一,进程的概念
进程是已启动的可执行程序的运行实例。是程序运行的过程,是动态的,有生命周期。通常通过进程的ID(PID)号来标记每一个进程。
二,进程
2.1 进程信息被放在一个叫做进程控制块的数据结构中,可以理解为进程属性的集合。PCB(process control block),Linux操作系统下的PCB是: task_struct。
2.2 由于与进程相关的事情非常多,比如进程间状态,进程的优先级,进程的地址空间等等。Linux内核专门为此设计了一个类型为task_struct的结构体,称之为进程描述符。task_struct是一个很大的结构体,包含许多内容。它位于操作系统内核,由操作系统内核产生。一个进程对应一个task_struct。
2.3 task_ struct内容分类
(1)进程标示符: PID,每一个进程都有一个唯一标示符,用来区别其他进程。
getpid()是一个系统调用函数----->获取当前调用进程的pid
getppid()------->获取当前进程的父进程的pid
(2)内存指针: 包括程序代码和进程相关数据的指针,还有和其他进程共享的内存块的指针。告诉进程代码和数据位于内存的那个部分。
(3)优先级: 相对于其他进程的优先级。
可通过top[PID]的命令来查看进程的优先级。(PR:表示进程的优先级)表示这个进程是先被调度执行还是后被调度执行,数字越小,优先级越高。(PR(优先级)+NI(修正值))==最终的PR)
通过指令是可以调整nice值,宏观上往往看不出效果。在root用户中top/r来进行修改。修改范围为:-20~19总共40个级别
(4)上下文数据: 进程执行时处理器的寄存器中的数据,CPU可能由几十个寄存器,保存上下文,CPU寄存器的内容保存到内存中,恢复上下文,就是把内存中的寄存器值恢复到CPU中。
(5)记账信息: 可能包括处理器时间总和,使用的时钟数总和,时间限制,记账号等。每个进程已经在CPU上执行了多久统计数据。
(6)程序计数器: 程序中即将被执行的下一条指令的地址.
(7)I/O状态信息: 包括显示的I/O请求,分配给进程的I/O设备和被进程使用的文件列表。
(8)进程状态: 任务状态,退出代码,退出信号等。
R:就绪状态reading, 进程在就绪队列中就会处于这个状态
S:睡眠状态,该进程正处于睡眠当中,但可被某些讯号(signal)唤醒
D:深度睡眠状态,密集进行IO操作(输入输出操作)的时候(吐coredump文件的时候),不可中断状态。
T:暂停状态stop,使用kill命令是不能结束当前进程的。该进程正在侦测或已经停止。
t :跟踪trace,使用gdb调试的时候
X:进程已经结束,只是在Linux源码中存在,真实是看不到的
Z:僵尸状态。该进程已经终止,当是其父进程却无法正常终止它,造成(zombie)状态
(9)其他信息
2.4 组织进程
使用双向链表进行组织,每一个节点就是一个task_struct。所有运行在系统里的进程都以task_struct链表的形式存在内核里。
2.5 查看进程的指令
(1)ps
ps相当于任务资源管理器,能够查看系统上有哪些进程
ps aux :查看所有进程
ps aux | less:对查看结果进行翻页和其他操作
ps aux | grep[进程名] :查看匹配的进程 (grep进行一个字符串的筛选)
ps -ef :用标准格式显示进程
(2)top[PID]
(3)cd /proc/扫描二维码关注公众号,回复: 11624582 查看本文章
敲下的命令,在命令的指向过程中,也是一个进程。进程和可执行程序没有关联
2.6 进程的分类
CPU密集型:一个进程在大量占用CPU资源进行逻辑运算或算数运算
IO密集型:有大量的input和output操作的程序
2.7 进程的调度:让少量的CPU能够满足大量的进程同时执行的需求
并行:同一时间,两个CPU分别执行两个进程
