PB级规模数据的Elasticsearch统一日志存储冷热分离原理和实践
一、目标
最近在做公司的全量日志收集和检索,需要统一公司各个业务线常用的应用业务日志,统一存储,统一查看,统一前端UI组件,保障查询,写入性能,降低重复开发成本。这里提供一些项目中的心得和性能优化的解决方案。
一、参考文章
二、名词释义
- 索引:link.
- 节点:link.
- 集群:link.
- 分片:link.
- 文档:link.
- mapping映射与分析:link.
- 冷热数据节点分离:link.
- 路由:link.
- 索引别名:link.
- Curator:link.
三、性能目标
- 业务应用日志延迟1s内;查询速度 90% 500ms内 100%1500ms内
四、技术方案概要
- 业务应用日志不强调数据检索,更多的是使用业务KeyId进行数据查询,所在在ElasticSearch的索引结构设计上,尽量避免设置全文搜索字段,更多使用精确值域,以减轻内存压力
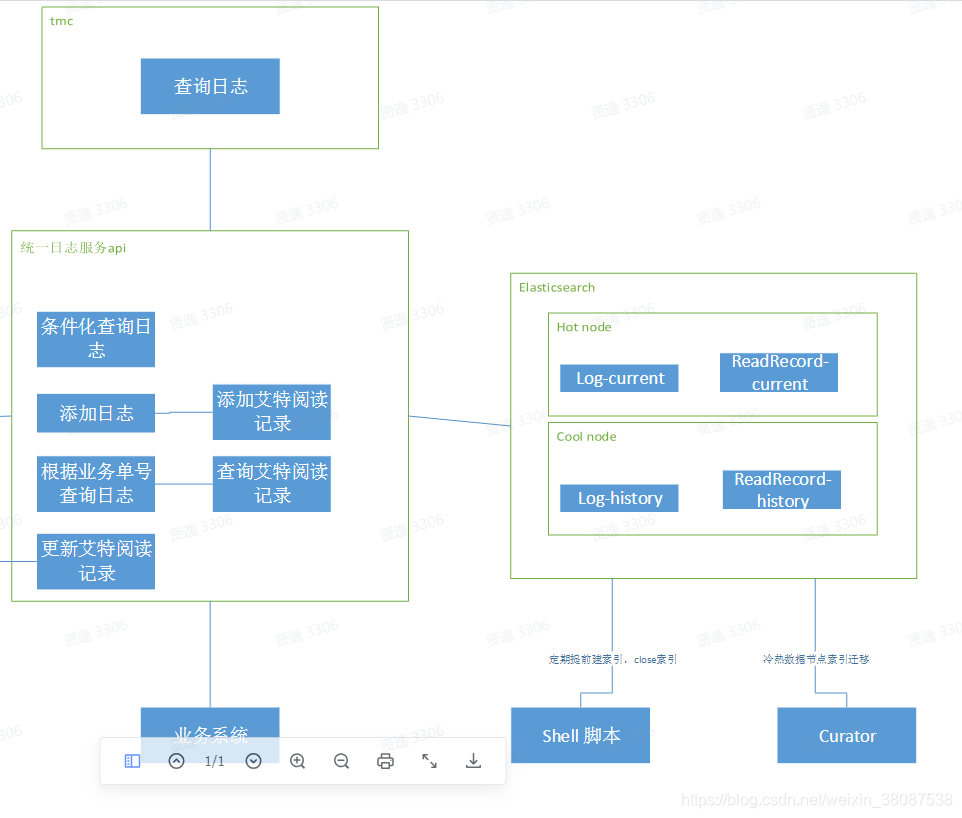
- 日志数据存储按时间建立索引,考虑设置冷热节点来降低成本,对于时间远的index移到冷节点,可以使用ES的索引生命周期管理(ILM)的功能进行管理,数据周期是-热节点-冷节点-关闭,我们使用的是Curator管理索引。
- 对写入性能要求高,写入节点使用固态硬盘,考虑到成本问题,采用冷热数据节点方案降低成本,热点查询,写入数据热数据节点(固态硬盘)进行,历史数据存放冷数据节点(SATA硬盘)
- 我们的业务场景对写入及时性要求很高,目前这种场景的调整硬件是最有效的方式,热节点采用SSD,冷节点用SATA。对于及时性要求不高,最有效的就是用bulk写入,可以采用多线程同时写,调整refresh interval,都有一定作用。
- 考虑到业务应用日志的强时效性要求,不采用logstash+kafka做日志归集,直接写入es
- 热数据节点存放近3个月的索引数据,3个节点,单节点 100G-200G(根据上线后实际量做相应调整),冷数据节点2个500G(后期可根据增长的日志量做横向扩容)
- 按时间线 建立索引,对一段时间内的索引使用相同别名,以方便多个索引同时查询以及冷热数据的迁移,过期数据的删除
- 根据业务keyId 对数据进行自定义路由,以保证同一业务keyId数据存储在同一分片,尽量避免多分片查询后聚合,从而进一步提升查询性能
五、部署方案
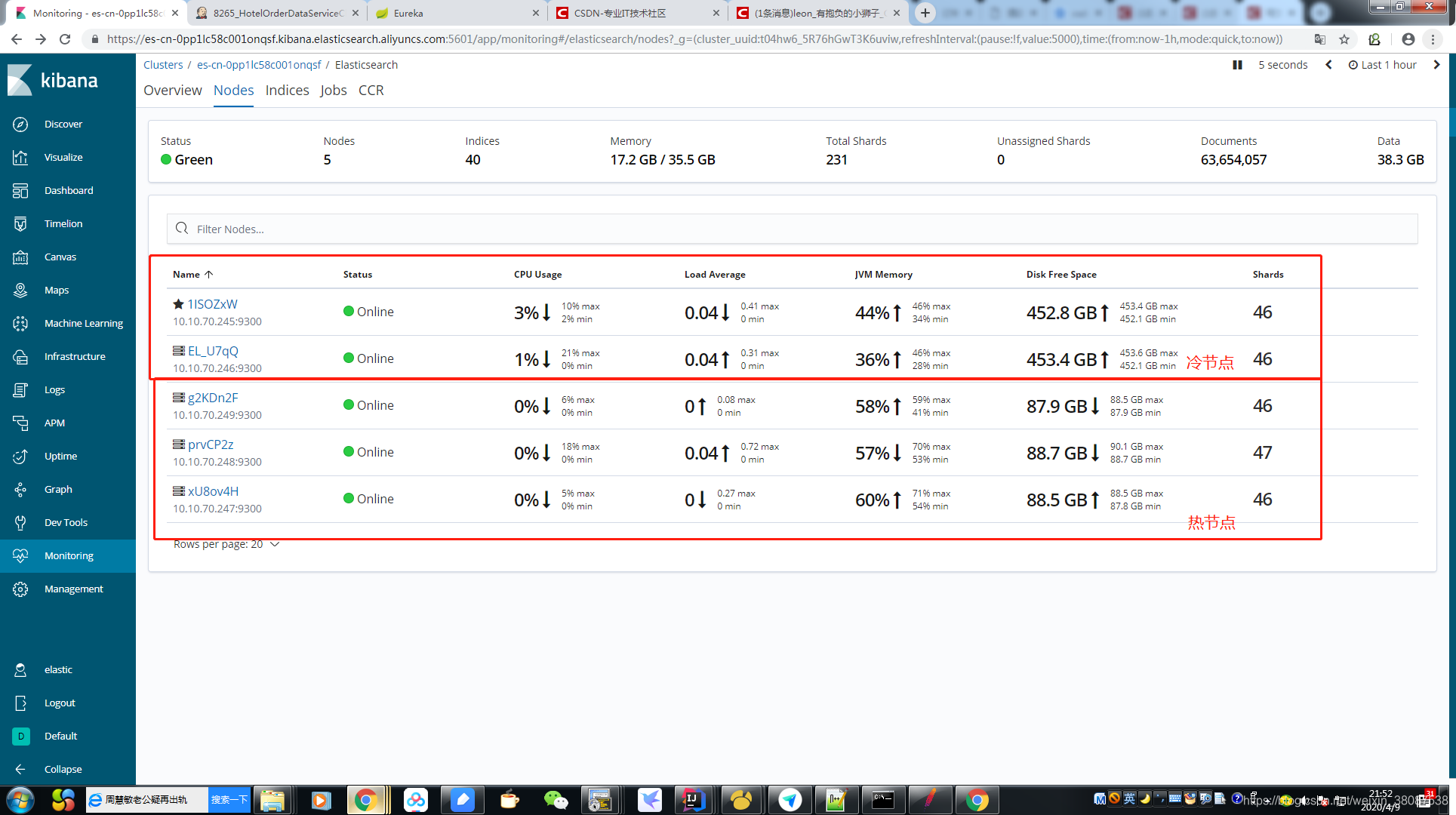
ElasticSearch购买阿里云es,热数据节点3个,4核16G,100G 固态硬盘。冷数据节点2个,4核16G,500GB SATA。(后期磁盘不足,水平扩容节点)
五、ElasticSearch存储设计
1. 索引结构mapping映射与分析设计
- 日志存储数据设计
无检索需求字段统一设置为精确值域,部分需要检索字段使用ik分词器
- 按时间线建立索引
1.Curator定期提前建立索引,并定期更新索引别名,当月数据别名设置为log-current,历史索引数据别名设置为log-history, 这样应用层无需任何代码兼容,即可实现查询多个历史索引
2.带业务id查询场景下查询数据时优先从log-current 索引中查询,无数据时才从log-history中查询数据;无业务ID的查询场景,需指定时间范围进行搜索,且将不使用索引别名,根据所选时间,查询真实索引。
3. 超过半年日志索引close掉,如有必要查询半年前日志数据,手动open后再做查询
- 冷热数据节点
1.分别设置ElasticSearch 的冷热数据节点(node.attr.box_type: “hot/cool” # 标识为热数据节点),热数据节点固态硬盘,冷数据节点SATA硬盘。
-2.新建的索引默认设置存放在热数据节点 “index.routing.allocation.require.box_type”: “hot”,使用ElasticSearch官方索引管理工具Curator 定期将log-history索引(低频访问数据)迁移至冷数据节点
- 自定义路由
1.新增日志数据时,自定义路由进行数据插入,路由规则为业务单号 % num_primary_shards,以确保同一业务单号的数据存放在同一分片,尽量避免多分片查询后聚合,从而进一步提升查询性能。
而涉及到使用业务单号查询的场景,同样需要带上路由值进行查询。
六、技术架构图