注:本文数据库主要以Mysql InnoDB存储引擎为基础进行讨论。
我们都知道在选择主键的类型的时候,尽量避免随机的(不连续且值得分布范围非常大)值作为数据库主键,特别是对于I/O密集型得应用。那么为什么?
下面我们将从存储和设计上进行简单分析。
前置知识
聚簇索引:将数据存储与索引放到了一块,索引结构的叶子节点保存了行数据
非聚簇索引:将数据与索引分开存储,索引结构的叶子节点指向了数据对应的位置
Mysql Btree 索引结构
如果是聚簇索引,那么索引的叶节点保存了索引值以及数据data。
Page 页:是Innodb存储的最基本结构,也是Innodb磁盘管理的最小单位,与数据库相关的所有内容都存储在Page结构里。简单理解就是将数据分块成页,每个页里面包含部分数据。
接下里进入主题
许多数据库相关的博客或书上会提到主键的选择上,尽量有序,UUID等无序的串会导致性能降低,为什么呢?
这其实和数据底层存储结构以及设计有关。
顺序值作为主键
我们先来看下 如果使用的是顺序的存储模式,聚簇索引在插入的时,存储应该是如何分布的。
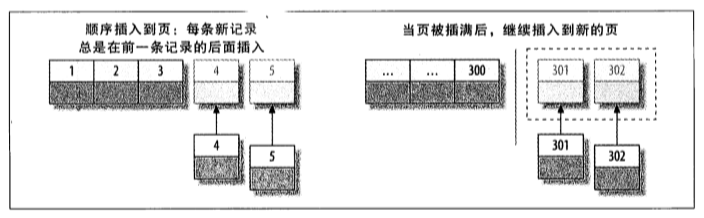
因为主键得值是有序得,所以InnoDB把每一条记录都存储在上一条记录得后面,当达到页面的最大填充因子时(InnoDB默认的最大填充因子是页面大小的15/16,留出部分空间用于以后修改),下一条记录就会写入新的页中。一旦数据按照这种顺序的方式加载,主键页就会近似于被顺序的记录填满,这也正是所期望的结果。
了解了基本的存储,那么UUID又是如何影响性能的?
从性能得角度考虑,使用UUID来作为局促索引则会很糟糕:它使得聚簇索引(主键值和行数据存放在一起)的插入变得完全随机,这是最坏得情况,使得数据没有任何得聚集性。
同时,使用UUID主键插入行不仅花费得时间更长,而且所有占用得空间也更大。主要是由于主键字段更长,另一方面毫无疑问是由于页分裂和碎片导致得。
因为UUID是随机生成的串,虽然能保证唯一性,但是因为新行的主键值不一定比之前插入的大,索引InnoDB无法简单地总是把新行插入到索引的最好,而是需要为新的行寻找合适的位置,通常是已有数据的中间位置,并且分配空间,这也会增加很多的额外工作,并导致数据分布不够优化。会导致以下情况:
- 写的的目标页可能已经刷入到磁盘上并从缓存中移除,或者是还没有被加载到缓存中,InnoDB在插入之前不得不先找到并从磁盘读取目标页到内存中。这将导致大量的随机I/O。
- 因为写是乱序的,InnoDB不得不频繁的做页分裂操作,以便新的行分配空间。页分裂会导致移动大量数据,一次插入最少需要修改三个页不是一个页。
- 由于频繁的也分裂。页会变得稀疏并被不规则地填充,最终导致数据会有碎片。

也正是因为上面一些影响性能的因素,索引尽量避免在生成中使用UUID作为数据库主键,但是如果项目确实有需要使用的必要,就根据实际情况而定。