并发:同一时间,一个CPU分别执行两个或多个进程
三,僵尸状态
僵尸状态(Zombies)
是一个比较特殊的状态。当进程退出并且父进程没有读取到子进程退出的返回代码时就会产生僵尸进程。僵尸状态会以终止状态保持在进程表中,并且会一直在等待父进程读取退出状态代码。所以,只要子进程退出,父进程还在运行,但父进程没有读取子进程状态,子进程进入Z状态。
3.1 成因:子进程需要将一些资源释放,需要父进程来进行回收,如果父进程一直忙,来不及回收,那就会造成子进程资源释放不掉,会造成子进程PCB残留在内核中。
3.2 危害:可能占用许多的内存,可能导致内存泄漏(1,PCB还残留在内核中 2,PCB结构体中的一些内存没有释放掉 3,kill -9[pid] 也是无效的 4,当出现大量的僵尸状态的进程是,会对操作系统造成压力)
3.3 处理:直接kill僵尸进程是无法kill掉的,可以kill僵尸进程的父进程。(更科学的处理办法:进程等待)kill掉父进程之后,子进程就成为了孤儿进程,孤儿进程会被1号进程收养,从而释放资源。
孤儿进程:不是一种进程的状态(是一种特殊的情况),指的是父进程结束了但子进程没有结束,这是子进程的父进程就变成了1号进程(init进程)systemd。1号进程负责回收子进程的资源。
四,进程的创建
4.1 创建子进程:fork()函数
#include <unistd.h>
pid_t fork(void);
pid_t fork(void):
pid_t vfork (void):
同样是创建一个子进程,但是它与父进程共用一块虚拟空间,子进程先运行,等到子进程exit(0)的时候父进程才能运行。
创建进程时与父进程共享同一块地址空间,创建效率很高。fork实现了写实拷贝技术,大大提高了效率且进程独立,因此vfork就被淘汰了。
4.2 fork的运行规则:以父进程为模板,创建子进程
1,会把父进程的PCB拷贝一份,稍加修改,成为子进程的PCB(进程控制块)
2,会把父进程的虚拟地址空间拷贝一份,作为子进程的地址空间
(写时拷贝:按浅拷贝拷,在进行改变的时候在触发深拷贝,提高效率)父子进程共用一份代码,各自有一份数据
由于大部分的内存空间都可能被拷贝,创建进程的开销依然比较高(和线程相比)
在有些场景下,线程的创建也会被认为开销比较大(和协程相比(Golang入手))
3,fork返回会在父进程中分别返回:父进程返回子进程的pid,子进程返回0,在fork后面继续往下执行。
4,父子进程执行的先后顺序:不确定,取决于操作系统的调度器(抢占式执行:父子进程谁先获得CPU资源谁就先执行)
5,fork失败返回-1,原因:内存不够,进程太多
五,进程的终止
5.1 进程退出场景:
1,代码执行完结果正确
2,代码执行完,结果不正确
3,代码没执行完,异常终止
5.2 进程常见退出方法
正常终止:
(可以通过 echo $? 查看进程退出码,退出码为0表示结果正确,退出码非0表示结果错误)
- 从main返回
- 调用exit((库函数)本质上也是调用了_exit(1,exit关闭流刷新缓存区 2,exit还多调用了结束函数))
- _exit(系统调用)
异常退出:ctrl + c,信号终止
六,进程等待
1,为什么要有进程等待
子进程退出,父进程如果不管不顾,就可能造成‘僵尸进程’的问题,进而造成内存泄漏。另外,进程一旦变成僵尸状态,那就刀枪不入,“杀人不眨眼”的kill -9 也无能为力,因为谁也没有办法杀死一个已经死去的进程。最后,父进程派给子进程的任务完成的如何,我们需要知道。如,子进程运行完成,结果对还是不对,或者是否正常退出。父进程通过进程等待的方式,回收子进程资源,获取子进程退出信息。
2,进程等待:
父进程对子进程进行进程等待,等待是为了读取子进程的运行结果
3,进程等待的方法
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int*status);
