文章目录
- 一、kafka简介
- 1.1、kafka有四个比较核心的API 分别为:
- 1.2、基础架构及术语(kafka最重要的图)
- 1.3、关键字图解
- 1.4、工作流程分析
- 1.5 搭建kafka集群,这个自己去网上找资料,感觉搭建kafka集群还是很简单。
- 二、原生客户端操作Kafka(必须掌握)
- 2.1 查看多少个 topic
- 2.2 查看 topic 的详细信息
- 2.3 创建topic
- 2.4 往主题为 can-test 发送消息
- 2.5 接收主题为 can-test 的消息,当前kafka发送才接收得到,之前发送的接收不到
- 2.6 接收主题为 can-test 所有的消息,从头到尾的所有消息
- 2. 7 查看kafka版本
- 2.8 查询分组,要想查询消费者,必须查询指定的分组
- 2.9 从指定分组查看消费的状态
- 三、springboot创建kafka代码
- 四、结语
一、kafka简介
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源 项目。
kafka、ActiveMQ、RabbitMQ是当今最流行的分布式消息中间件,其中kafka在性能及吞吐量方面是三者中的佼佼者,不过最近查阅官网时,官方与它的定义为一个分布式流媒体平台。kafka最主要有以下几个方面作用:
- 发布和订阅记录流,类似于消息队列或企业消息传递系统。
- 以容错持久的方式存储记录流。
- 处理记录发生的流
1.1、kafka有四个比较核心的API 分别为:
-
producer:允许应用程序发布一个消息至一个或多个kafka的topic中
-
consumer:允许应用程序订阅一个或多个主题,并处理所产生的对他们记录的数据流
-
stream-api: 允许应用程序从一个或多个主题上消费数据然后将消费的数据输出到一个或多个其他的主题当中,有效地变换所述输入流,以输出流。类似于数据中转站的作用
-
connector-api:允许构建或运行可重复使用的生产者或消费者,将topic链接到现有的应用程序或数据系统。官网给我们的示意图:
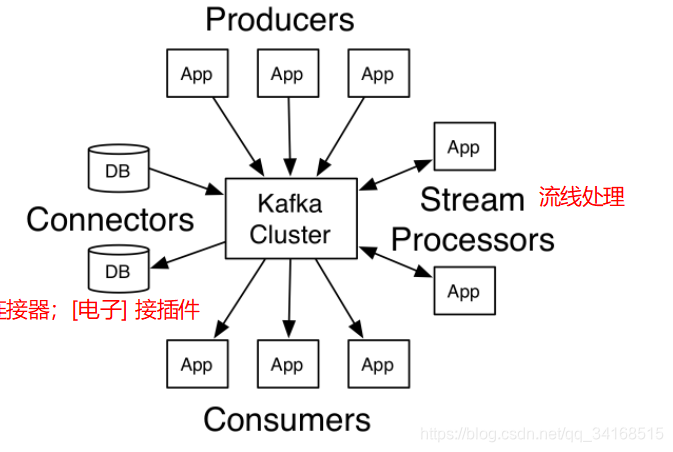
1.2、基础架构及术语(kafka最重要的图)
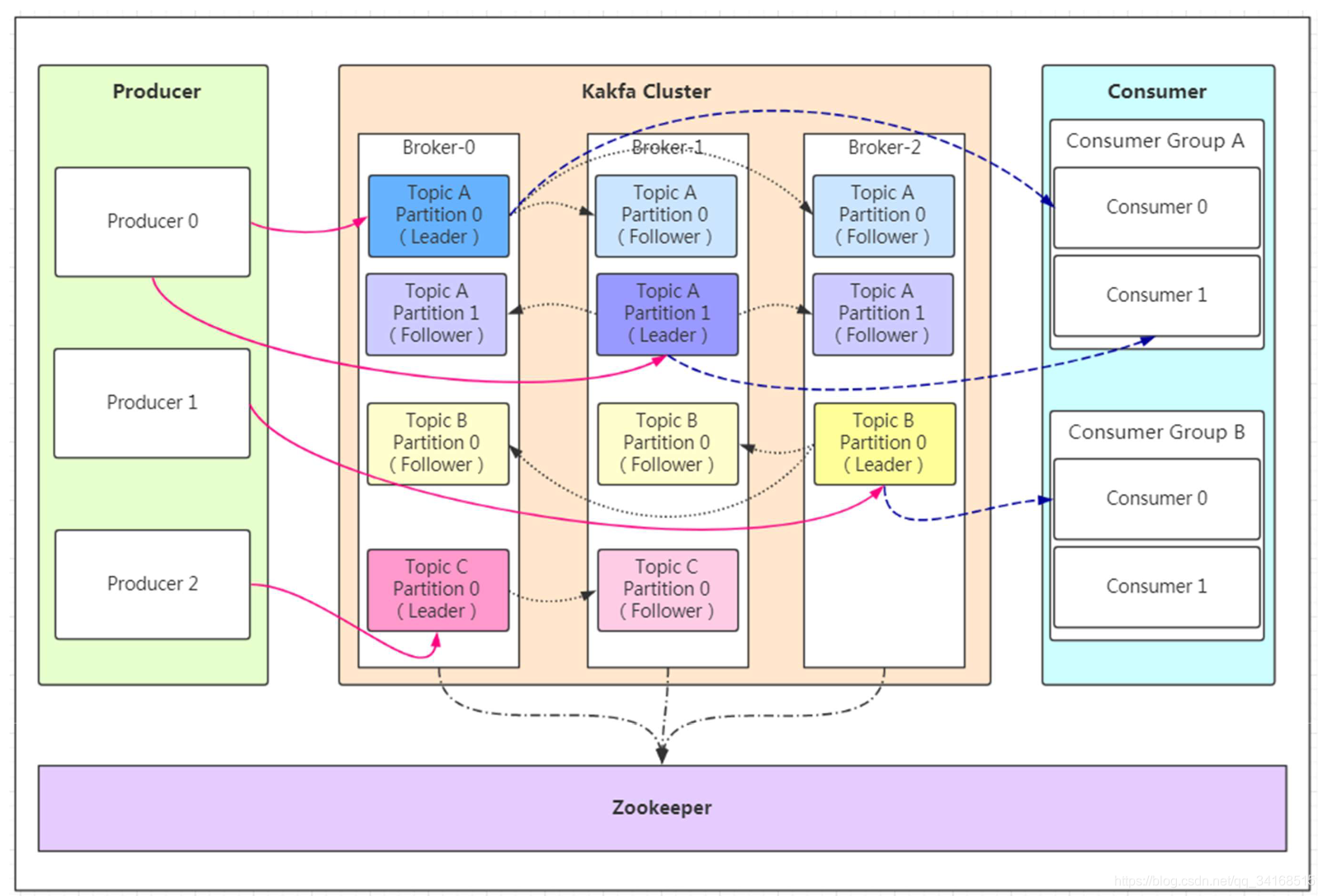
如果看到这张图你很懵逼,木有关系!我们先来分析相关概念Producer:
- Producer即生产者,消息的产生者,是消息的入口。
kafka cluster: - Broker:Broker是kafka实例,每个服务器上有一个或多个kafka的实例,我们姑且认为每个broker对应一台服务器。每个kafka集群内的broker都有一个不重复的编号,如图中的broker-0、broker-1等…
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作用是做负载,提高kafka的吞吐量。同一个topic在不同的分区的数据是不重复的,partition的表现形式就是一个一个的文件夹!
