一、cmf-agent: error: argument --hostname is required
描述:启动cloudera-scm-agent失败
解决:主机名(hostname)要跟/etc/hosts里配置的一样
二、/opt/cloudera/目录更换操作
描述:CDH的parcel等文件默认放在/opt/cloudera目录下,但一般情况下这个目录的磁盘空间都比较小,需要把这些文件放到空间大的目录,可以通过修改配置文件来做,但这样比较麻烦,可能还会有一些遗留问题,下面介绍一种使用软链接的方式
解决:
mkdir -p /data/cloudera/parcel
mv /opt/cloudera/ /data/cloudera/parcel/
ln -s /data/cloudera/parcel/cloudera/ /opt/cloudera
这样文件实际存储位置就在/data盘,同理 /var/log /var/lib目录也可以这样做
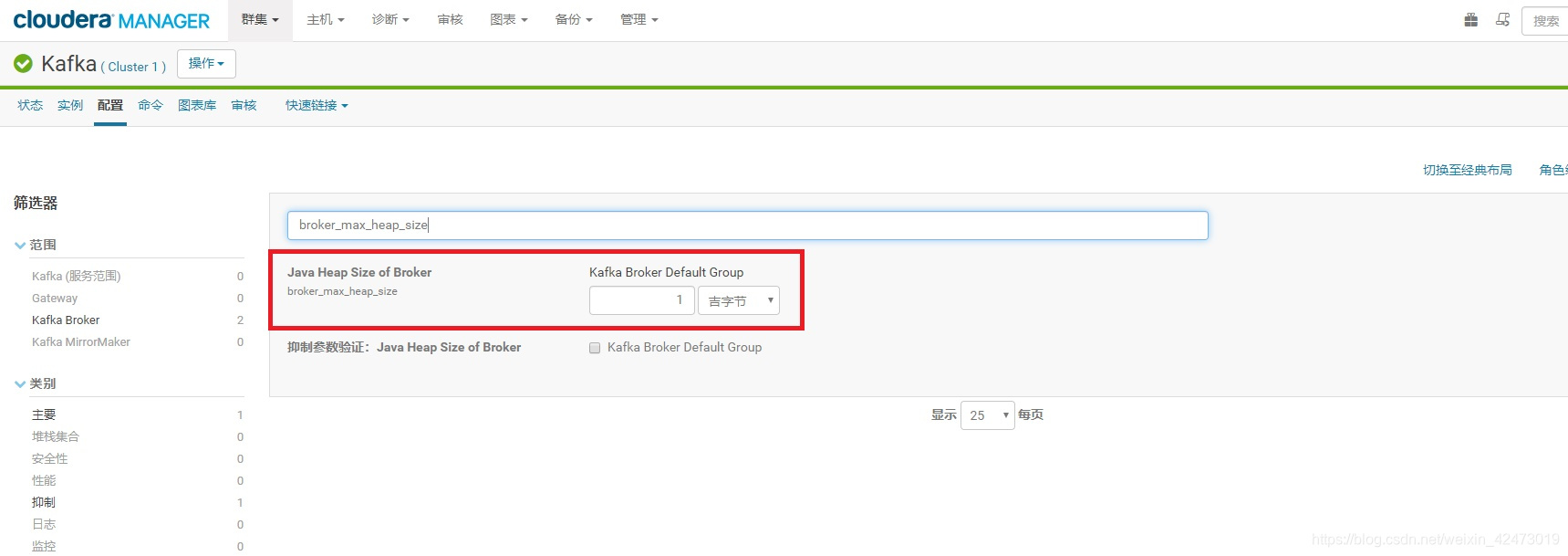
三、CDH kafka启动失败
解决:调整broker_max_heap_size参数,最小256MB
四、CDH Hue打开workflow报错
描述: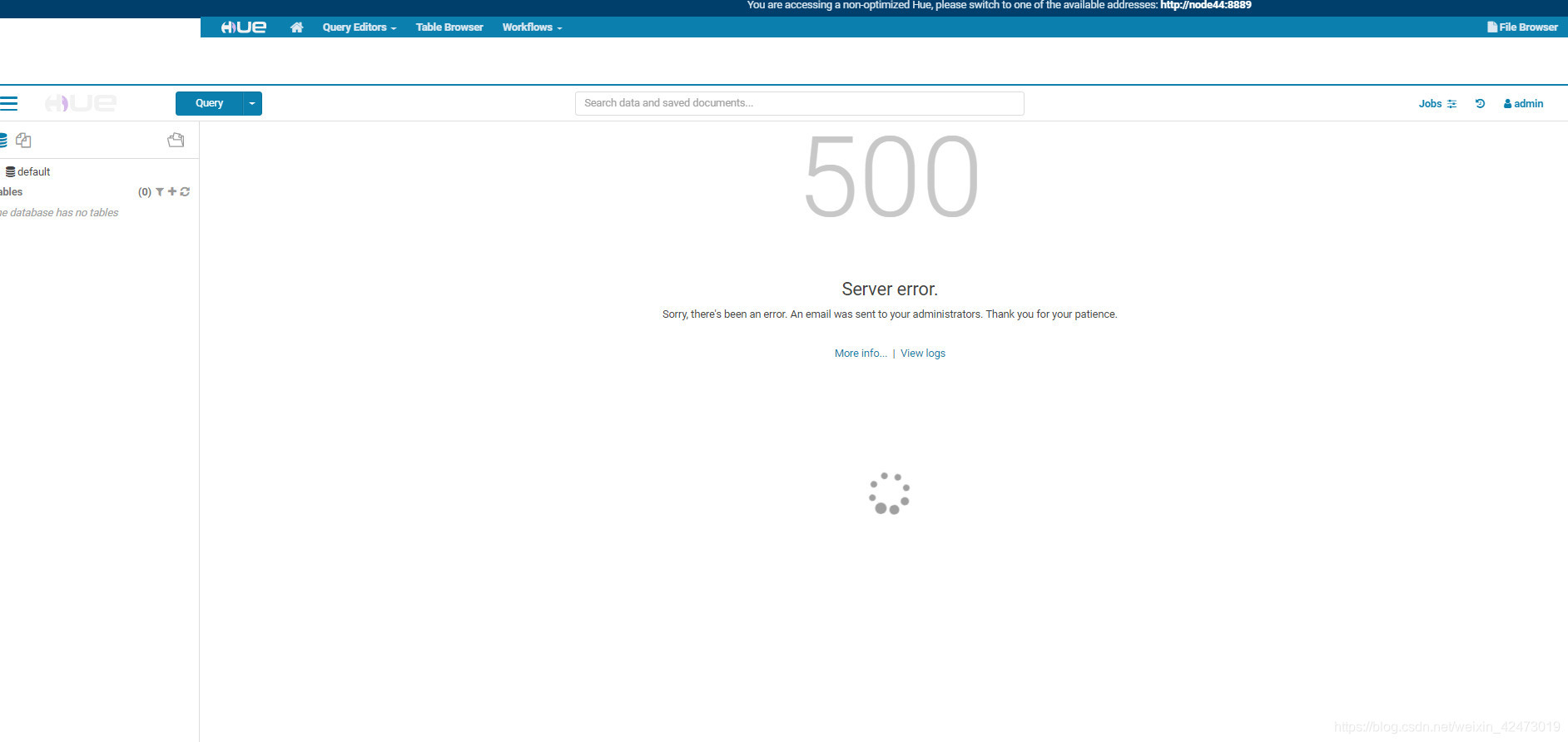
解决:这是因为我之前HDFS开启了高可用,HUE的webhdfs_url参数配置为了standby的那台namenode,重新配置成active的namenode就行了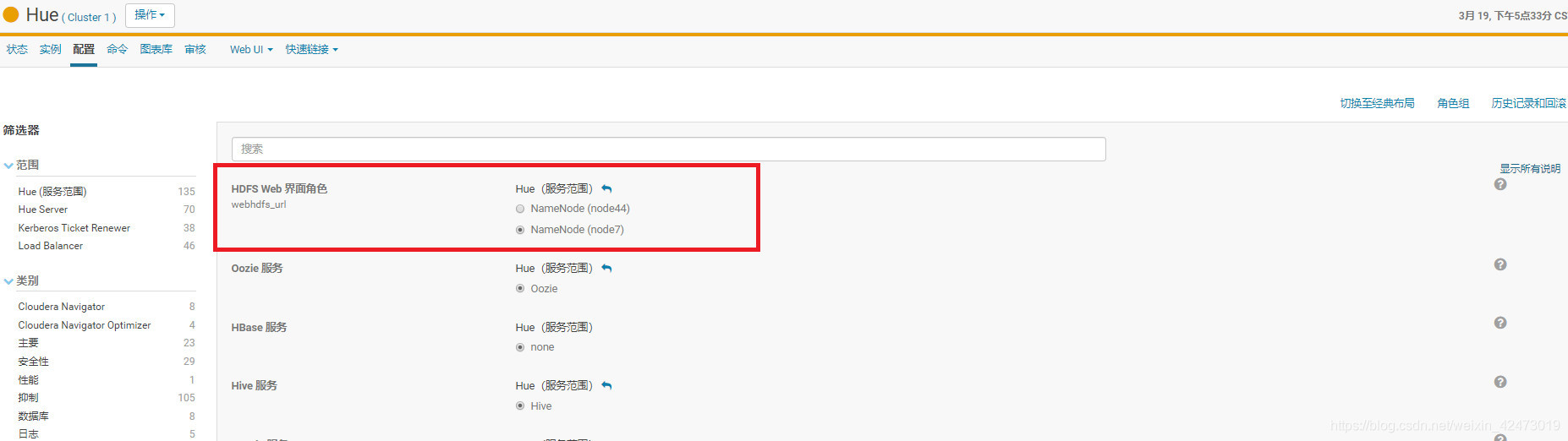
五、org.apache.hadoop.security.AccessControlException: Permission denied: user=root, access=WRITE, inode="/":hdfs:supergroup:drwxr-xr-x
解决:用户权限不足,在/etc/profile里添加export HADOOP_USER_NAME=hdfs,然后source /etc/profile
六、Kafka报错:While recording the replica LEO, the partition topic_test-1 hasn’t been created
解决:把这个topic删掉
七、cm_processes空间不足
描述:
如图,CDH在运行时会有这样一个进程,如果它的Avail不足,集群会报错
解决:
service cloudera-scm-agent next_start_clean
service cloudera-scm-agent next_stop_hard
service cloudera-scm-agent stop
service cloudera-scm-agent start
这样把agent重启一下
八、Hive客户端启动报错:Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
解决:
vim hive-env.sh
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
source hive-env.sh
九、HUE oozie 执行hive shell报错:Job init failed : org.apache.hadoop.yarn.exceptions.YarnRuntimeException: java.io.FileNotFoundException: File does not exist: hdfs://nameservice1/user/hdfs/.staging/job_1585646243093_0033/job.splitmetainfo
解决:给shell任务添加环境变量 HADOOP_USER_NAME=${wf:user()}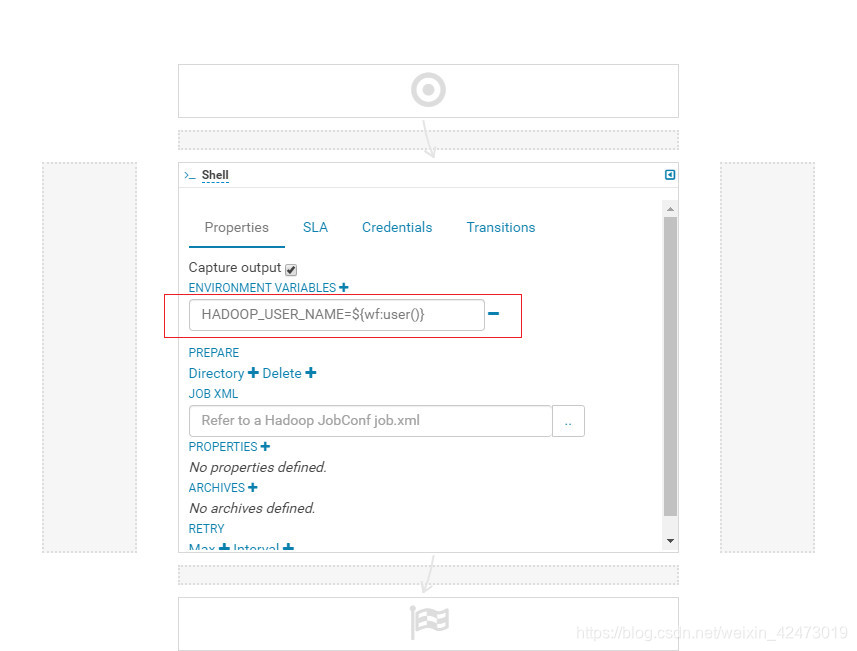
