的比较小比如0.5或者更小
(4):增加学习率和冲量。把学习率扩大
倍,冲量值调高到0.9~0.99
(5):增加网络模型的权重。大的学习率往往导致大的权重值,对网络权重做最大范数的正则化,可以提高模型性能
2. 预处理
2.1 初始化
传统机器学习很多不是采用迭代式优化,因此需要初始化的内容不多
但是深度学习算法一般采用迭代方法,参数多层数多,很多算法在不同程度上会受到初始化的影响
初始化能决定算法是否收敛,如果初始化不适当,初始值过大可能会导致在前向传播中或者反向传播中导致很大的值;初始值过小可能会导致丢失信息。
对收敛算法进行合适的初始化可以加快收敛速度
一般有正态分布、正交分布、均值分布的初始化能带来较好的效果
2.2 归一化
有min-max标准 Z-score标准化方法
归一化数据都在[0,1]之间,目标函数等高点均匀,收敛步数比较少,归一化能提高精度
使用归一化场景为:
(1):需要使用距离来度量相似性
(2):数据不符合正态分布或者均匀分布时,比如在对图像处理时
3. 批量化
1、一般采用mini-batch梯度下降法 m一般取值10-500
2、批标准化
数据归一化一般是针对输入数据而言,但在实际训练过程中,经常出现隐含层数据分布不均,导致梯度消失或者不起作用
BN是针对隐藏层的标准化处理,它与输入的标椎化处理是有区别的。
一般在神经网络训练中遇到收敛速度很慢,或者梯度爆炸等无法训练的状况时,可以尝试使用BN算法
BN的具体功能:
(1):可以选择比较大初始学习率,提高训练速度飙升。学习率的缩减速度很大,BN算法具快速训练收敛的特性
(2):不用再去理会过拟合的dropout,L2正则项参数的选择问题,采用BN算法之后可以不用考虑这两个问题,BN 具有提高网络泛化能力的特性
(3):不需要局部相应归一化层
(4):可以把数据随机化打乱
import tensorflow as tf
scale= tf.Variable(tf.ones([1]))
shift=tf.Variable(tf.zeros([1]))
e=0.001
xs=tf.nn.batch_normalization(xs, fc_mean, fc_var, shift, scale, shift, e)
4. 并行化
4.1 深度学习并行模式
分为同步模式和异步模式
在每一轮迭代时,不同设备首先统一读取当前参数值,并随即获取一小部分数据,然后在不同设备上运行反向传播过程
得到各自训练数据上参数的梯度,因为训练数据的不同,训练出来的参数就不同
异步模式:每个设备独立更新参数
同步模式:等所有设备计算出参数之后再用所有参数各自的平均值来对参数进行更新
数据量比较小时建议使用同步模式
数据量比较大时建议使用异步模式
5. 选择合适的激活函数
推荐这篇文章,写的比较全 激活函数以及什么时候使用它们?
6. 选择合适的代价函数
训练模型的过程就是优化代价函数的过程,代价函数对每个参数偏导就是梯度下降中提到的梯度,防止过拟合,添加的正则化项也是加在代价函数后面。
代价函数是用来衡量模型预测值和真实值之间差异的函数,代价函数越小说明模型和参数越符合训练样本。
6.1 均方误差
回归问题一般用均方误差
tensorflow里面一般会用reduce_mean/reduce_sum来计算均方误差,下面来介绍一下
reduce_mean(input_tensor,#待降维的Tensor
axis=None,#对指定维进行降维,如果不指定就计算所有元素的平均值
keep_dims=False,#是否降维,True不降维输出结果保持tensor形状设置为false输出结果会降低维度
name=None,#操作的名称
reduction_indices=None)
-
reduction_indices=[0] or axis=[0]是将一行作为一个可操作的对象,一行一行相加总和得一行数据
reduction_indices=[1] or axis=[1]是将一列作为一个可操作的对象,一列一列相加总和得一列数据 -
例如
reduction_indices=[0] or axis=[0]时reduce_sum(a)即
reduction_indices=[1] or axis=[1]时reduce_sum(a)即
6.2 交叉熵
分类问题一般用交叉熵
p(x)表示正确答案,q(x)表示预测值
所以在mnist图像识别项目中交叉熵为
7. 选择合适的优化算法
可以在迭代次数150步之内先采用adm找出合适的参数,然后切换到SGD+动量优化