一个程序从用户输入到程序输出结果,中间经过了十分复杂的过程,正式因为这样,一些厂商为了方便用户,将所有的步骤都集成到一个IDE(集成开发环境),将中间的环节都隐藏了,所以,你任务你写完程序,点击运行,马上输出有结果了,但是,对于一个程序员,这些环节还是要清楚的。

#include <stdio.h>
main()
{
printf("hello, world\n");
}
主要的流程有:
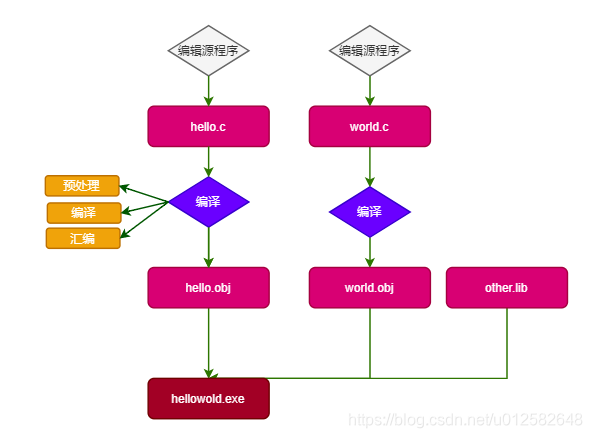
当然,上述的hello.c和world.c是为了说明当有多个源文件的时候生成的过程,实际上述只有一个文件,最后生成可执行exe文件,注意,在windows下,源文件编译后的以 obj结尾的,连接库以lib结尾,在linux下编译后的源文件通常以o结尾,静态链接库以a结尾,动态库以so结尾
编辑
就是程序员在文本编辑器中写入的源代码,这是用户能识别的文件,我们经常听到某某软件开源了,某某企业源代码泄露了,说的就是这个,用户可以用自己熟悉的编辑器编辑,古老的编辑器有emacs,这个可谓是上古神器,已经不仅仅是一个编辑器了,vim是vi的加强版,windows下打开一个记事本就可以写了,下面是vim的编辑
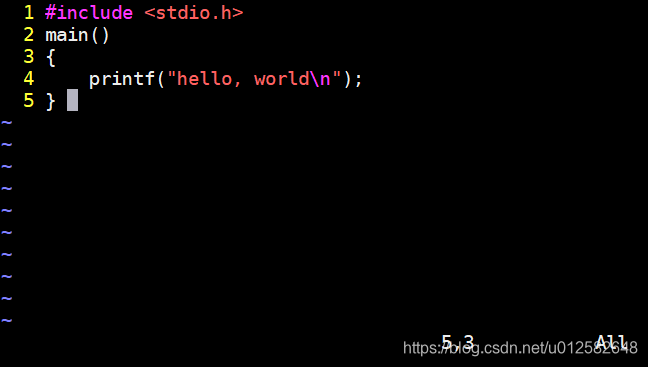
更多vim的使用,后面的文章会单独写到
编译
编译是一个复杂的过程,主要有
- 预处理
- 编译
- 汇编
预处理:是将每个源文件中的头文件和宏预先处理,将对应的文件添加到该文件中,linux下执行预处理过程
gcc -E hello.c -o hello.i
生成hello.i,这是一个可读文件,发现生成了很多的代码,源文件中的hello,world还是在hello.i中
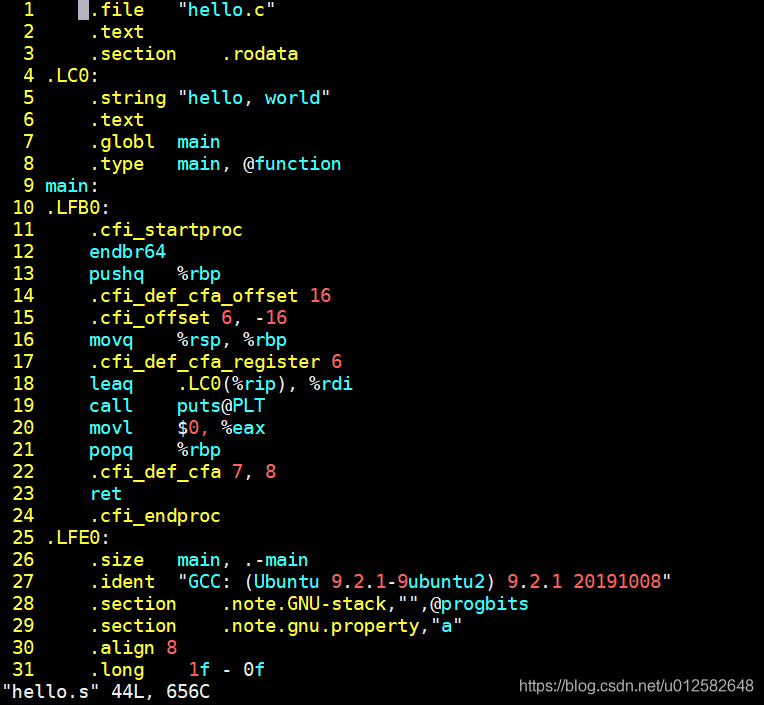
编译 :编译器将hello.i翻译汇编程序储存在文件hello.s中,其中的main作为一个函数给出了机器语言的输出指令
gcc -S hello.i -o hello.s
生成的.s文件是汇编代码:
汇编:汇编器将hello.s中的汇编语言翻译成计算机可以识别的机器语言存为hello.o二进制文件
gcc -c hello.s -o hello.o
hello.o文件是不可读的
链接
静态库在编译的时候就已经编译进来了,此时直接将目标文件生成可执行文件
gcc hello.o -o hello
最后执行hello文件
#./hello
hello, world
这样就输出了,当然,这些过程还可以在详细一下的,要想详细了解编译过程,可以看编译原理这本书,
本书全面、深入地探讨了编译器设计方面的重要主题,包括词法分析、语法分析、语法制导定义和语法制导翻译、运行时刻环境、目标代码生成、代码优化技术、并行性检测以及过程间分析技术
最后,还是回到原点,一般人可以不会每次都详细整个过程生成中间文件,你可以直接用
gcc -c hello.c -o hello
生成可执行文件。
任何大工程项目都是这样一步步生成的,当然不会每次用gcc来一步步生成,可以用makefile来自动化管理编译过程,后面文章继续探讨。