一:内存管理概述:
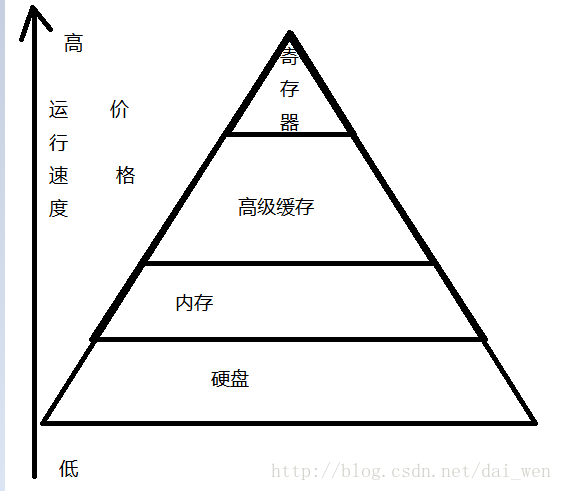
如图一所示,在计算机中,主要分为以上存储区域中,分别是:硬盘、内存、高级缓存 和寄存器。执行程序后,他们的运行速率自下而上(图一)加快,与之相应的造价越高,其中,硬盘的运行效率最慢,寄存器的效率最快。在这几个区域里,今天重点介绍一下内存。在C++ 中,内存主要分为五个区,分别是:代码区、栈区、堆区、静态(全局)数据区。
(一)、代码区:
代码区是用来储存程序的所有代码,以及字符串常量等在编译期间就能确定的值,在程序的整个生命周期内, 在常量数据区的数据都是可用的。在这个区域内,所有的数据都是只读的,不可以修改本区域的数据,之所以这样,是因为在实际的实现中,最底层内部存储格式的实现会使用特定的优化方案。比如说,编译器可能只把字符串常量存储一次,而在几个重叠的对象里面引用它 。
(二)、栈区:
1、定义:
栈区主要存放编译器在需要的时候自动分配,在不需要的时候自动销毁的变量。主要是局部变量和函数的参数等,在函数调用和传参的时候,编译器为局部变量或形参开辟空间,注意,在这块空间中,编译器并不会自动对它进行任何的初始化,它所保存的不是0,而是一个随机值(可能是该储存区上次被使用后的值),在函数结束后,所开辟的空间将自动销毁,里面所存的内容将不复存在,也就是释放存储区的内容。 这就是为什么老师们在讲课中,最喜欢用的字眼:参数压栈和弹出。
2、易错点:
在这里,不得不说明,当一个自动变量的地址被存储在一个生命期长于它的指针时,自动变量被释放后,该指针就成了一个“悬空指针”,这一点是非常可怕的,因为“悬空指针的内容无法预测的”
(三):全局静态(数据)区:
全局(静态)数据区:顾名思义,它是用来存储全局静态变量的存储区域。只有在程序启动的时候才被分配,直到程序开始执行时才被初始化,比如:函数的静态变量就是在程序执行到定义该变量的代码时才被初始化的。在静态区数据区中没有被初始化的区域可以通过void* 指针来访问或操纵,但是,static定义的静态变量只能在本文件中使用,不可在其它文件中声明使用。
(四)、堆区:
1、定义:
堆区是一个动态的存储区域,使用库函数malloc()和free(),和操作符new和delete以及一些相关变量来进行分配和回收,在堆区中,对象的生命周期可以比它村在内存中的生命周期短,换句话说:程序可以获得一片内存区域而不用马上对它进行初始化,同时,在对象被销毁后,也不用马上收回它所占用的内存区,在这段时间内,用户可以还可以用void*型的指针访问这片区域,但是原始对象的非静态区以及成员函数都不能被访问或者操纵,因为我们知道实际上对象已经不存在了。
