IDA Pro 权威指南——读书笔记(第一章:反汇编简介)
本系列目录:https://blog.csdn.net/weixin_42559271/article/details/106946434
本章简介
反汇编简介作为本书的第一章,介绍了IDA诞生的主要目的和其中遇到的一些困难、IDA如何解决这些困难 ,以及两种反汇编算法。
以下是本章目录:
- 反汇编理论
- 何为反汇编
- 为何反汇编
- 如何反汇编
1.反汇编理论
该节简要介绍了一下四代计算机语言,这些语言和历史、特点应该在每一本C语言书上都介绍过。下面简要说明一下:
| 名称 | 特点 |
|---|---|
| 机械语言,又称为字节码 | 由完全的二进制0和1构成,直接由CPU读取到 |
| 汇编语言 | 和机械语言是一对一的关系,一条汇编指令对应一段字节码,同时在汇编语言里面出现了一些地址标识符,方便了程序员编写代码 |
| 函数式语言 | 这一代语言进一步提高了对用户的抽象程度,对用户屏蔽了内存管理,循环等操作的实现细节,同时出现了关键字和函数块,使得编程语言进一步接近于自然语言,同时一条语句可能会对应多个汇编指令。比较著名的有C、Java等 |
| 面向对象语言 | 这一代语言出现的目的是为了解决大规模编程的问题,由函数式编程的类似于解数学题的编程思维转化为了先构建好类,由类组合实现功能的编程思维。 |
2.何为反汇编
我认为,反汇编就一句话:把机械语言转化为人类能够读懂的汇编语言,在此基础之上还可以将汇编语言转化为更加好懂的高级语言,即普遍意义上的源代码。在恢复源代码的过程中,如果不考虑花指令、加壳等手段,我认为主要的困难在于补全高级语言转化为汇编语言时丢失的信息。对此,书上描述了其困难所在:
- 编译过程中会造成信息的损失,对于汇编语言来说,一个一字节的信息,可能在高级语言中是char(字符串)或者unsigned char(此时通常作为字节数组使用),同样的,一个四字节的信息,可能是一个int的数据,也可能是一个Unicode编码的字符,如果是整形类型的数据,将其解释为有符号数和无符号数的结果又是完全不同的。
- 编译属于多对多操作,对于一个高级语言中的函数,在调用者调用这个函数的时候,对于不同的调用约定,会有不同的汇编代码,同样的是,只要保持程序的结构不变,不同的变量名编译出来的代码是一样的。
- 反编译器非常依赖于语言和库,反编译器或者反汇编器如果不知道任何Windows的API和系统原理,反编译出来的东西只能是一头雾水,OD里面的对于导入表函数的处理就体现了这个原则。
3.为何反汇编
反汇编的目的如下:
- 分析恶意软件
- 挖掘0day漏洞,分析已知漏洞
- 在开发者没有开发文档,甚至拒绝他人自定义开发好的软件时,想要自定义软件
- 分析编译器的代码,以便于分析其性能和准确性
- 调试时分析汇编指令
如何反汇编
反汇编器的任务
反汇编器在反汇编过程中,最艰难的一个任务是:如何区分一个文件中的代码和数据。由于冯·诺依曼结构的计算机没有数据存储器和指令存储器的区分,在一个可执行文件中的代码和数据总是混杂在一起的,而从本质上来说,这两者其实并没有什么区别。除此之外,反汇编器还被要求做其他的一些事情,如:定位函数,识别跳转表,确定局部变量等等工作。
反汇编算法的基本步骤
反汇编算法包括以下几个步骤:
- 确认一个文件中哪些是代码,哪些是数据,这些信息通常包含在输入文件的一个块里,通常是文件开头,比如Windows平台使用的PE结构中的PE头,再比如ELF文件中也有类似的文件头。
