在五月份的时候,我写了一篇关于今日头条的爬虫, 五月头条爬虫, 然后最近有些朋友说这个代码用不了了, 不能实现爬虫功能了,其实这很正常呀, 都隔了这么长时间(2个月),网站可能会有点变化,加上之前技术不是很成熟,有些代码也不是很健壮,所以这次打算写一次头条爬虫修正版!
时间 : 2020年 8月 沙漏在下雨
本次爬虫涉及到模块 : request库, 正则re, os模块, time模块,多线程, 多请求头等, 加强了代码的健壮性,和统一性, 等于重写了一次这个代码, 废话不多话, 老规矩, 上图,上代码, 上思路!

本篇博客思路上和之前写的大致相同, 如果不想阅读新的方式, 可以直接点击链接,
跳转旧的方法 : 五月头条爬虫
或者: 博主其他文章
八月头条爬虫
简单的多线程:
之前是搭建进程池, 然后这次换成了多线程的方式, 更加ok感觉。
import threading
# 开启方式
page_num = [i * 20 for i in range(15)]
for i in range(5): # 线程多开 次数越大
t = threading.Thread(target=self.spider, args=(page_num.pop(0),))
print(f"开启线程{i}中......., 正在加速中")
t.start()
t.join()
time.sleep(0.7)
关于 target 接 一个执行函数, args 是一个参数元组, 如果只有一个的话, 后面要加逗号,然后使用方法start() 用来启动一个线程, 使用join() 用来链接上一个线程的释放.
更多进程的知识点,还请各位大佬移步: 廖老师的课堂
Ajax数据爬取:
网址的很多信息都不会直接全部出现在源代码里面,比如你刷网页,那些新刷出的网页就是一个个的通过ajax接口加载出来的,这是一种异步加载方式,原始的页面不会包含很多数据,数据都放在一个个接口里面,只有我们请求这个ajax接口,然后服务器后台收到这个接口信息,才会把数据返回,然后JavaScript分析这个数据,在渲染到浏览器页面上,这就是我们看到的模式,
现在越来越多的网页都是采用这个异步加载的方式,爬虫就显得没那么容易了,这个概念的讲的也拗口,我们直接开始实战吧!
分析头条页面:
因为本次爬取的还是今日头条, 所以分析的过程,我就照搬之前写的文案了,至于哪里改动了, 在具体的细节中, 我会给出提示。
- 目标网址: 关键词:街拍
