实验环境
centos 7;cdh5.15; anaconda3
问题描述
笔者使用Cloudera Manager对集群中的机器进行分配组件,这里用的就是Spark2组件。
python 环境,及这些组件都安装好,在Pyspark交互界面读取文件时报错:
Caused by: java.io.IOException: Cannot run program "/root/anaconda3/bin/python": error=13, Permission denied
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1048)
at org.apache.spark.api.python.PythonWorkerFactory.startDaemon(PythonWorkerFactory.scala:197)
at org.apache.spark.api.python.PythonWorkerFactory.createThroughDaemon(PythonWorkerFactory.scala:122)
at org.apache.spark.api.python.PythonWorkerFactory.create(PythonWorkerFactory.scala:95)
at org.apache.spark.SparkEnv.createPythonWorker(SparkEnv.scala:117)
at org.apache.spark.api.python.BasePythonRunner.compute(PythonRunner.scala:108)
at org.apache.spark.api.python.PythonRDD.compute(PythonRDD.scala:65)
at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:324)
at org.apache.spark.rdd.RDD.iterator(RDD.scala:288)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:90)
at org.apache.spark.scheduler.Task.run(Task.scala:121)
at org.apache.spark.executor.Executor$TaskRunner$$anonfun$10.apply(Executor.scala:403)
at org.apache.spark.util.Utils$.tryWithSafeFinally(Utils.scala:1405)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:409)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
... 1 more
Caused by: java.io.IOException: error=13, Permission denied
at java.lang.UNIXProcess.forkAndExec(Native Method)
at java.lang.UNIXProcess.<init>(UNIXProcess.java:247)
at java.lang.ProcessImpl.start(ProcessImpl.java:134)
at java.lang.ProcessBuilder.start(ProcessBuilder.java:1029)
问题分析及解决
根据以上报错,说的就是无访问权限。这可都是系统默认安装的,这是怎么回事呢?一脸尼克杨问号!!!!
之后就是google、baidu和bing 各种检索。大多说的是:修改环境变量~/.bashrc,其实这一点我早就改过了,还是未能解决。
对了,这里提一下。对于这个报错,要看你是如何安装spark。我是手动,用Cloudera Manager分配都试过。至此手动安装的是可以正常读取HDFS文件(这个报错也是容易解决),唯独使用Cloudera Manager 分配的组件不能正常工作。
手动安装 Spark
这里也说下手动安装Spark,环境变量的配置。
我是参考厦门大学数据库实验室来做的,给出了链接
使用 Clouder Manager 分配
在网上搜索找到下图:

意思就是在每个节点上都要有相同的Python,由于这一个问题好久都没解决,但凡有希望那都得去试试。于是在七台虚拟机上挨个装了 anaconda ,真是苦力活,但是未果(不过也建议个节点上保持版本一致)。
继续解决,直到看到下面两张图:
首先这位作者先是抛出问题,和我的报错很像。
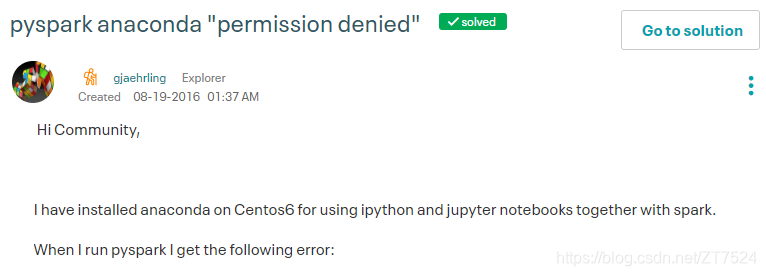
最后,看到他自己回帖。说是重新安装了anaconda到/opt/anaconda目录下问题得以解决。
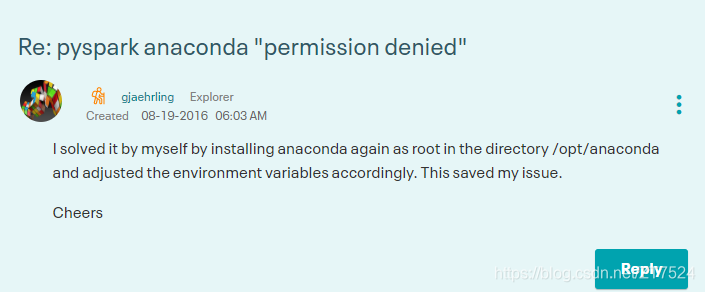
安装上面给的提示,我将anaconda重新安装在/opt/目录下(默认是安装在 /root目录下),果然可以正常读取HDFS中的数据了。
linux系统安装 anaconda 参考文件
注意:这里安装完之后,记得修改 ~/.bashrc 文件中的环境变量
export PYSPARK_DRIVER_PYTHON=ipython
export PYSPARK_PYTHON=/opt/anaconda/bin/python
成功读取HDFS文件:
(base) [root@slave3 opt]# pyspark2
Python 3.7.3 (default, Mar 27 2019, 22:11:17)
Type 'copyright', 'credits' or 'license' for more information
IPython 7.4.0 -- An enhanced Interactive Python. Type '?' for help.
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
19/08/07 14:15:17 WARN lineage.LineageWriter: Lineage directory /var/log/spark2/lineage doesn't exist or is not writable. Lineage for this application will be disabled.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 2.4.0.cloudera1
/_/
Using Python version 3.7.3 (default, Mar 27 2019 22:11:17)
SparkSession available as 'spark'.
In [1]: input = sc.textFile("/user/platform/dga/output_file/20190610172348.txt")
In [2]: input.first()
Out[2]: 'baidu.com,legit,0.15,0.85'
In [3]: input.take(10)
Out[3]:
['baidu.com,legit,0.15,0.85',
'taobao.com,legit,0.0,1.0',
'vovo.tech,legit,0.0,1.0',
'ecmychar.live,legit,0.05,0.95',
至此,这个闹心的问题得以解决。真正解决问题的方式很简单,但是找出问题出错原因是真不容易。
从一名不羁的码农开始,谈风月之余谈技术