wait是一个阻塞式函数:
1,参数是输出型参数,获取等待的进程的返回状态(表示退出码(倒数第二个字节,无符号类型)+正常/异常退出(最低一个字节,正常退出时0,异常退出时非0))
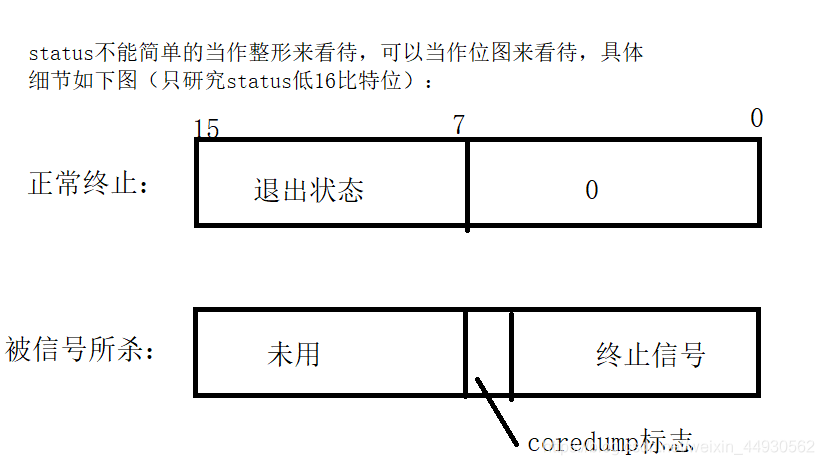
2,返回值是子进程的pid
3,wait阻塞式等待,一直等到子进程结束才返回(直到子进程结束,才会返回wait函数的返回值)
wait的注意事项:
1,wait的调用次数必须和子进程的个数一致
wait的调用次数比较少,有些进程不能被回收就导致了僵尸进程
wait的调用次数比较多,多出来的wait就会调用出错
2,wait在进行进程等待的时候,如果有多个子进程,任何一个子进程结束都会触发wait的返回
waitpid:能够等待某个指定子进程的退出
pid_ t waitpid(pid_t pid, int *status, int options);
行为和wait非常相似(返回值规则,status参数)
参数:
pid_t pid
-1:等待任意子进程
>0:等待子进程pid等于参数pid1值的进程
int * status
输出型参数,子进程的退出码
int option
0:阻塞 WNOHANG:非阻塞
返回值:
-1,调用中出错,这时errno会被设置成相应的值以指示错误所在;
0-----非阻塞模式下,要配合循环来使用 直到等到子进程。如果设置了选项WNOHANG,而调用中waitpid发现没有已退出的子进程可收集,则返回0;
大于0----正常取到子进程的退出状态
waitpid(-1,NULL,0)就和wait(NULL)是等价的。
waitpid(-1,NULL,WNOHANG)已经变成了非阻塞式等待
非阻塞轮询式的wait
优点:能够更灵活的控制代码,充分利用等待时间去做其他事情
缺点:代码复杂
七,进程的程序替换:
fork创建出的子进程和父进程是共用同一套代码。而事实上我们更需要的是创建出的子进程能够执行一份单独的代码
1,程序替换不会创建新进程,也不会销毁进程
2,程序替换替换代码和数据(从一个可执行文件中来)
3,原有的堆和栈中的数据就全都不要了,根据新的代码的执行过程重新构建堆和栈的内容
类似于双击exe执行一个程序的过程(操作系统的加载器模块)涉及程序替换的库函数: exec 函数族 (参数有差异,底层原理完全相同) l=>list变长参数列表, v=>vector数组
exec函数族执行只有一个返回值,当调用出错的时候,返回-1,当调用成功的时候,没有返回值,因为程序已经替换成其他的代码和数据了,就不用返回了,主要的原因是代码段和数据段都被替换了。
execl(const char* path , const char* arg , …) 以NULL结尾
/usr/bin/ls , ls , -l , NULL
execlp(const char* file, const cha*arg, ….)(p表示PATH,会自动在PATH中查找)
execle(const char *path, const char *arg, ...,char *const envp[]);
用户进行程序替换的时候手动指定环境变量(这个数组必须也得用NULL结尾)
execv(const char *path, char *const argv[]);
execvp(const char *file, char *const argv[]);
execve
调用示范:
#include <unistd.h>
int main()
{
char *const argv[] = {"ps", "-ef", NULL};
char *const envp[] = {"PATH=/bin:/usr/bin", "TERM=console", NULL};