十、Mysql配置主从复制后报错:Caused by: java.sql.SQLException: Cannot execute statement: impossible to write to binary log since BINLOG_FORMAT = STATEMENT and at least one table uses a storage engine limited to row-based logging. InnoDB is limited to row-logging when transaction isolation level is READ COMMITTED or READ UNCOMMITTED.
解决:
vim /etc/my.cnf
添加 binlog_format=ROW
然后重启mysql
十一、执行spark-shell报错:Caused by: java.lang.ClassNotFoundException: org.apache.hadoop.fs.FSDataInputStream
解决:spark-env.sh 添加 export SPARK_DIST_CLASSPATH=$(hadoop classpath)
十二、spark整合hive查询hive表报错:Caused by: java.lang.IllegalArgumentException: Compression codec com.hadoop.compression.lzo.LzopCodec not found.Caused by: java.lang.ClassNotFoundException: Class com.hadoop.compression.lzo.LzopCodec not found
描述:因为之前给HDFS和Hive配置了LZO压缩
解决:
1、spark-env.sh添加:(把 $ 后面的空格去掉!)
export LD_LIBRARY_PATH=$ LD_LIBRARY_PATH:/opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/native
export SPARK_LIBRARY_PATH=$ SPARK_LIBRARY_PATH:/opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/native
export SPARK_CLASSPATH=$ SPARK_CLASSPATH:/opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/*
2、spark-defaults.conf添加:
spark.driver.extraClassPath /opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/hadoop-lzo.jar
spark.executor.extraClassPath /opt/cloudera/parcels/HADOOP_LZO/lib/hadoop/lib/hadoop-lzo.jar
十三、sqoop导Hive表进Mysql报错:org.kitesdk.data.DatasetNotFoundException: Descriptor location does not exist: hdfs://nameservice1/warehouse/cloudtj/dws/image_dealvideo/.metadata
描述:如果sqoop使用的是
–export-dir /warehouse/cloudtj/dws/image_dealvideo
这样的参数方式导出parquet格式的hive表进mysql,会报上面这个错,需要使用下面这个参数
解决:
–hcatalog-database cloudtj
–hcatalog-table dws_image_dealvideo
附加:使用了上面这个参数后可能又会报一个错:java.lang.NoClassDefFoundError: org/apache/hive/hcatalog/mapreduce/HCatOutputFormat
解决:vim /etc/profile
添加export HCAT_HOME=/opt/cloudera/parcels/CDH/lib/hive-hcatalog
然后source /etc/profile