- https://www.toutiao.com/search/?keyword=%E8%A1%97%E6%8B%8D
- 目的: 获取标题 和图片下载地址.
那朋友们怎么知道一个网站是不是ajax接口,主要有三点:
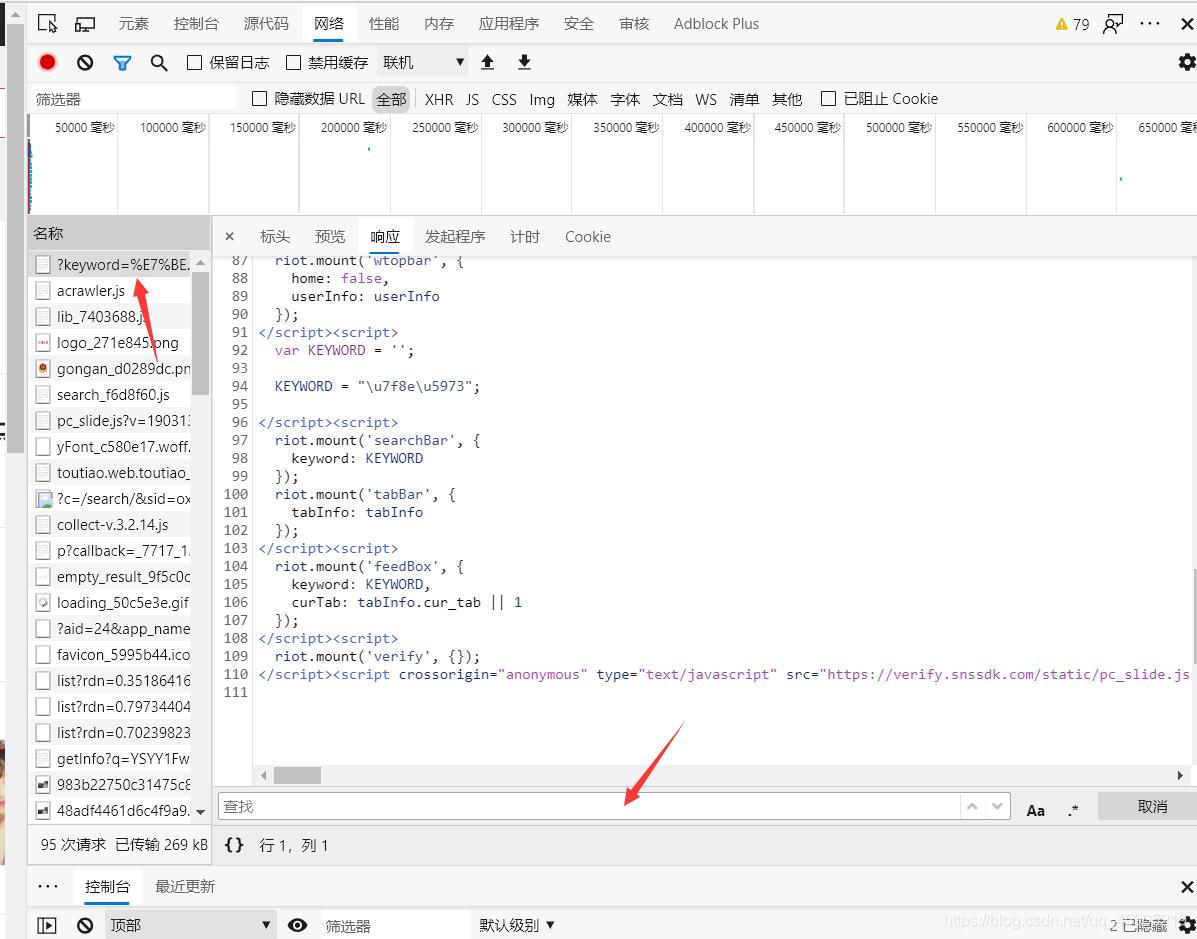
第一点:
注意我这几个箭头,只要你在这里·查找·里面找不到与文章对应的文字还是链接什么的,那就可能是。
第二点:
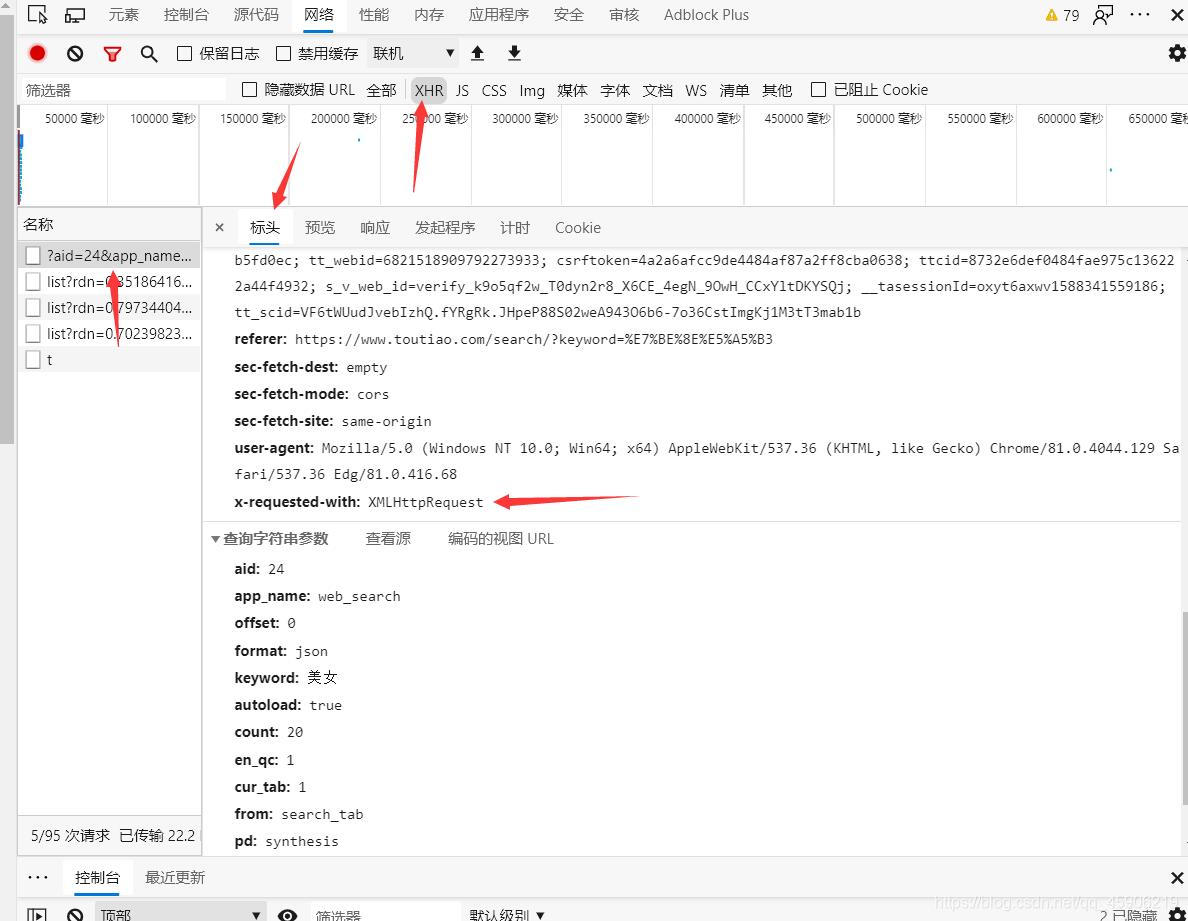
在这个XHR里面找到箭头的网址,点击,查看预览,这个时候你随意打开里面的东西,就能发现很多与文章相同的点

第三点:
还是这张图,你可以看到X-requested里面的接口是XMLHttpRequets
如果三点同时满足,那他就是Ajax接口,然后异步加载出来的数据。
第四点:
你在某个页面中, 一直滚动, 发现一直显示正在加载中,如图:

四点有二点满足, 大概率就是ajax接口了,就需要换一种方式去编写代码了。
获得数据:
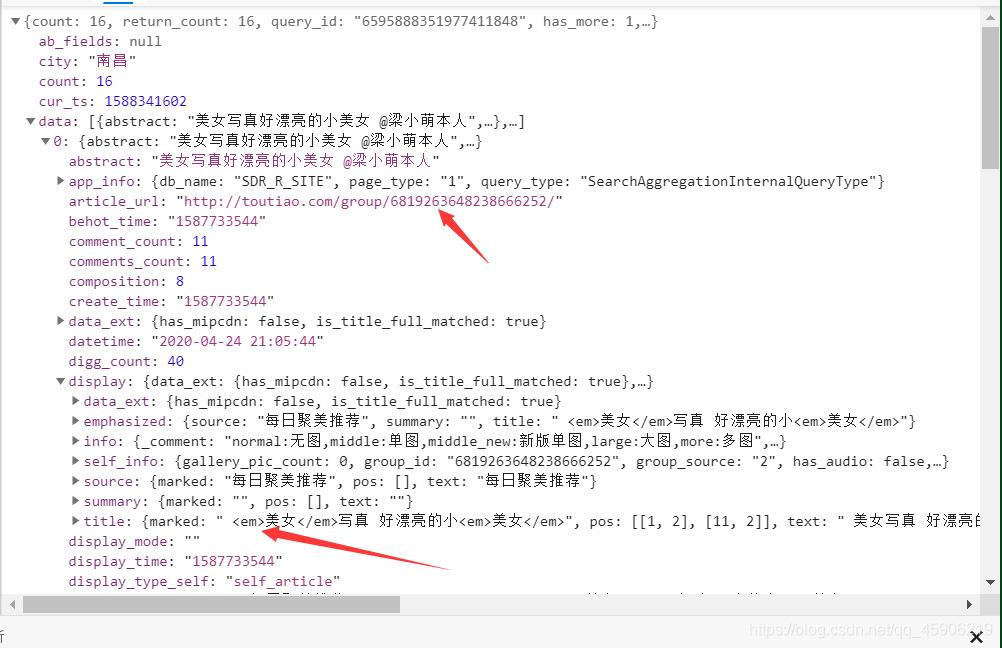
我们要怎么样的数据? 这些数据又保存在哪里?