execl("/bin/ps", "ps", "-ef", NULL);
// 带p的,可以使用环境变量PATH,无需写全路径
execlp("ps", "ps", "-ef", NULL);
// 带e的,需要自己组装环境变量
execle("ps", "ps", "-ef", NULL, envp);
execv("/bin/ps", argv);
// 带p的,可以使用环境变量PATH,无需写全路径
execvp("ps", argv);
// 带e的,需要自己组装环境变量
execve("/bin/ps", argv, envp);
exit(0);
}
程序替换经常要搭配fork来使用。一旦替换之后,就会把原来的进程的代码和数据都干掉,无法继续执行原来的代码了
八,环境变量
1,什么是环境变量
环境变量(environment variables)一般是指在操作系统中用来指定操作系统运行环境的一些参数。环境变量是一个键值对结构,键:变量,值:变量内容
2,常见环境变量
PATH : 指定命令的搜索路径,shell中敲下的指令,去哪些目录中查找对应的可执行程序
HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
SHELL : 当前Shell,它的值通常是/bin/bash。
3,怎么查看环境变量
env查看到系统上所有的环境变量
echo $(环境变量名)可以查看该环境变量的内容
4,和环境变量相关的命令
- echo: 显示某个环境变量值
- export: 设置一个新的环境变量
- env: 显示所有环境变量
- unset: 清除环境变量
- set: 显示本地定义的shell变量和环境变量
- export PATH=$PATH: 修改环境变量,对于PATH修改一般只是进行追加,不会把原来的内容去掉。可以通过重启终端(或source ~/.bash_profile ~/. bashrc)来恢复PATH,想让PATH永久的修改就需要改动一个文件~/.bashrc
5,通过代码如何获取环境变量
1,命令行第三个参数
#include <stdio.h>
int main(int argc, char *argv[], char *env[])
{
int i = 0;
for(; env[i]; i++){
printf("%s\n", env[i]);
}
return 0;
}
2,通过第三方变量environ获取
#include <stdio.h>
int main(int argc, char *argv[])
{
extern char **environ;
int i = 0;
for(; environ[i]; i++){
printf("%s\n", environ[i]);
}
return 0;
}
3,通过系统调用获取或设置环境变量
#include <stdio.h>
#include <stdlib.h>
int main()
{
printf("%s\n", getenv("PATH"));
return 0;
}
)
argc:命令行个数
argv[]:命令行分别是什么
env[] :所有的环境变量,env数组中也有一个结束标志NULL
char* result=getenv(“PATH”);通过getenv函数来获取PATH的环境变量
九,程序地址空间
1,栈和堆的区别
如果是大对象,必须在堆上分配。
如果是小对象,并且需要频繁创建和销毁,推荐在栈上分配。栈上分配内存更高效,栈上是通过esp寄存器修改来进行栈上内存的创建和销毁,堆上分配内存就比较复杂,如malloc底层实现
2,进程地址空间
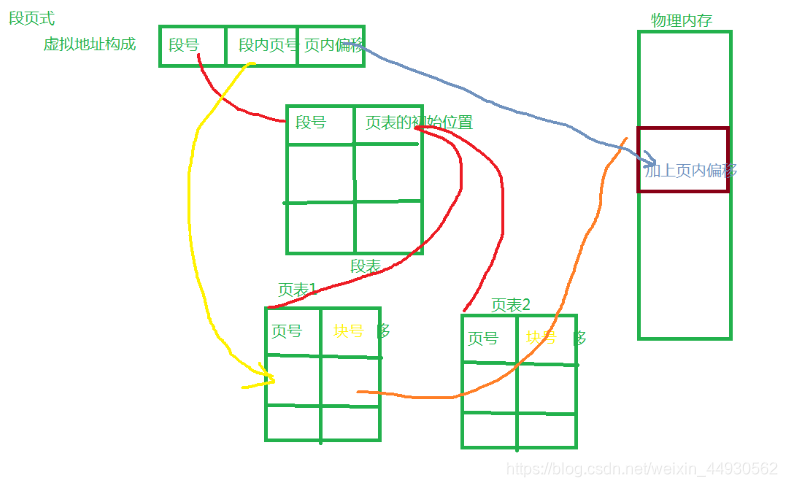
1,分页式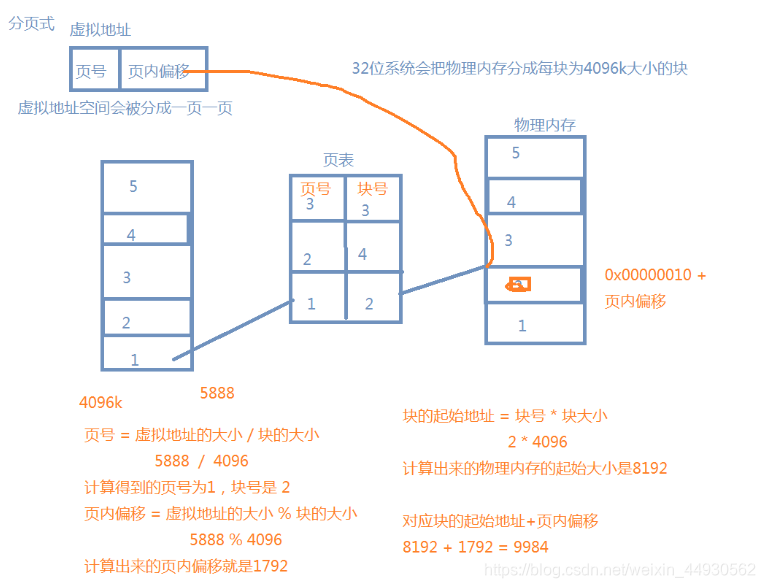
2,分段式

3,段页式