- Replication:每一个分区都有多个副本,副本的作用是做备胎。当主分区(Leader)故障的时候会选择一个备胎(Follower)上位,成为Leader。在kafka中默认副本的最大数量是10个,且副本的数量不能大于Broker的数量,follower和leader绝对是在不同的机器,同一机器对同一个分区也只可能存放一个副本(包括自己)。
- Message:每一条发送的消息主体。
- Consumer:消费者,即消息的消费方,是消息的出口。
- Consumer Group:我们可以将多个消费组组成一个消费者组,在kafka的设计中同一个分区的数据只能被消费者组中的某一个消费者消费。同一个消费者组的消费者可以消费同一个topic的不同分区的数据,这也是为了提高kafka的吞吐量!
- Zookeeper:kafka集群依赖zookeeper来保存集群的的元信息,来保证系统的可用性
1.3、关键字图解


1.4、工作流程分析

1.5 搭建kafka集群,这个自己去网上找资料,感觉搭建kafka集群还是很简单。
搭建的时候,注意几个参数:
#搭建三个集群的时候,需要打开三个分片
num.partitions=3
#在创建主题的时候,默认开启三个副本
default.replication.factor=3
二、原生客户端操作Kafka(必须掌握)
2.1 查看多少个 topic
kafka-topics --zookeeper 10.244.1.132:2181 --list
__confluent.support.metrics
__consumer_offsets
xixi
2.2 查看 topic 的详细信息
kafka-topics --describe --zookeeper 10.244.1.132:2181
Topic:__confluent.support.metrics PartitionCount:1 ReplicationFactor:1 Configs:retention.ms=31536000000
Topic: __confluent.support.metrics Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:xixi PartitionCount:3 ReplicationFactor:3 Configs:
Topic: xixi Partition: 0 Leader: 1 Replicas: 1,2,0 Isr: 2,0,1
Topic: xixi Partition: 1 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1
Topic: xixi Partition: 2 Leader: 0 Replicas: 0,1,2 Isr: 2,0,1
2.3 创建topic
kafka-topics --zookeeper 10.244.1.132:2181 --topic can-test --create --partitions 1 --replication-factor 3
Created topic "can-test".
