Flume简介
Flume是Cloudera提供的日志收集系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
Flume是一个分布式、可靠和高可用的海量日志采集、聚合和传输的系统。
Flume拥有基于数据流上的简单灵活架构,支持容错、故障转移与恢复。
Flume具有Reliability、Scalability、Manageability和Extensibility特点:
1.Reliability:Flume提供3中数据可靠性选项,包括End-to-end、Store on failure和Best effort。其中End-to-end使用了磁盘日志和接受端Ack的方式,保证Flume接受到的数据会最终到达目的。Store on failure在目的不可用的时候,数据会保持在本地硬盘。和End-to-end不同的是,如果是进程出现问题,Store on failure可能会丢失部分数据。Best effort不做任何QoS保证。
2.Scalability:Flume的3大组件:collector、master和storage tier都是可伸缩的。需要注意的是,Flume中对事件的处理不需要带状态,它的Scalability可以很容易实现。
3.Manageability:Flume利用ZooKeeper和gossip,保证配置数据的一致性、高可用。同时,多Master,保证Master可以管理大量的节点。
4.Extensibility:基于Java,用户可以为Flume添加各种新的功能,如通过继承Source,用户可以实现自己的数据接入方式,实现Sink的子类,用户可以将数据写往特定目标,同时,通过SinkDecorator,用户可以对数据进行一定的预处理。
Flume架构

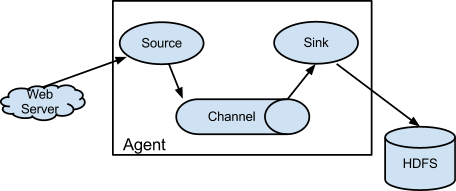
上图的Flume的架构中最重要的抽象是data flow(数据流),data flow描述了数据从产生,传输、处理并最终写入目标的一条路径(在上图中,实线描述了data flow)。 Agent用于采集数据,agent是flume中产生数据流的地方,同时,agent会将产生的数据流传输到collector。对应的,collector用于对数据进行聚合,往往会产生一个更大的流。
Client:客户端,数据产生的地方,如Web服务器
Event:事件,指通过Agent传输的单个数据包,如日志数据通常对应一行数据
Agent:代理,一个独立的JVM进程
Flume以一个或多个Agent部署运行
Agent包含三个组件:
1.Source
2.Channel
3.Sink
如下图所示:

Flume提供了从console(控制台)、RPC(Thrift-RPC)、text(文件)、tail(UNIX tail)、syslog(syslog日志系统,支持TCP和UDP等2种模式),exec(命令执行)等数据源上收集数据的能力。同时,Flume的数据接受方,可以是console(控制台)、text(文件)、dfs(HDFS文件)、RPC(Thrift-RPC)和syslogTCP(TCP syslog日志系统)等。
其中,收集数据有2种主要工作模式,如下:
1. Push Sources:外部系统会主动地将数据推送到Flume中,如RPC、syslog。
2. Polling Sources:Flume到外部系统中获取数据,一般使用轮询的方式,如text和exec。
注意:
在Flume中,agent和collector对应,而source和sink对应。Source和sink强调发送、接受方的特性(如数据格式、编码等),而agent和collector关注功能。
Flume管理方式
Flume Master用于管理数据流的配置,如下图:

为了保证可扩展性,Flume采用了多Master的方式。为了保证配置数据的一致性,Flume引入了ZooKeeper,用于保存配置数据,ZooKeeper本身可保证配置数据的一致性和高可用,另外,在配置数据发生变化时,ZooKeeper可以通知Flume Master节点。
Flume Master间使用gossip协议同步数据。
安装部署Flume
1.安装nc
yum install nmap-ncat.x86_64 -y
2.下载flume地址
http://flume.apache.org/download.html
如下图所示下载flume-1.5.2-bin.tar.gz:

3.拖到opt目录下开始解压
cd /opt
tar -zxf flume-ng-1.5.2-cdh5.14.2.tar.gz
4.移动到opt目录的soft文件夹下
mkdir soft
mv apache-flume-1.5.2-cdh5.14.2-bin soft/flume152
5.配置flume-env.sh文件的JavaHome环境变量
cd soft/flume152/conf
6.拷贝flume-env.sh.template文件改成 flume-env.sh
cp flume-env.sh.template flume-env.sh
7.添加jdk环境变量
export JAVA_HOME=/opt/soft/jdk180
8.配置flume的环境变量
vi /etc/profile
export FLUME_HOME=/opt/soft/flume152
export PATH=$PATH:$FLUME_HOME/bin9.激活
source /etc/profile
10.验证是否安装成功在bin 目录下
./flume-ng version
如下图所示:

单节点Flume配置
1.创建目录用于放配置文件
mkdir /opt/flumeconf
cd /opt/flumeconf/
2.创建文件夹用于存放要读取的文件
mkdir soft/datas
3.重命名 conf/flume-conf.properties.template 文件为 flume-conf.properties,并修改为以下内容:
cp flume-conf.properties.templat flume-conf.properties
vi flume-conf.properties
#Agent: 名称定义为 a1
#Source:可以理解为输入端,定义名称为 r1
#channel:传输频道,定义为 c1,设置为内存模式
#sinks:可以理解为输出端,定义为 s1
#命名此代理上的组件别名
a1.sources = r1
a1.channels = c1
a1.sinks = s1
#描述配置源
#设置 Source 的类型为 netcat 端口为 6666,以及主机ip
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.5.150
a1.sources.r1.port = 6666
#描述接收器
#设置 Sink 为 logger 模式
a1.sinks.s1.type = logger
#设置 channel 信息
a1.channels.c1.type = memory
#内存模式
a1.channels.c1.capacity = 1000
#通道中最大的缓冲事件,要大于或等于batchSize的数
a1.channels.c1.transactionCapacity = 100
#将源和接收器绑定到通道
a1.sources.r1.channels = c1
a1.sinks.s1.channel = c1先启动flume
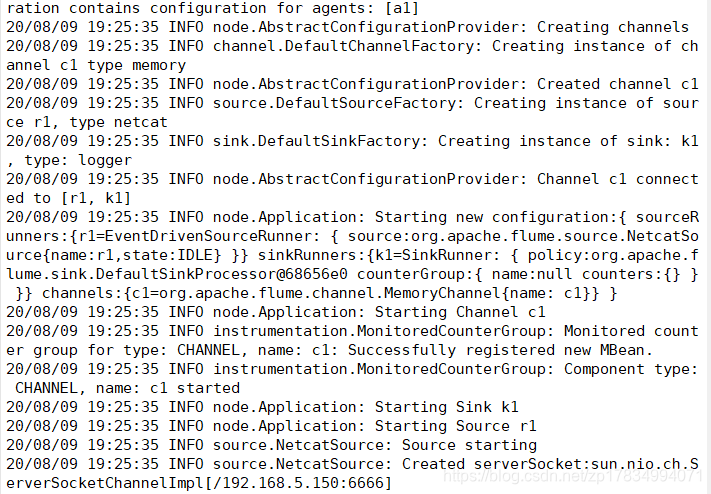
flume-ng agent -n a1 -c conf -f /opt/soft/flume152/conf/flume-conf.properties -Dflume.root.logger=INFO,console
如下图所示说明已经启动成功!
新开窗口,再启动nc
nc 192.168.5.150 6666
在nc中发送测试数据最后验证 flume 是否接收到了数据
如下图所示:
在nc中输入数据

在flume中接收到测试的数据,如下图所示:

这时说明已经安装成功!
测试收集日志到HDFS
1.把要读取的文件拖到/opt/soft/datas下
cd /opt/soft/datas
2.创建hdfs文件
hdfs dfs -mkdir /tmp/customs
3.在/opt/flumeconf下创建properties文件,并添加配置
vi conf_0809_readline.properties
a2.channels=c2
a2.sources=s2
a2.sinks=k2
a2.sources.s2.type=spooldir
a2.sources.s2.spoolDir=/opt/soft/datas
a2.channels.c2.type=memory
a2.channels.c2.capacity=10000
a2.channels.c2.transactionCapacity=1000
//类型为hdfs
a2.sinks.k2.type=hdfs
//上传的hdfs路径
a2.sinks.k2.hdfs.path=hdfs://192.168.5.150:9000/tmp/customs
//生成的文件前缀名
a2.sinks.k2.hdfs.filePrefix=events-
//每5000条数据生成一个文件
a2.sinks.k2.hdfs.rollCount=5000
//触发滚动的文件大小以字节为单位
a2.sinks.k2.hdfs.rollSize=600000
//传到HDFS的数据为每500条
a2.sinks.k2.hdfs.batchSize=500
//将源和接收器绑定到通道c1
a2.sinks.k2.channel=c2
a2.sources.s2.channels=c2启动flume开始监听文件到hdfs
flume-ng agent -n a2 -c conf -f /opt/flumeconf/conf_0809_readline.properties -Dflume.root.logger=INFO,console
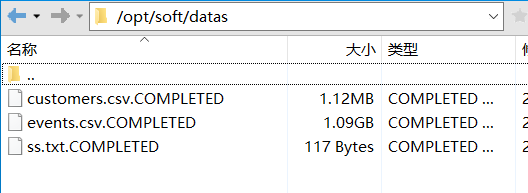
当文件全部读取完成后,会在datas文件夹下看到读取成功的文件名后缀有.COMPLETED表示读完此次文件,如图所示:
这时在hdfs上能看到文件已经上传成功了,如图所示:
