写在前面
rancher是最近比较热门的也比较新的东西,是一个开源的企业级的全栈化容器部署与管理平台,其实就是图形化界面式的管理docker和k8s的web服务,操作很傻瓜式,但想完全上手还是需要掌握docker与k8s的一些相关概念的,而且rancher相关的博客比较少,还是有一定难度。最近在老师手把手的指导下(非常感谢任老师~)从无到有地搭了一次分布式集群,并且想尝试在分布式集群上面跑一些深度学习任务,因此需要在rancher上运行jupyter notebook,于是写这篇博客记录一下是如何操作的,给大家避一些坑,也希望能给后来人提供一点点台阶吧。
本文禁止以任何形式转载,违者必追究法律责任!!!
一、创建工作负载
关于如何在服务器上搭rancher,以及rancher如何调用nvidia的gpu,以后有机会再补上吧,这里假设大家已经搭好了rancher。登录进rancher之后,大概是这样的界面:
然后进入集群的某一个项目里,比如这里是进入gpu-demo集群的Default项目里,如下图。一般不要去动System项目,里面运行的都是系统文件。
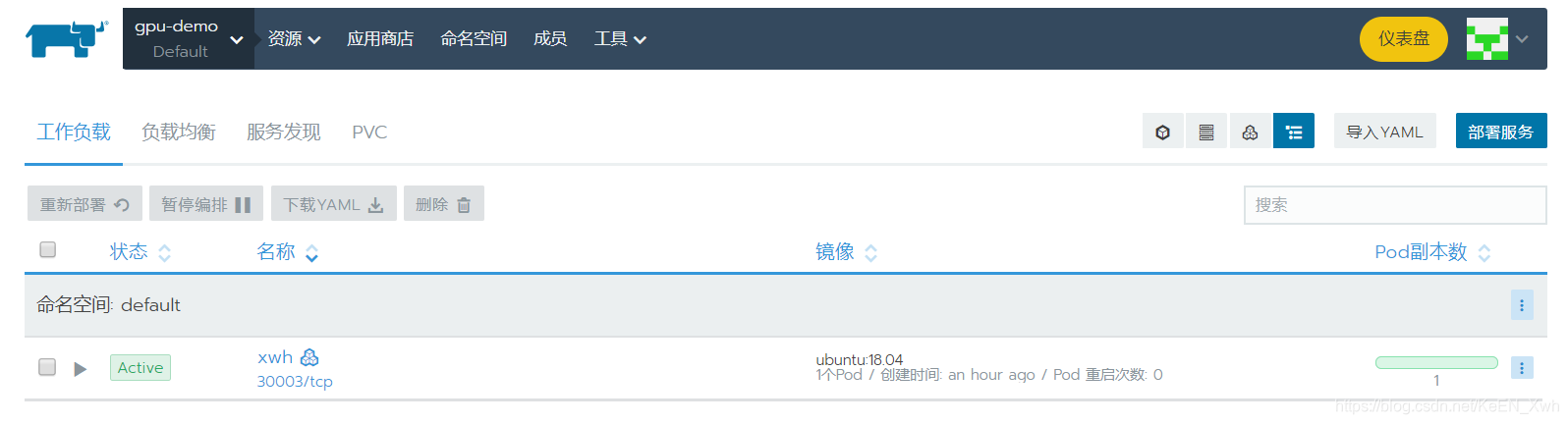
然后进来之后长下图这样,默认命名空间里的xwh是我调试好的工作负载,这里我们重新做一个,点右上角的部署服务:
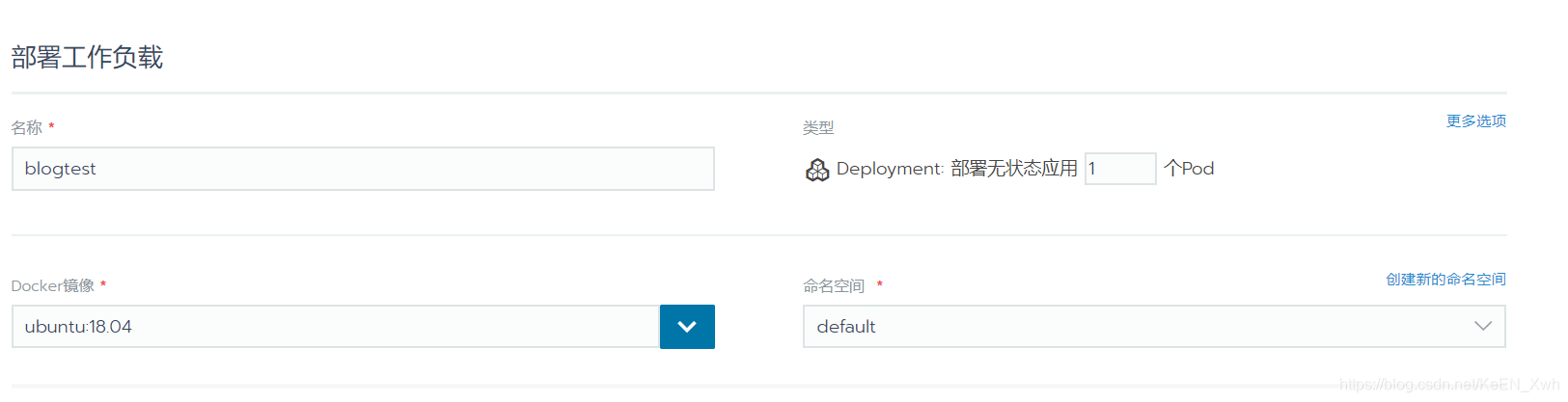
第一步,设置名称,我这里设置的是blogtest;类型默认即可,后续还可以再加Pod;Docker镜像输入ubuntu:18.04,这里的docker镜像可以去docker hub上面搜索,然后按一定的格式在这个选项输入就可以,这里拉取了一个ubuntu操作系统18.04版本镜像(更高的版本应该也可以,但16.04不行,因为16.04默认下载的python3是3.5.几的版本,但是ipython至少要求3.6以上。这些都是踩过的坑啊,把泪目打在弹幕上!啊,没弹幕?那没事了);命名空间可以使用已有的也可以新建,注意和后续某些操作对应即可。
第二步,添加端口映射。不做这个映射的话,能启动jupyter notebook但是无法访问notebook的web界面(这个坑我爬了很久)。

端口名称随意,容器端口设置为8888,这个端口应该是jupyter的默认端口,不过后续也可以查得到,待会再说。如果你需要在一个pod里启动多个notebook,就需要做更多的容器端口映射,比如8889,8890,但我个人更加建议创建多个Pod来满足多个用户使用notebook的需求。协议TCP,网络模式NodePort,主机监听端口这里设置为30010,主机监听端口是我们后面进入notebook的web界面重要“门牌号”,不能冲突,范围是30000-32767。

然后拉到最下面,点启动即可。然后会发现命名空间下多了一个工作负载,正在启动:

进入这个工作负载,可以看到有一个Pod正在拉取镜像,稍等片刻:

主机这里可以看到rancher给你分配了集群中的哪个节点,比如这里分配给我们的是Node2,待会要使用这个节点的ip进入notebook的web界面。这里为了保护隐私,隐去了外网ip,使用内网ip做实验:

几分钟后,可以看到镜像已经拉好了,生成了相应的容器,已经运行在Pod里了。
二、挂nas存储
当然也可以做其他存储方式,比如云存储什么的,如果不做存储,那么你在jupyter上写的代码文件与上传的数据集,会随着工作负载或者Pod的重启而消失,我个人对此的理解是,Pod使用的是虚拟存储,它圈了一块node2这台服务器上的物理存储出来,在上面建立了虚拟的目录与空间,所以一旦关闭就会释放掉,因此我们要将这个虚拟目录与物理存储做一个映射,将我们的.ipynb代码文件与数据集保存下来。没有这个需求的可以跳到第三步安装Jupyter环境去。
首先回到gpu-demo集群的概览界面:
然后点存储下拉里的持久卷(PV):

然后点右上角添加PV:
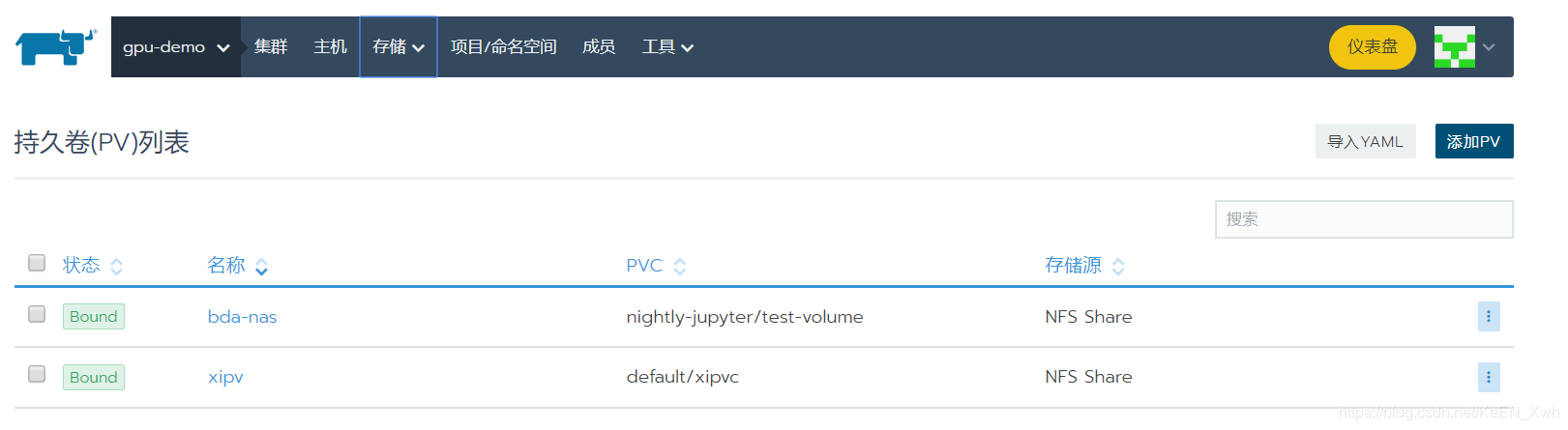
名称随意;卷插件选择 NFS Share;容量看你用作存储的服务器有多大存储,自行设置;路径要写 用作存储的服务器的真实物理目录,这里是/images_harbor,视自己情况而定;服务器这里填入你用作存储的服务器的ip;其他默认即可,点击保存:
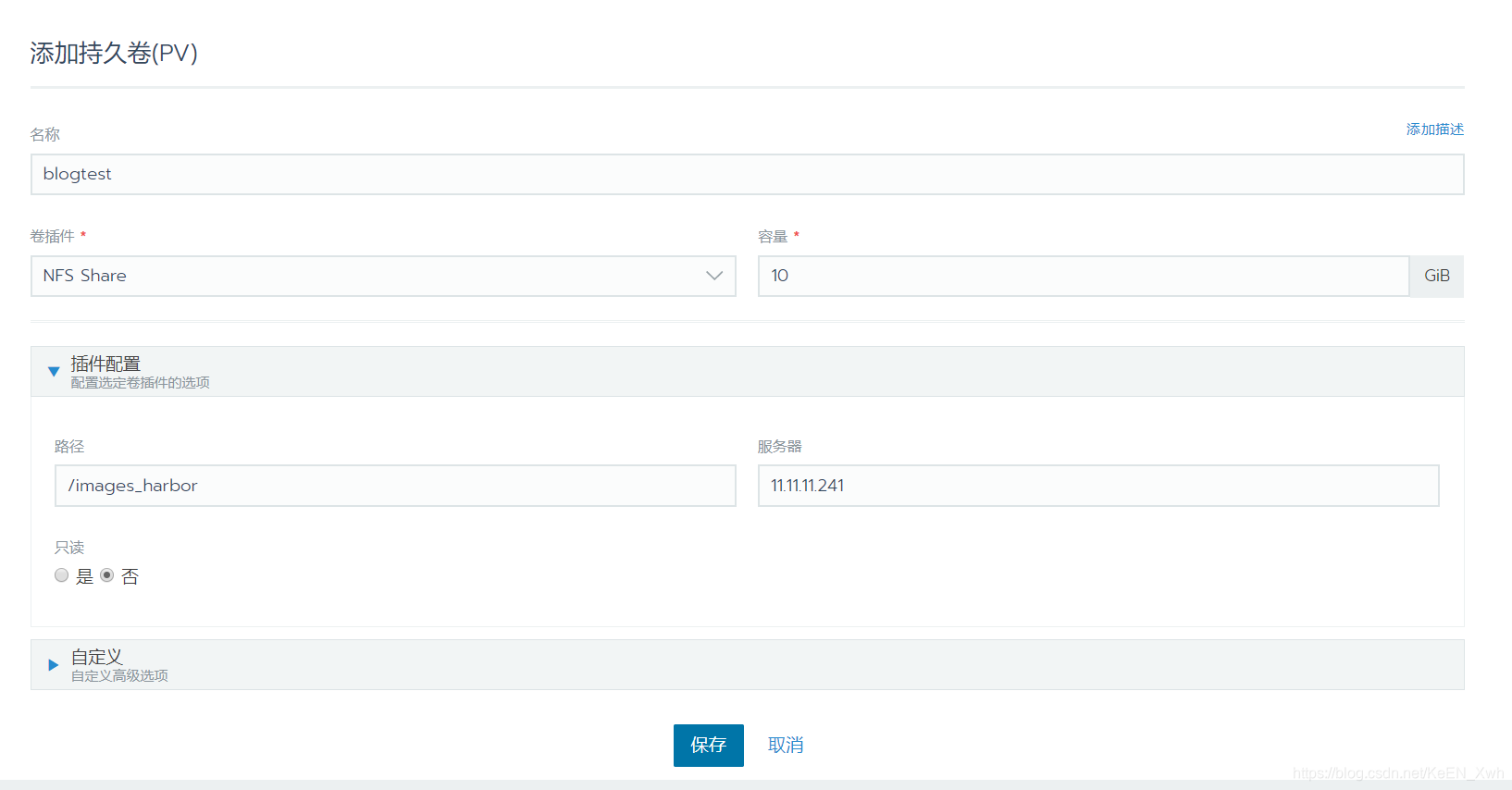
可以看到,多了一个可使用的PV:
回到我们的default项目中去:

然后点击工作负载旁边的PVC:

点右上角添加PVC:
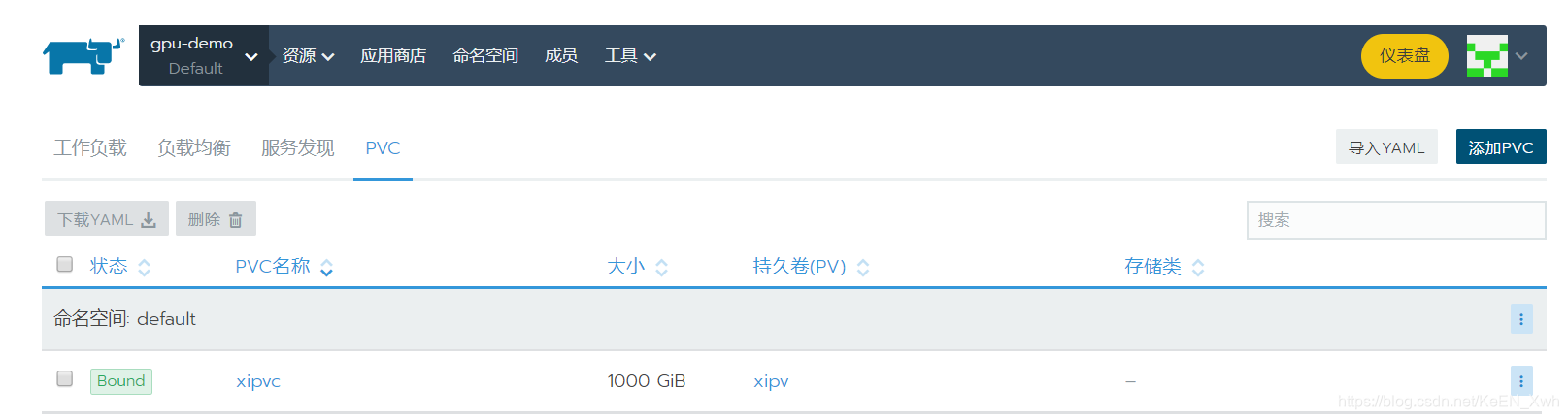
名称随意;命名空间要与刚才在哪建立的工作负载对应起来,这里是default;选择使用现有的持久卷(PV),右边下拉选择刚才我们建立的blogtest这个PV;其他默认即可,点创建:
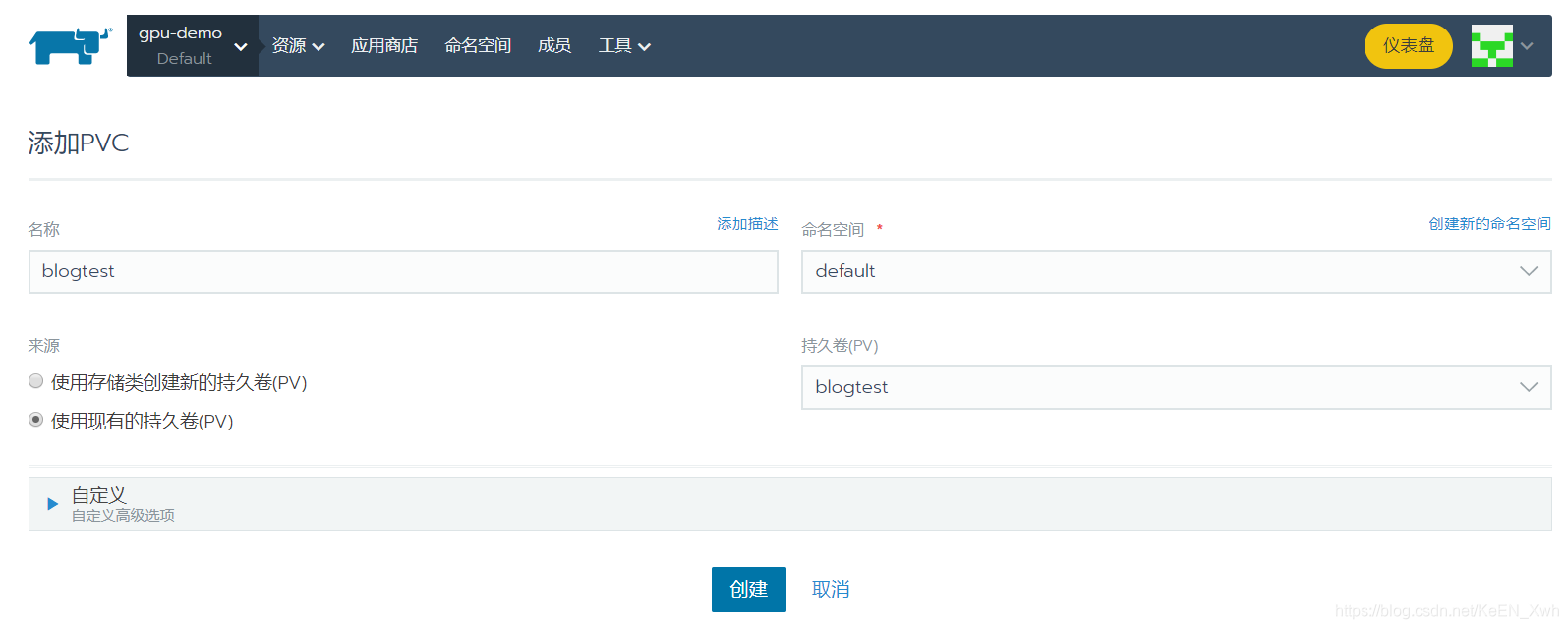
可以看到多了一个blogtest的PVC:

回到我们的工作负载界面,然后点blogtest这一行右边的三个点,下拉里点编辑:
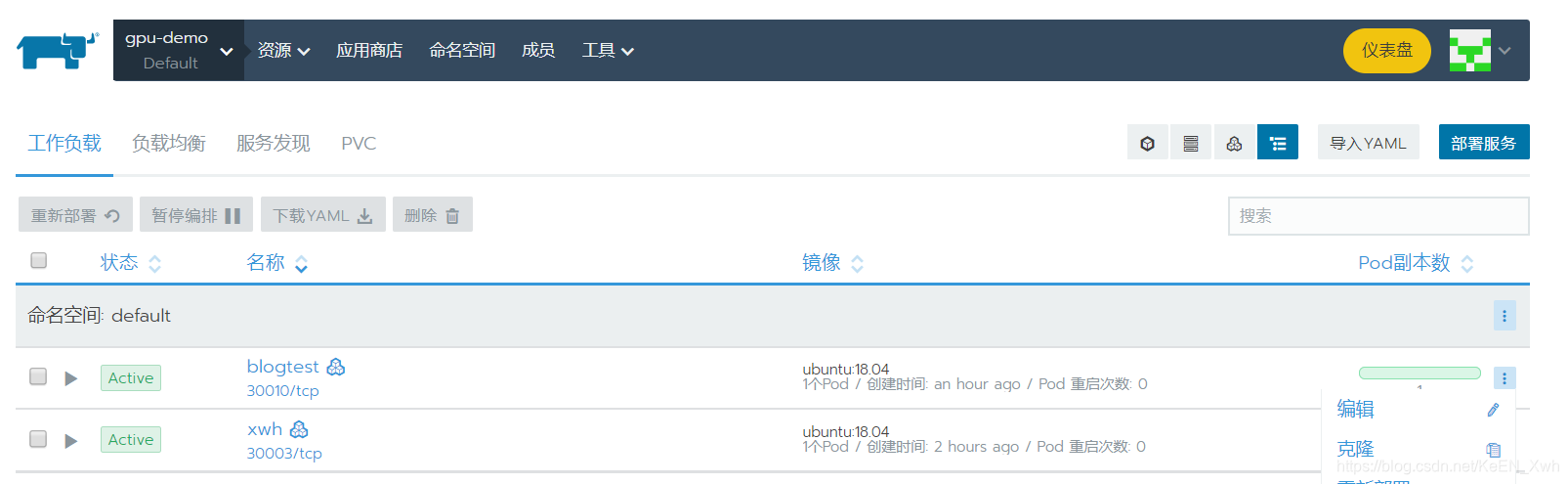
在数据卷设置里,点添加卷:
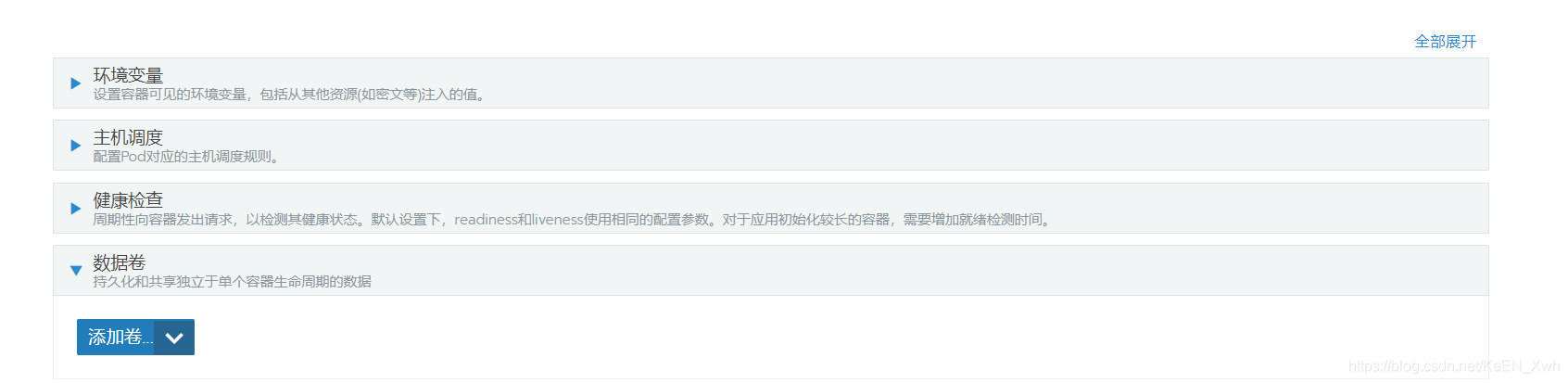
选择使用已有的PVC:

卷名随意;PVC下拉里选择我们刚才建立的blogtest PVC;容器路径要注意,首先必须你当前这个Pod里要有这么个路径(又一坑),其次我们在使用notebook时,.ipynb代码文件也要保存在这个目录下,不然是无法做到存储的,这里设置为/mnt;然后点升级即可:

可以看到在更新了:

三、安装jupyter环境
进入我们的blogtest工作负载:
在当前运行的Pod这一行右边的三个点下拉里选择 执行命令行:
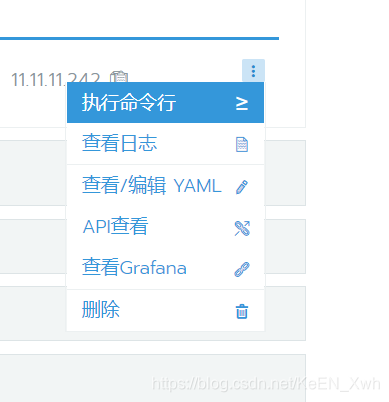
这里就可以运行Linux命令了,首先可以看一下当前我们在哪个目录下,并查看当前目录下有哪些子文件夹,其中就包含了我们刚才设置的/mnt:
然后运行apt-get update与apt-get upgrade更新一下apt的源与包(ubuntu维护了自己的一个软件仓库):
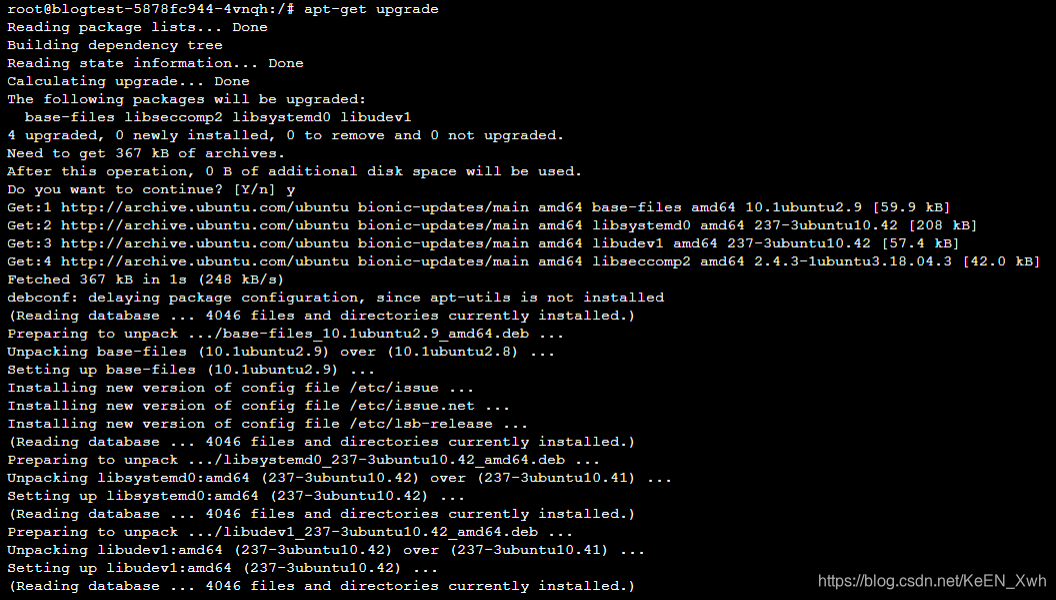
运行apt-get install -y python3来下载python3:

完成之后,看一下python的版本来验证是否安装成功(如果没成功,再运行一下上面的下载命令),这里是成功了:

接着运行apt-get install -y python3-pip来下载pip:

看一下pip3,成功了,(如果没成功,还是一样,再运行一遍上面的下载命令):
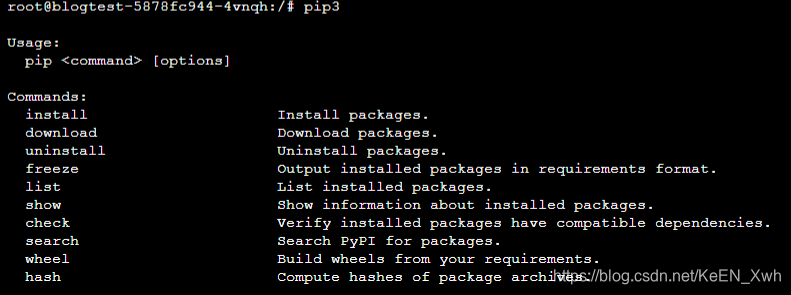
然后用pip3来下载我们的jupyter:

稍等片刻,查看Jupyter版本,可以看到安装成功了:

还需要再安装一个Linux常用的vim来修改文件,马上就要用到它:
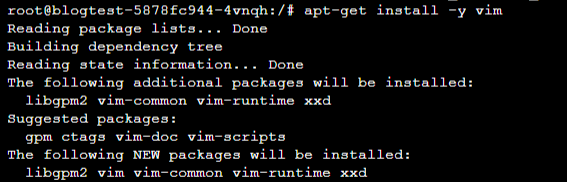
由于我们是远程访问,并不是本地使用jupyter,所以还需要改一下配置文件(又是一个坑,泪目)。输入jupyter notebook --generate-config:

然后使用刚才下载的vim进入这个文件:

找到这么一行:

修改为(单引号里面是*):

这样任何主机都可以访问了。PS:其实在这个文件里能修改很多默认设置,比如设置默认的jupyter notebook端口,设置登录密码等:


然后我们运行jupyter notebook --allow-root来启动jupyter notebook,因为我们现在是root用户一定要加上–allow-root来允许root用户登录(坑啊):
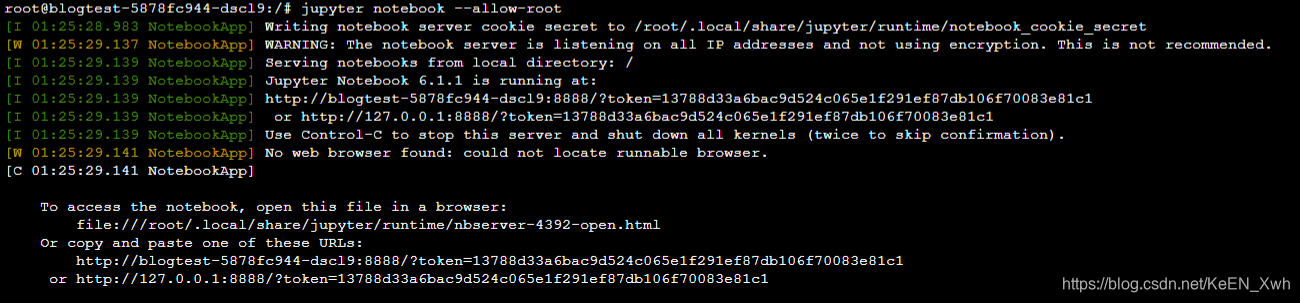
可以看到已经启动成功了,127.0.0.1是jupyter的ip,忽视掉即可;8888即jupyter启动时默认使用的容器端口,这个端口要和我们之前做的端口映射对应起来,不然是无法访问的,也可以在刚才的配置文件里找到那一行命令,修改默认端口避免端口冲突;token=后面的就是密钥了,复制下来,然后在浏览器输入 你的节点ip:主机监听端口,我这里是11.11.11.242:30010:

然后弹出登录界面,我们在最下面的Token粘贴上刚才复制的密钥,并设置登陆密码:
Log in 之后看到jupyter notebook已经可以使用了:
最后,我们来验证一下存储是否挂载成功,首先进入存储服务器,查看挂载nas存储里设置的路径下有哪些文件:

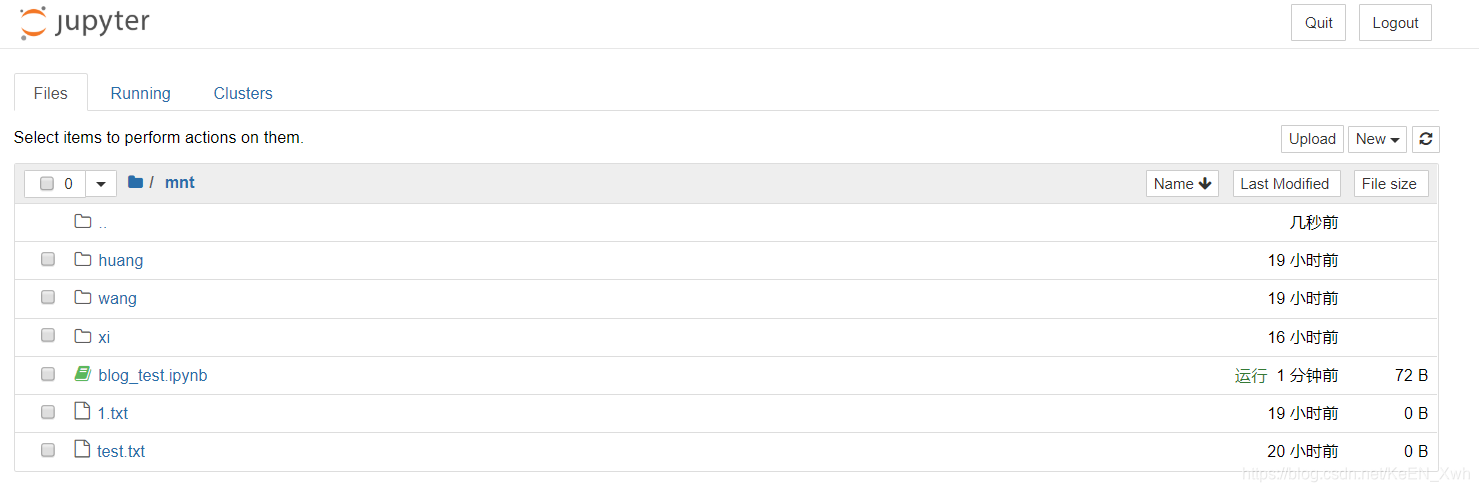
然后回到我们的jupyter界面,进入mnt文件夹:
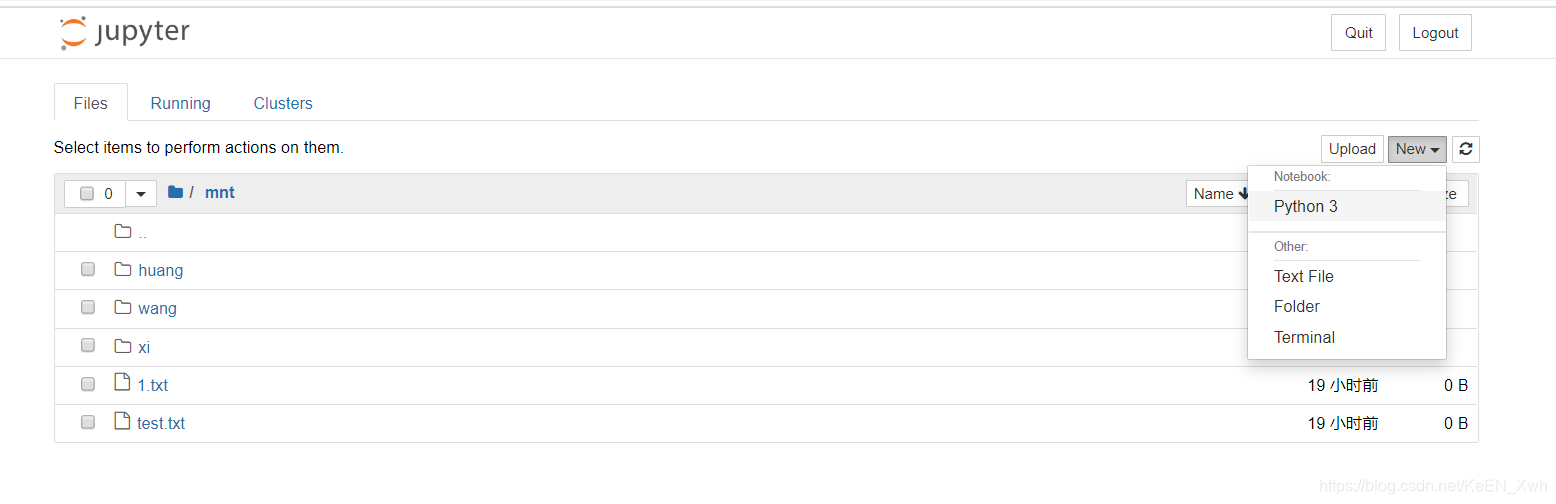
看到已有的文件正是我们存储服务器中images_harbor文件夹里的文件,十有八九是挂上了。然后我们创建一个新的Python3文件,修改名字:
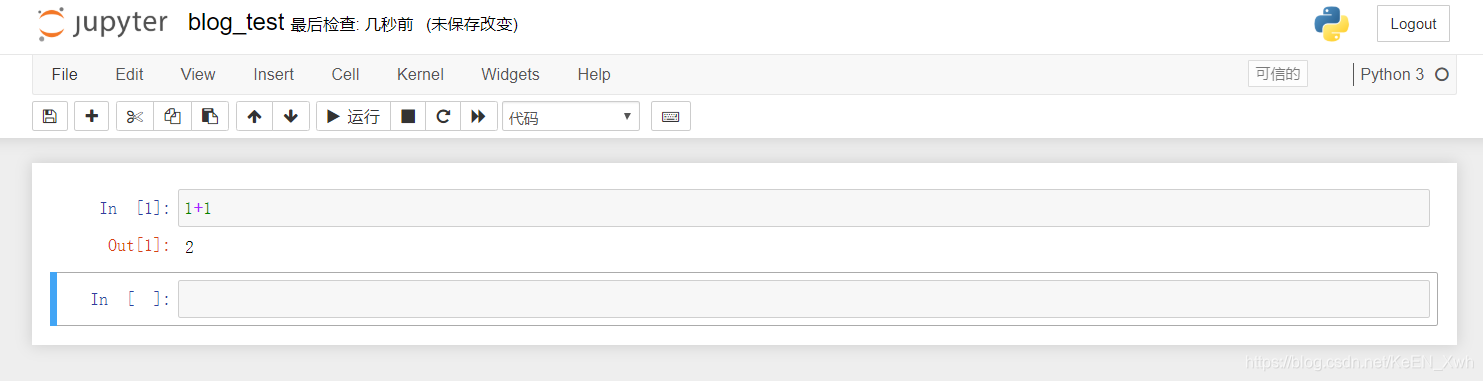
退出来,在/mnt下保存成功了:
再回到存储服务器上来,看一下在这里是否保存成功:
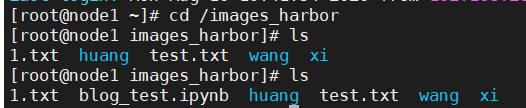
OK,大功告成!!!
写在后面
首先,这项工作其实并没有完全做完,因为一旦重启,我们的代码和数据集是保存下来了,但是镜像并没有保存,什么意思呢?就是如果重启或者新建一个Pod,它拉的镜像还是ubuntu镜像,我们需要把整个第三步再做一遍来配置环境,而且这里我们还没有pip下载需要的一些python库,所以重新做一遍其实工作量还是不小的。如何解决?建立私有的镜像仓库,然后把这个做好的镜像推上去,或者直接推到docker hub上,然后拉这个新镜像即可。