在第二点的那张图我们可以看到有0,1,2,3,4,之类的,打开你会发现,都在这里面,图中我用箭头标红了,有标题和页面链接,只要获得这个页面链接,那么就很简单了。
编写代码:
程序初始化:
定义一些必备的参数
def __init__(self):
"""
配置基础设置
"""
self.url = "https://www.toutiao.com/api/search/content/?"
# 构造url
# 头信息 加入参数
self.user = UserAgent() # 多请求头
self.headers = {
'cookie': 'csrftoken=4a2a6afcc9de4484af87a2ff8cba0638; ttcid=8732e6def0484fae975c136222a44f4932; tt_webid=6862678326524839431; s_v_web_id=verify_ke1drmzk_z2TCIiBg_nLDJ_45eL_AblY_n6195E59w68S; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6862678326524839431; MONITOR_WEB_ID=b4a776dd-f454-43c6-81cd-bd37cb5fd0ec; __ac_signature=_02B4Z6wo00f01z-C1bAAAIBDQ4ILSJIdaYs.htEAAJDmAPYD1OTlD5KPRJ2LQh6uQ7Bo0bH5LFexApSHZucelY-7XrUsPNv5Rz4yMqyC5rHPH2wDXi7W7NLR5oTdt5MTb3p4g1WnOe3k1Stk3e; tt_scid=QA92vdakyjRvdp7mZyOW89R1Lj.7M2dX9noGBshXT8s0cqXYHXiuC32Rx7l2ZmdVa66a; __tasessionId=mr7tknawq1597911808662',
'user-agent': self.user.random,
'referer': 'https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3',
'x-requested-with': 'XMLHttpRequest'
}
def __params(self, offset):
"""构造字典"""
self.offset = offset
self.params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.offset), # 加 20
"format": "json",
"keyword": "街拍",
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": int(time.time()) # 时间参数
}
线程调用处:
也是为了加快程序的爬取效率, 用上了多线程。具体步骤如下:
def start_thread(self):
"""
开启多线程
"""
page_num = [i * 20 for i in range(15)]
for i in range(5): # 线程多开 次数越大
t = threading.Thread(target=self.spider, args=(page_num.pop(0),))
print(f"开启线程{i}中......., 正在加速中")
t.start()
t.join()
time.sleep(0.7)
主函数:
这个函数调用是通过线程来实现的, 只不过这个函数功能将其他的函数链接起来,达到效果就行。
def spider(self, count):
"""
开始爬取 params: count offset = offset + count * 20
"""
# 修改参数 offset
self.__params(count)
url = self.url + urlencode(self.params) # 构造参数函数
# 这次的url 非常正常 没有改变 有点顺利
r = requests.get(url, headers=self.headers)
if r.status_code == 200:
for content in self.parse_json(r.json()):
title, image_list = self.parse(content) # 解析得到标题和网址列表
if title == 'change':
continue
else:
self.down_image(title, image_list) # 下载图片 出口
else:
print(r.status_code)
分析json包得到数据:
- 我们在spider 中, 通过urlencode() 成功的将网址构造成功, 那现在只需要去请求这个网址, 就可以获得我们需要的json包了,代码如下:
def parse_json(self, json_package):
"""
解析每一个json包
"""
all_data = json_package.get("data")
if all_data: # 判空
for content in all_data:
title = content.get('title')
page_url = content.get('article_url')
# 这二种网址都可以打开同一个页面
# http://toutiao.com/group/6862530715892843021/ 这个是从json包提取出来的
# # https://www.toutiao.com/a6862530715892843021/ 这个是正常点进入的网址
items = {
"title": title, # 标题
"page_url": page_url, # 图集网址
}
if title and page_url: # 都存在
yield items
else:
print("requests timeout please wait !")