下面我们就来具体看看动态内存分配到底是怎么分配的。
一、好奇心不仅害死猫:
(一)、数组元素的存储方式:int array[8];
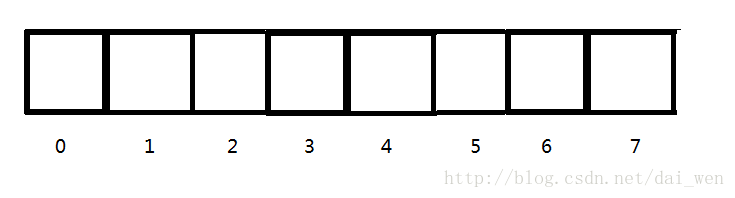
如图所示,数组元素在内存中是连续存放的,当一个数组被声明时, 它所需要的内存在编译时就被分配。但是,在创建数组时,须用一个常量来指定该数组的长度,而数组本身长度常常在运行时才知道,它所占内存空间的大小便取决于输入数据,在这种情况下,我们通常采取的解决办法便是声明一个比较大的数组,以确保它能够容纳足够多的数据。
(二)、优缺点:
1、优点:定义数组时简单、数组大小一目了然。
2、缺点:有以下三点
(1)、此类声明在程序中引入了人为的限制,如果程序需要使用的元素数量超过了先前声明的长度,则无法处理。
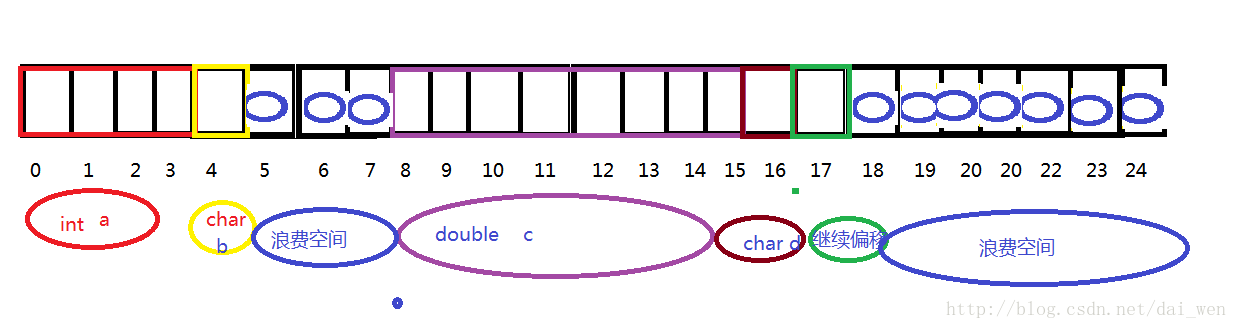
(2)、解决(1)中的问题,毫无疑问会想到把数组的声明更大一些,但是,如果程序的元素数量比较少时,会造成大量的空间被浪费掉(如图三)
(3)、若元素个数远远大于数组容纳范围时,程序因做出合理的响应,不应该由此失败
那么,这时候,人们好奇,有没有一种可能,使得我要多大的的内存就有多大? 我想存什么类型的数据就开辟相应字节大小的空间呢?正是因为这些好奇心的出现,才有了我们现在的动态内存分配。
二、malloc和free共同维护内存池
在C语言中,提供了两个特殊的函数,malloc和free 。
(一) malloc:
(1)、用途:
malloc用于动态内存分配,当程序在执行过程中需要一定的内存空间时, 就调用malloc函数,由它从内存池中取出相应大小的空间,并返回指向该空间的指针。(注意:该空间此时没有以任何方式进行初始化)
(2)、声明头文件:stdlib.h
(3)、函数形式
void * malloc( size_t size );//void* 任意类型
(4)、使用说明:
malloc 所分配的是一块连续的内存,它的参数部分是需要分配的字节数,(A)如果内存中的可用内存可以满足这个需求,就返回一个指向被分配的内存块起始位置的指针。例如:如果请求分配100个字节大小的内存,那么它分配的内存就是100个连续的字节,并不会分开位于多块不同的区域,同时,实际分配的内存可能会比请求的稍微多一点,该行为是由编译器决定的, 故而,程序员不能指望它分配过多多余的空间。(B)、倘若内存池是空的,或者它的可用内存无法满足请求时,malloc会向操作系统,申请得到更多的内存,并在这块新的内存上执行分配任务,若操作系统无法向malloc提供更多的内存,那么,它就返回一个NULL指针。(C)对每个从malloc返回的指针都进行检查,确保它非NULL指针是非常重要的。
(二):free()
free( )用于释放动态开辟的内存,它的参数要么是malloc( )返回的值,要么是NULL, 向free( )传递一个NULL参数不会产生任何效果。
从堆上分配的空间称为动态内存分配,程序在运行的时候,使用malloc()或操作符new 申请任意多的内存,由程序员自己负责使用free()和delete释放内存,这样,动态内存的生命周期由用户决定,使用非常灵活。
(三)在堆、栈、和静态分配空间的生命周期如下:
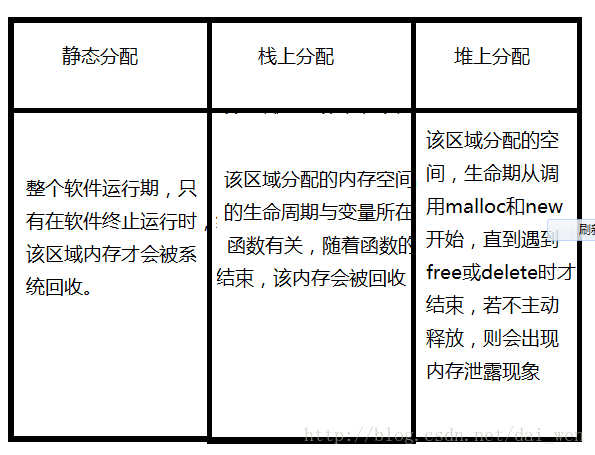
细心的人可能会发现,我上面说,用于动态内存开辟的,除了malloc和free外,还说了一对“操作符”new和delete;那么,都是用于动态内存的开辟,两者之间有什么不同之处呢? 下面我们就共同来探讨吧。
三、new和delete的详细解析:
操作符new和delete究竟做了什么?让我们一起看一下下面这段代码吧
class A
{
public:
A()
{
cout<<"A is here !"<<endl;
}
~A()
{
cout<<"A is dead !"<<endl;
}
private:
int i;
};
A* pA =new A;
delete pA;
在上述程序中,new主要做了两件事,首先调用new操作符,在堆上分配一个A 类型对象大小的内存空间,相当于有了一块地基,然后调用A类型的构造函数A(),在这块已有的空间上添砖砌瓦,建造一个属于A的建筑(对象)。
对于delete 操作符,它做了与之恰恰相反的两件事,首先调用析构函数,销毁对象,在调用delete操作符,释放内存。
接下来,我要用两张图来具体展示使用new和delete 的调用过程。里面用到的operator如果你不是很理解的话,可以参考我的上一篇文章,
http://blog.csdn.net/dai_wen/article/details/78386526
A:new

B:delete
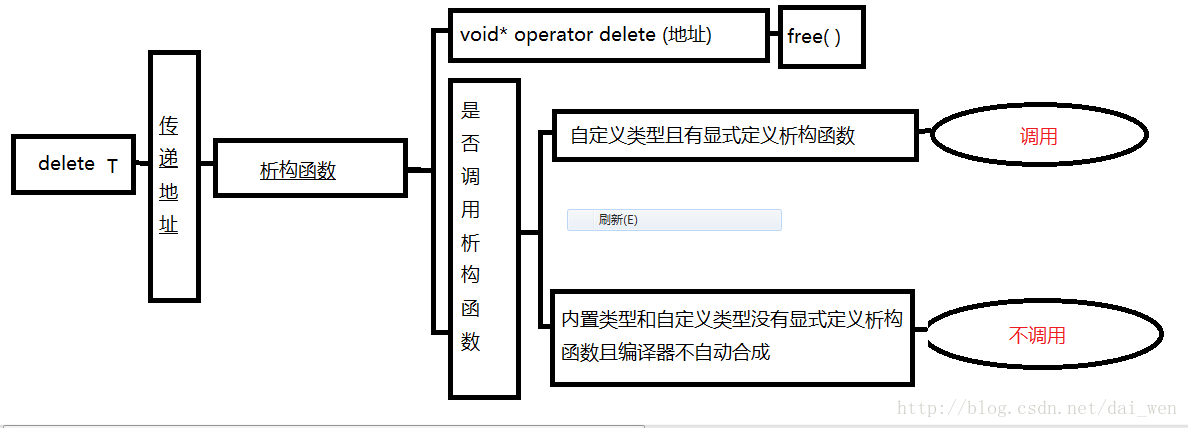
用new和delete开辟的是一片内存,那么,如果想像数组一样,一次性开辟多个内存,该怎么办呢?
现在就要用到new T[N ]和delete T[N];
a、new T[N ]开辟连续空间
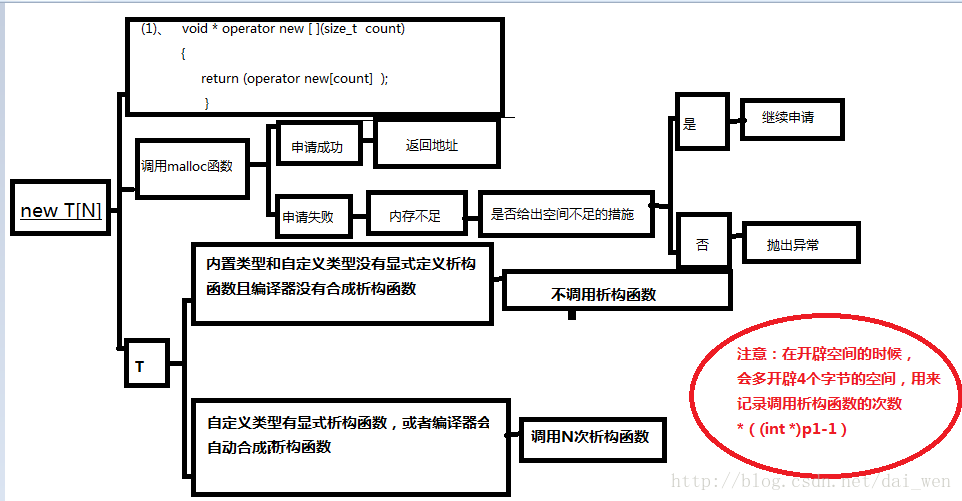
b、delete T[N]销毁连续空间
delete [ ]销毁空间和delete相似,唯一不同的是,需要从空间的首地址向前推四个字节开始释放。