可能有人就会问,为什么不直接拉一个jupyter notebook的镜像?那这里就是另一个天坑了,我在docker hub上搜索jupyter镜像:
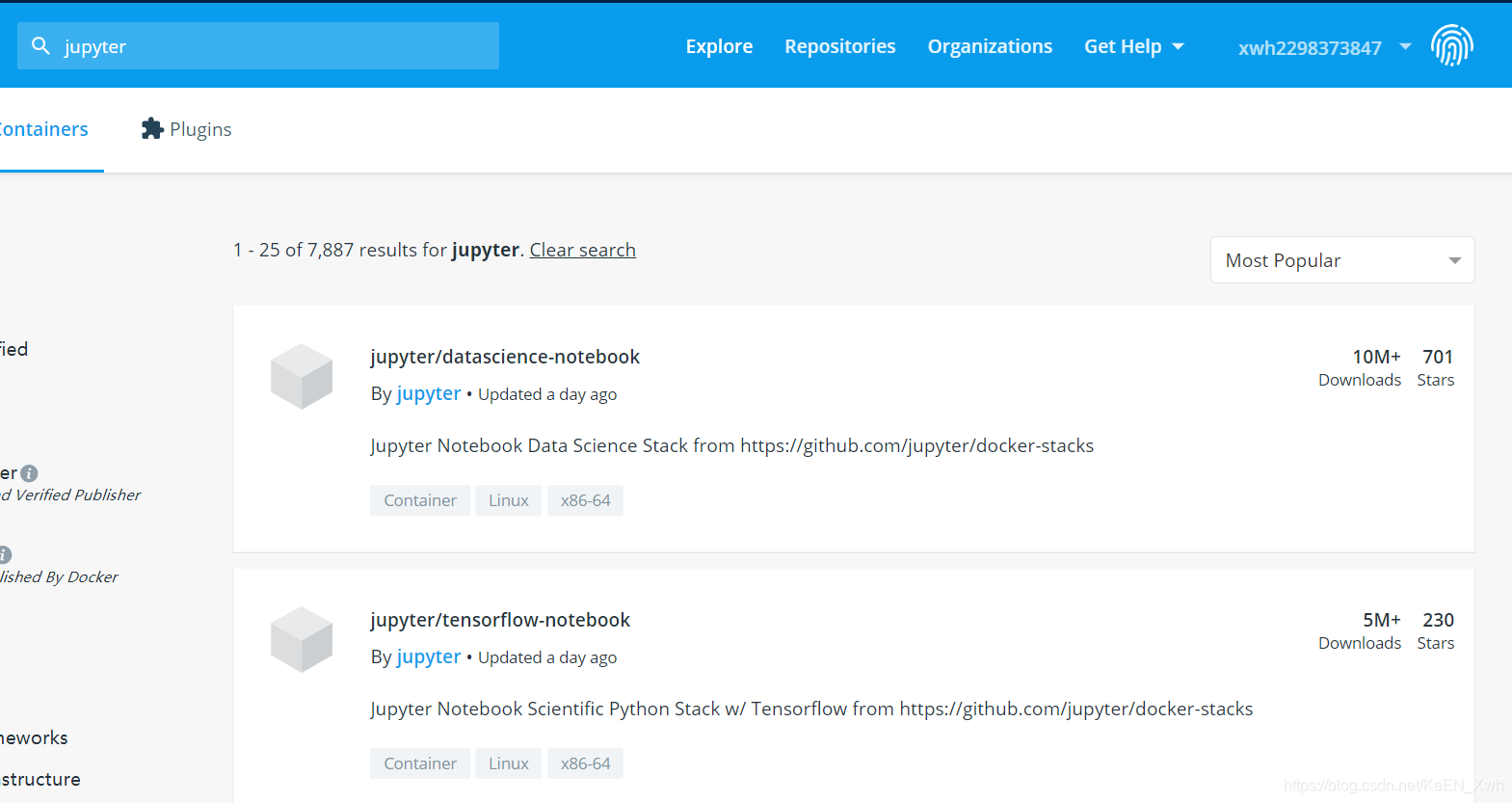
比如这里第一个jupyter/datascience-notebook镜像,你把它拉下来之后,会发现默认是一个user账户,而且无法切换到root账户,因为你不知道password,我查了一下它的文档,关于这方面是这么写的,大家自己感受:

但这个user账户也可以下载我们需要的依赖和库,那么问题会出在哪?当你挂好存储之后,你会发现你无法在你挂载的文件夹里新建文件,因为你权限不够!所以如果没有存储需求的用户,当然可以直接拉上面这个镜像,只需要做8888的容器映射,不需要再运行其他命令,启动时已经默认启动Jupyter Notebook了,可以在日志里查看到token,打开浏览器输入ip:主机监听端口即可。
如何在rancher上运行jupyter botebook这个看起来半个小时就能搞定的任务,我大概用了十天才摸索出来,踩了很多坑,属实不易,记得点赞~~~