- 第二步确认从哪里开始汇编。
- 将当前地址的机械指令翻译会汇编指令,先读取指令中的操作码,将其转化为汇编语言,再读取操作数。
- 确定下一条指令的地址在哪里
两种基本的反汇编算法
那么,如何确认下一条指令的地址呢?对应的有两种算法:线性扫描算法和递归下降算法。
线性扫描算法
线性扫描算法和它的名称一样,当一条汇编指令转化完时,下一条汇编地址=当前地址+机械码长度。这种算法最大的问题就在于编写者做一点小小的技巧就能将反汇编出来的汇编语言修改的面目全非(这种技巧又称为花指令),这种问题的本质在于线性扫描算法无法很好的区分插入到代码块里面的数据。
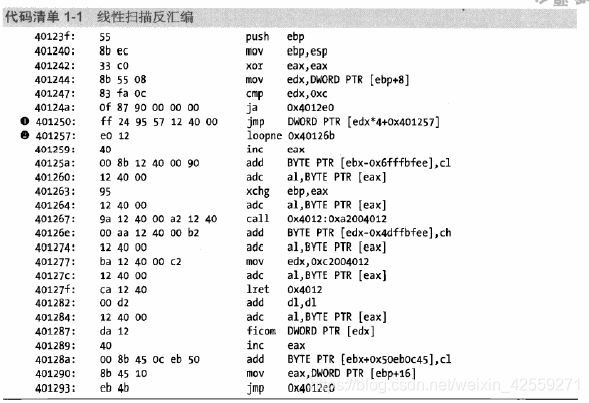
如上面这段代码,可以看到在地址0x40124a后的汇编代码显得十分不正常,其实这是因为高级语言使用了一个switch结构,而编译器选择在这里插入了一个叫做跳转表的数据结构,但是线性扫描算法将这段数据识别为了指令。关于跳转表这种数据结构,可以参照这篇文章。
使用该种算法的反汇编引擎包括GBD、WinDbg和objdump等工具。
递归下降反汇编
和线性扫描不同的是,递归下降反汇编强调控制流的概念,在这种算法中,下一条指令的地址是由当前指令的种类所决定的,大致将指令类型分为以下几种:
- 顺序流指令:对于这种指令,如mov、push等没有跳转的指令,采用线性反汇编
- 条件分支指令:对于这种指令,在不同的条件下程序会有两种走向,对于这种情况,算法将紧跟在后面的字节采用线性扫描反汇编,而将跳转的目标地址添加到反汇编的地址列表里面,以便稍后进行分析。
- 无条件分支指令:对于这种指令,算法会将目标地址设置为下一条指令的地址,而对于紧跟在无条件分支之后的字节,算法选择忽略。
- 函数调用指令:函数调用指令的处理流程和条件分支指令相似:紧跟在后面的字节采用线性扫描反汇编,将调用目标添加到反汇编的地址列表里面。
- 返回指令:当一个函数返回时,会从栈上获取返回地址,但实际上在静态分析时算法不可能获得返回地址,这时这一条反汇编路径结束,算法从反汇编地址的列表里取出新的一条,继续进行分析。
实际上,递归下降反汇编有时候也会不管用,比如如果高级程序的程序员使用了函数指针数组,并结合循环使用,在汇编代码里面很有可能会出现类似于call eax,jmp eax 等等指令,而这些指令的跳转地址只有在运行时才能够确认。
同时,如果程序的编写者采用了一定的反汇编手段,该种算法同样会被影响,下面就是一个实例:

这是这段代码的正确的反汇编结果,但实际上如果不做任何处理,反汇编出来的东西应该是这个样子的:

为什么会出现这样的结果,在foo函数里面,该函数将函数返回地址+1,从而跳过了05这个字节,但是反汇编引擎根据上面介绍的反汇编规则,实际上是只能将05这个字节作为指令的一部分进行处理。实际上,这种反汇编手法叫做花指令,除了这种手法外,还有其他的手法,如:
mov eax,0x123456 #一个随机数
cmp eax,0x123456
je real_instructions
db 01
db 02
#一些随机数据
real_instructions:
....
对于以上的花指令,递归下降算法同样不能很好的识别。递归下降算法的主要优点在于它可以很好的识别数据和指令(在编写者不捣乱时),但是缺点在于无法处理间接代码路径,如利用函数指针数组来处理函数跳转的情况,但是IDA利用了一种叫做“启发”的技术来处理,至于启发的技术是什么,笔者也不太了解。