分析源代码得到标题和图片网址:
如果上面的代码没问题, 那现在我们就需要去请求之前得到的网址了, 通过这个网址,我们就需要获取真正有用的数据, 标题和图片网址, 代码如下:
def parse(self, content):
"""
解析每一个图集链接
"""
# 请求解析网址
r = requests.get(content.get('page_url'), headers=self.headers)
if r.status_code == 200:
pat = '<script>var BASE_DATA = .*?articleInfo:.*?content:(.*?)groupId.*</script>'
match = re.search(pat, r.text, re.S)
if match: # 如果上面获取成功 则这样写正则 经过测试 现在有新的源码 需要修改正则表达式
# 正确网址 https://p1-tt.byteimg.com/origin/pgc-image/c079d3c1f26b4001abcd5da5d5ed403b?from=pc
# 得到网址 https:\u002F\u002Fp1-tt.byteimg.com\u002Forigin\u002Fpgc-image\u002F54b8942a273d4e2e92c19c3044bafdc7?from=pc
# 对比区别 编码问题 存在小误差 先正则提取出来 进行接下来的操作
result = re.findall(r'img src=\\"(.*?)\\"', match.group(1), re.S)
# 得到图片列表地址
result_list = [i.encode('utf-8').decode('unicode_escape') for i in result] # 修改编码
return content.get('title'), result_list
else:
return 'change', 'it'
else:
print(r.status_code)
根据标题和网址下载图片:
- 有了之前得到的数据, 那现在就到了下载图片的环节了。 如下:
def down_image(self, title, img_list):
"""
下载图片 params: title img_list
"""
# 创建总目录
path = 'D://今日头条美女//' # 目录
if not os.path.exists(path): # 创建目录
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
# ------------------------------ ------------
# 对标题的进一步缩小处理
if '街拍' in title:
title = title.split(':')[-1]
title = title.strip().replace("\t", "")
# 创建分批目录 对目录标题进行细节处理
now_path = os.path.join(path, title)
if not os.path.exists(title):
os.mkdir(now_path + "//")
os.chdir(now_path + '//')
else:
os.chdir(now_path + '//')
# 开始下载图片
for index, value in enumerate(img_list):
r = requests.get(value, headers=self.headers)
if r.status_code == 200:
name = str(index + 1) + ".png"
with open(name, "wb") as fw:
fw.write(r.content)
print(f'{name} 下载完成, 保存在{os.path.join(path, title)}')
else:
print('下载失败', r.status_code)
print(f'系列 {title} 全套成功下载完成!')
print('- ' * 30)
好咯, 这就是本次八月更新的今日头条爬虫, 如果之后还会变化, 可以私聊告诉我,如果有帮助, 请点赞, 关注, 加收藏,
全部代码:
# -*- coding : utf-8 -*-
# @Time : 2020/8/19 21:56
# @author : 沙漏在下雨
# @Software : PyCharm
# @CSDN : https://me.csdn.net/qq_45906219
import time
import threading
from urllib.parse import urlencode
from fake_useragent import UserAgent
import requests
import re
import os
class AjaxSpider(object):
"""
重写一次头条爬虫, 这次全面完善,加上很多之前没用到的东西
从图集 到文件 到转换为pdf 这一次我全都有。
学会这一个代码 基本爬虫 可以横着走了
"""
def __init__(self):
"""
配置基础设置
"""
self.url = "https://www.toutiao.com/api/search/content/?"
# 构造url
# 头信息 加入参数
self.user = UserAgent() # 多请求头
self.headers = {
'cookie': 'csrftoken=4a2a6afcc9de4484af87a2ff8cba0638; ttcid=8732e6def0484fae975c136222a44f4932; tt_webid=6862678326524839431; s_v_web_id=verify_ke1drmzk_z2TCIiBg_nLDJ_45eL_AblY_n6195E59w68S; WEATHER_CITY=%E5%8C%97%E4%BA%AC; tt_webid=6862678326524839431; MONITOR_WEB_ID=b4a776dd-f454-43c6-81cd-bd37cb5fd0ec; __ac_signature=_02B4Z6wo00f01z-C1bAAAIBDQ4ILSJIdaYs.htEAAJDmAPYD1OTlD5KPRJ2LQh6uQ7Bo0bH5LFexApSHZucelY-7XrUsPNv5Rz4yMqyC5rHPH2wDXi7W7NLR5oTdt5MTb3p4g1WnOe3k1Stk3e; tt_scid=QA92vdakyjRvdp7mZyOW89R1Lj.7M2dX9noGBshXT8s0cqXYHXiuC32Rx7l2ZmdVa66a; __tasessionId=mr7tknawq1597911808662',
'user-agent': self.user.random,
'referer': 'https://www.toutiao.com/search/?keyword=%E7%BE%8E%E5%A5%B3',
'x-requested-with': 'XMLHttpRequest'
}
def __params(self, offset):
"""构造字典"""
self.offset = offset
self.params = {