2.4 往主题为 can-test 发送消息
kafka-console-producer --broker-list 10.244.2.251:9092 --topic can-test
>1
>2
>3
>4
2.5 接收主题为 can-test 的消息,当前kafka发送才接收得到,之前发送的接收不到
kafka-console-consumer --bootstrap-server 10.244.2.251:9092 --topic can-test
3
4
2.6 接收主题为 can-test 所有的消息,从头到尾的所有消息
kafka-console-consumer --bootstrap-server 10.244.2.251:9092 --topic can-test --partition 0 --offset 0
1
2
3
4
接收主题为 can-test offset为3的数据,那么就是从第四位开始算起
kafka-console-consumer --bootstrap-server 10.244.2.251:9092 --topic can-test --partition 0 --offset 3
4
2. 7 查看kafka版本
find / -name \*kafka_\*
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1-javadoc.jar
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1-scaladoc.jar
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1-sources.jar
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1-test-sources.jar
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1-test.jar
/usr/share/java/kafka/kafka_2.11-1.1.1-cp1.jar
2.8 查询分组,要想查询消费者,必须查询指定的分组
kafka-consumer-groups -bootstrap-server 10.244.2.251:9092 --list
Note: This will not show information about old Zookeeper-based consumers.
groudA
a
console-consumer-85675
KMOffsetCache-kafka-manager-5c55749d59-rkvtq
b
console-consumer-36166
2.9 从指定分组查看消费的状态
kafka-consumer-groups --describe --bootstrap-server 10.244.2.251:9092 --group groudA
Note: This will not show information about old Zookeeper-based consumers.
TOPIC PARTITION CURRENT-OFFSET LOG-END-OFFSET LAG CONSUMER-ID HOST CLIENT-ID
xixi 0 19 19 0 consumer-2-5381f560-1740-42d2-9e40-f1aa1f4f7a9e /10.244.1.0 consumer-2
xixi 1 27 27 0 consumer-2-5381f560-1740-42d2-9e40-f1aa1f4f7a9e /10.244.1.0 consumer-2
xixi 2 22 22 0 consumer-4-e9fa6c16-d100-4246-ad00-dd02e9cc0d97 /10.244.1.0 consumer-4
三、springboot创建kafka代码
3.1 依赖
<dependencies>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
3.2 配置 springboot的 application.yml
spring:
kafka:
bootstrap-servers: 10.244.2.251:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
retries:
consumer:
group-id: groudA
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
3.3 配置生产者
/**
* 测试kafka生产者
*/
@RestController
@RequestMapping("/kafka")
public class TestKafkaProducerController {
@Autowired
private KafkaTemplate kafkaTemplate;
@RequestMapping("/send")
public String send(String msg){
kafkaTemplate.send("xixi", msg);
/* for (int i=0;i<200;i++){
kafkaTemplate.send("xixi", i+"");
}*/
return "success";
}
}
3.4 配置消费者
注意
1、partition在写入的时候可以指定需要写入的partition,如果有指定,则写入对应的partition。
2、如果没有指定partition,但是设置了数据的key,则会根据key的值hash出一个partition。
3、如果既没指定partition,又没有设置key,则会轮询选出一个partition。
/**
* kafka消费者测试
*/
@Component
public class TestConsumer {
//@KafkaListener(groupId = "b",topicPartitions = @TopicPartition(topic = "xixi",partitions = "0"))
@KafkaListener(topics = "xixi")
public void listen (ConsumerRecord<?, ?> record) throws Exception {
//四个参数依次为topic名字,偏移数也就是信息数,传输的数据,分区的号
System.out.printf("这一号消费者topic = %s, offset = %d, value = %s ,index=%s \n", record.topic(), record.offset(), record.value(),record.partition());
}
//@KafkaListener(groupId = "b",topicPartitions = @TopicPartition(topic = "xixi",partitions = "1"))
@KafkaListener(topics = "xixi")
//注意:同一个topic,同一个groudid,并且只有在开启分区 num.partitions=3 才会有类似轮询的效果
public void listen1 (ConsumerRecord<?, ?> record) throws Exception {
//四个参数依次为topic名字,偏移数也就是信息数,传输的数据,分区的号
System.out.printf("这是二号消费者topic = %s, offset = %d, value = %s ,index=%s \n", record.topic(), record.offset(), record.value(),record.partition());
}
}
发送请求:
localhost:8080/kafka/send?msg=…
结果 — 一号消费者消费了 0和1分区,二号消费者消费了 2分区
这一号消费者topic = xixi, offset = 17, value = 1 ,index=1
这一号消费者topic = xixi, offset = 17, value = 2 ,index=0
这是二号消费者topic = xixi, offset = 20, value = 3 ,index=2
这一号消费者topic = xixi, offset = 18, value = 4 ,index=1
这一号消费者topic = xixi, offset = 18, value = 5 ,index=0
这是二号消费者topic = xixi, offset = 21, value = 6 ,index=2
这一号消费者topic = xixi, offset = 19, value = 7 ,index=1
四、结语
本人从事多年的java开发经验,有疑问,请留言。