语音信号处理第二章
语音信号处理第三章
语音信号处理第四章
语音信号处理第五章
语音信号处理第七章
语音信号处理第九章
语音信号处理第十章
语音信号处理第十二章
文章目录
说话人识别系统设计
系统框图
说话人识别系统框图
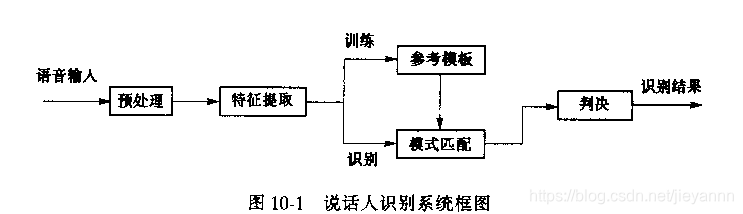
说话人识别是一个二值问题,只需判定是否为申请者所讲。
预处理:
端点检测、预加重、加窗、分帧
特征提取:
语音短时能量
基音周期、语音短时谱、共振峰频率及其带宽
倒谱、MFCC
线性预测系数LPC、LPC倒谱
特征参量评价方法:
F=不同说话人特征参数均值的方差÷同一说话人特征参数方差的均值
F越大,表示特征参数越有效。
系统建立
建立和应用说话人识别系统分为两个阶段:
(1)训练阶段
(2)识别阶段
博主ps:这个跟孤立词识别系统的两个阶段可以说是一模一样了
模式匹配方法
(1)概率统计
(2)基于最近邻原则的DTW:将识别模板和参考模板进行时间对比,按照某种距离测度得出两模板间的相似程度
(3)矢量量化VQ:以量化产生的失真度作为判决标准。
(4)HMM:对于与文本无关的说话人识别一般采用各态历经型HMM,对于与文本有关的说话人识别一般采用从左到右HMM。HMM不需要时间规整。
判别方法
对于要求快速处理的说话人识别系统,可以采用多门限判决和预分类技术来达到加快系统响应时间而又不降低确认率的效果。
门限设定由误拒绝率和误接收率来决定,一般选择误拒绝率和误接收率的相等点附近。
说话人识别系统的评价
具体的说话人确认系统
基于DTW
识别特征:BPFG
匹配方法:DTW
特点:
(1)在结构上基本沿用语音识别的系统
(2)利用过程中的数据来修正原模板(正确确认时,使用此时的输入特征对原模板进行加权修改)

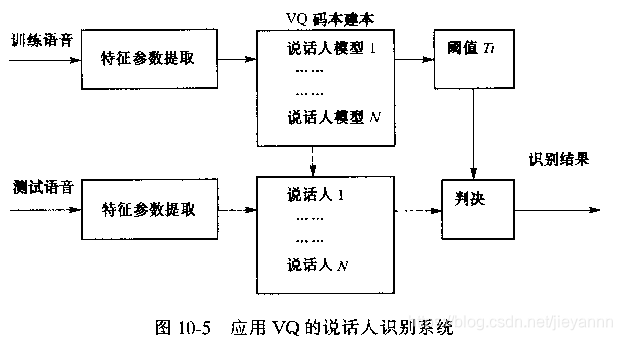
基于VQ
匹配方法:HMM+VQ
失真测度:欧氏距离

基于HMM
步骤:
训练:特征提取——建立HMM模型
识别:端点检测——特征提取——前后向算法计算概率——与阈值进行比较判断
与文本有关
类型:从左到右型HMM
特点:所需训练数据少,提取的特征较稳定
与文本无关
类型:各态历经型HMM。一般使用状态数为5,各状态采用混合高斯密度分布,混合分布数一般取64个分布
特点:识别效果取决于状态数和状态的混合分布数之乘积
指定文本型
步骤:
训练:利用多数说话人的训练数据训练得到的模型作为初始模型——由各说话人的训练数据对初始模型进行自适应训练,得到各说话人的模型
少量训练数据时,HMM训练使用的方法
由于训练数据少,为了得到高精度的模型,有两类训练方法可以使用:
方法一:利用说话人的所有发音数据建立一个和基元类别无关的说话人HMM,然后以此为初始模型,根据各说话人的训练语音文本内容,利用连接学习法,仅对各高斯分布的权值进行再推定,而均值和方差不变。
方法二:利用非特定人基元HMM和各说话人HMM进行组合。
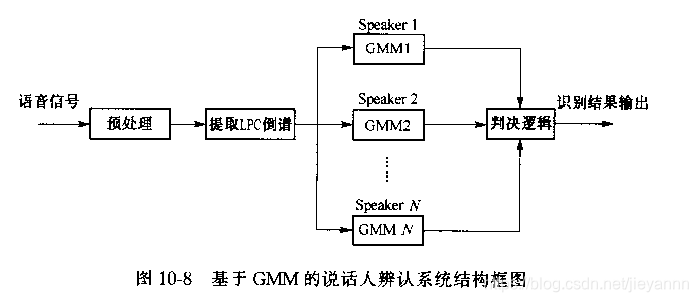
基于GMM
混合高斯分布模型GMM是只有一个状态的模型,状态里具有多个高斯分布函数。