"aid": "24",
"app_name": "web_search",
"offset": str(self.offset), # 加 20
"format": "json",
"keyword": "街拍",
"autoload": "true",
"count": "20",
"en_qc": "1",
"cur_tab": "1",
"from": "search_tab",
"pd": "synthesis",
"timestamp": int(time.time()) # 时间参数
}
def spider(self, count):
"""
开始爬取 params: count offset = offset + count * 20
"""
# 修改参数 offset
self.__params(count)
url = self.url + urlencode(self.params)
# 这次的url 非常正常 没有改变 有点顺利
r = requests.get(url, headers=self.headers)
if r.status_code == 200:
for content in self.parse_json(r.json()):
title, image_list = self.parse(content) # 解析得到标题和网址列表
if title == 'change':
continue
else:
self.down_image(title, image_list) # 下载图片 出口
else:
print(r.status_code)
def parse(self, content):
"""
解析每一个图集链接
"""
# 请求解析网址
r = requests.get(content.get('page_url'), headers=self.headers)
if r.status_code == 200:
pat = '<script>var BASE_DATA = .*?articleInfo:.*?content:(.*?)groupId.*</script>'
match = re.search(pat, r.text, re.S)
if match: # 如果上面获取成功 则这样写正则 经过测试 现在有新的源码 需要修改正则表达式
# 正确网址 https://p1-tt.byteimg.com/origin/pgc-image/c079d3c1f26b4001abcd5da5d5ed403b?from=pc
# 得到网址 https:\u002F\u002Fp1-tt.byteimg.com\u002Forigin\u002Fpgc-image\u002F54b8942a273d4e2e92c19c3044bafdc7?from=pc
# 对比区别 编码问题 存在小误差 先正则提取出来 进行接下来的操作
result = re.findall(r'img src=\\"(.*?)\\"', match.group(1), re.S)
# 得到图片列表地址
result_list = [i.encode('utf-8').decode('unicode_escape') for i in result] # 修改编码
return content.get('title'), result_list
else:
return 'change', 'it'
else:
print(r.status_code)
def down_image(self, title, img_list):
"""
下载图片 params: title img_list
"""
# 创建总目录
path = 'D://今日头条美女//' # 目录
if not os.path.exists(path): # 创建目录
os.mkdir(path)
os.chdir(path)
else:
os.chdir(path)
# ------------------------------ ------------
# 对标题的进一步缩小处理
if '街拍' in title:
title = title.split(':')[-1]
title = title.strip().replace("\t", "")
# 创建分批目录 对目录标题进行细节处理
now_path = os.path.join(path, title)
if not os.path.exists(title):
os.mkdir(now_path + "//")
os.chdir(now_path + '//')
else:
os.chdir(now_path + '//')
# 开始下载图片
for index, value in enumerate(img_list):
r = requests.get(value, headers=self.headers)
if r.status_code == 200:
name = str(index + 1) + ".png"
with open(name, "wb") as fw:
fw.write(r.content)
print(f'{name} 下载完成, 保存在{os.path.join(path, title)}')
else:
print('下载失败', r.status_code)
print(f'系列 {title} 全套成功下载完成!')
print('- ' * 30)
def parse_json(self, json_package):
"""
解析每一个json包
"""
all_data = json_package.get("data")
if all_data: # 判空
for content in all_data:
title = content.get('title')
page_url = content.get('article_url')
# 这二种网址都可以打开同一个页面
# http://toutiao.com/group/6862530715892843021/ 这个是从json包提取出来的
# # https://www.toutiao.com/a6862530715892843021/ 这个是正常点进入的网址
items = {
"title": title, # 标题
"page_url": page_url, # 图集网址
}
if title and page_url: # 都存在
yield items
else:
print("requests timeout please wait !")
def start_thread(self):
"""
开启多线程
"""
page_num = [i * 20 for i in range(15)]
for i in range(5): # 线程多开 次数越大
t = threading.Thread(target=self.spider, args=(page_num.pop(0),))
print(f"开启线程{i}中......., 正在加速中")
t.start()
t.join()
time.sleep(0.7)
a = AjaxSpider()
a.start_thread()
本次爬虫涉及到模块 : request库, 正则re, os模块, time模块, 多线程, 多请求头等, 帮助你解决ajax类型的网址爬虫。