目前的OpenCV3分为稳定的核心功能库和contrib扩展库(包括特征点检测等功能)两个部分,官网下载的编译好的OpenCV仅包括核心功能,因此如果要使用扩展库必须使用Cmake自己进行编译。
OpenCV中有GPU模块,可以使用NVIDIA显卡来加速计算,但是直接用官网下载的编译好的OpenCV3调用GPU命令会发生No CUDA support的错误,因此如果想要在OpenCV中使用GPU加速必须使用Cmake自己进行编译。
总结来说,如果你想使用完整的OpenCV功能、拥有NVIDIA显卡并且想在OpenCV中进行GPU加速,下面的一系列工作将助你一臂之力。
step1 运行环境和前期准备
一、基础环境
1、Windows 10 64位
2、Visual Studio 2015 Professional
https://visualstudio.microsoft.com/zh-hans/downloads/
建议使用VS2015及以上版本 (VS2015对应vc14,VS2017对应vc15)
3、Cmake 3.13.0
https://cmake.org/download/
可以在上述网站中根据自己的需要选择版本进行下载
我下载的是比较新的版本cmake-3.13.0-rc1-win64-x64.msi
Cmake的安装路径可以不放在C盘,但是要建一个文件夹专门用来放它,否则编译过程中会出现这种奇怪的错误:CMake Error: Could not find CMAKE_ROOT !!!
4、OpenCV 3.4.3
https://opencv.org/releases.html
可以在上述网站中根据自己的需要选择版本进行下载
5、OpenCV Contrib 3.4.3
https://github.com/opencv/opencv_contrib/releases
选择与自己OpenCV版本相同的Contrib库,下载ZIP格式即可
4和5最好放在同一个文件夹下,方便管理。
二、GPU环境
1、查看自己电脑配置的显卡是否为NVIDIA显卡,是否支持CUDA:
https://developer.nvidia.com/cuda-gpus
我的笔记本上配置的显卡型号是GeForce GTX 1050 Ti(4G)。
2、下载显卡驱动并安装:
https://www.nvidia.cn/Download/index.aspx?lang=cn
此步骤可以省略,安装CUDA时会自动安装显卡驱动程序

3、下载CUDA:
https://developer.nvidia.com/cuda-80-ga2-download-archive 8.0版本
https://developer.nvidia.com/cuda-90-download-archive 9.0版本
CUDA是NVIDIA推出的通用并行计算架构,该架构能够解决复杂的计算问题。
VS与CUDA版本之间有兼容问题,VS2015最好下载CUDA8或者CUDA9系列的版本,VS2017目前只支持CUDA10。
4、下载cuDNN:
https://developer.nvidia.com/cudnn
cuDNN的全称为NVIDIA CUDA® Deep Neural Network library,是NVIDIA专门针对深度神经网络(Deep Neural Networks)中的基础操作而设计的基于GPU的加速库。
需要注册一个NVIDIA官网的账号才能下载。
此步骤非必须,如果你用不到深度学习可以不下载。
三、安装过程
具体安装过程可参考下面两篇文章:
https://blog.csdn.net/qq_30623591/article/details/82084113
https://blog.csdn.net/u012239518/article/details/81053548
必须按以下顺序安装:
1、安装VS2015
已经安装好的自动忽略,有需要的可以去我的百度网盘上下载:
链接:https://pan.baidu.com/s/1fD9s4A40aUrGX_hLQI2WvA 密码:grdg
2、安装CUDA
选择精简版安装,并且不要修改安装路径,如果安装失败,把原来的驱动卸载并且将C:\Program Files路径下的NVIDIA Corporation文件夹删除再重试安装。
安装完成后,在cmd中输入以下命令验证CUDA是否安装成功:
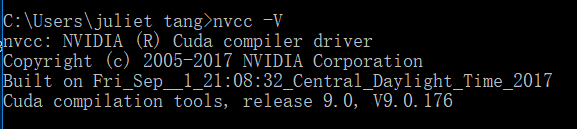
3、安装cuDNN
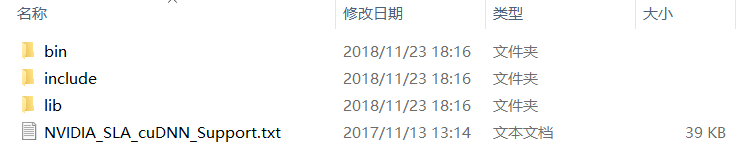
将下载好的压缩包解压后得到的三个文件夹如下,将这三个文件夹复制到C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.0路径下覆盖原有文件即可。
step2 编译OpenCV源码(Contrib扩展模块和GPU模块)
1、打开Cmake,设置编译源码目录和编译输出目录,点击Configure:

2、选择自己的VS版本点击Finish:


如果你选择的是OpenCV3.3.0+CUDA9.0,很有可能在第一步就出现一大堆问题,解决方案可参考下文,测试过有效:
https://blog.csdn.net/u014613745/article/details/78310916#reply
3、第一次Configure done之后,
(1)找到列表中红色部分的“OPENCV_EXTRA_MODULES_PATH”,设置为opencv_contrib源码包中的modules目录,我的目录是“D:\OpenCV343\opencv\tools\opencv_contrib-3.4.3\modules”。
(2)找到列表中红色部分的“WITH_CUDA”,如果没有打勾则打勾。
(3)找到列表中红色部分的“BUILD_TEST”、“BUILD_PERF_TEST”和“BUILD_EXAMPLES”,如果打勾则把勾去掉,目的是为了缩短最后生成解决方案的时间。
设置完上述三项后再次点击Configure。

4、第二次Configure done之后,
找到列表中红色部分的“CUDA_GENERATION”,选择自己显卡对应的架构类型,如果不知道的话百度上搜索一下即可。
设置完后再次点击Configure。

5、Configure done并且列表中没有任何红色后,可以点击Generate,很快就会Generate done,表示生成成功,接着就可以点击Open Project使用VS2015打开解决方案了。

6、打开解决方案后一定要等待左下角显示的项全部加载完毕才可以继续操作,千万别着急。
找到“CmakeTargets”下的“ALL_BUILD”,右键->“生成”,然后开始漫长的等待……

7、经过近一个小时的等待(前面已经讲了如何缩短时间,如果不缩短的话正常都要两小时以上),终于全部生成成功!现在就差最后一步了。
还是找到“CmakeTargets”下的“INSTALL”,右键->"仅用于项目“->“仅生成INSTALL”。

如果第6步中有个别几个项目生成失败,不必担心,可以到E:\Opencv343\tools\build_withgpu\modules路径下找到生成失败的模块,打开对应的.sln解决方案,重复6、7两步的操作就可以弥补回来。如果第6步中失败的项目太多建议重新开始,因为第6步中失败太多会直接导致第7步失败。
8、全部生成成功后会发现,在编译输出目录下多了一个“install”目录,这个就是我们需要的。
此时需要将D:\OpenCV343\tools\build_cuda\install\x64\vc14\bin添加到环境变量并重启计算机,否则在后面的测试过程中将抛出异常。

打开这个"install"文件夹之后你会发现它和原始OpenCV文件夹很像。只要按照之前的配置方法,新建解决方案后在属性管理器中把包含目录、库目录和附加依赖项配置好就可以使用包含Contrib扩展模块的GPU版OpenCV了。

包含目录:
D:\OpenCV343\tools\build_cuda\install\include
D:\OpenCV343\tools\build_cuda\install\include\opencv
D:\OpenCV343\tools\build_cuda\install\include\opencv2
库目录:
D:\OpenCV343\tools\build_cuda\install\x64\vc14\lib
附加依赖项:
opencv_aruco343d.lib
opencv_bgsegm343d.lib
opencv_bioinspired343d.lib
opencv_calib3d343d.lib
opencv_ccalib343d.lib
opencv_core343d.lib
opencv_cudaarithm343d.lib
opencv_cudabgsegm343d.lib
opencv_cudacodec343d.lib
opencv_cudafeatures2d343d.lib
opencv_cudafilters343d.lib
opencv_cudaimgproc343d.lib
opencv_cudalegacy343d.lib
opencv_cudaobjdetect343d.lib
opencv_cudaoptflow343d.lib
opencv_cudastereo343d.lib
opencv_cudawarping343d.lib
opencv_cudev343d.lib
opencv_datasets343d.lib
opencv_dnn343d.lib
opencv_dpm343d.lib
opencv_face343d.lib
opencv_features2d343d.lib
opencv_flann343d.lib
opencv_fuzzy343d.lib
opencv_highgui343d.lib
opencv_img_hash343d.lib
opencv_imgcodecs343d.lib
opencv_imgproc343d.lib
opencv_line_descriptor343d.lib
opencv_ml343d.lib
opencv_objdetect343d.lib
opencv_optflow343d.lib
opencv_phase_unwrapping343d.lib
opencv_photo343d.lib
opencv_plot343d.lib
opencv_reg343d.lib
opencv_rgbd343d.lib
opencv_saliency343d.lib
opencv_shape343d.lib
opencv_stereo343d.lib
opencv_stitching343d.lib
opencv_structured_light343d.lib
opencv_superres343d.lib
opencv_surface_matching343d.lib
opencv_text343d.lib
opencv_tracking343d.lib
opencv_video343d.lib
opencv_videoio343d.lib
opencv_videostab343d.lib
opencv_xfeatures2d343d.lib
opencv_ximgproc343d.lib
opencv_xobjdetect343d.lib
opencv_xphoto343d.lib
step3 测试
(1)测试GPU模块
在VS2015中新建解决方案,在属性管理器中完成包含目录、库目录和附加依赖项的配置,在源文件中添加gpu_test.cpp,输入以下代码进行验证。
#include <opencv2\opencv.hpp>
#include <iostream>
using namespace std;
using namespace cv;
using namespace cv::cuda;
int main()
{
/*-------------------------以下四种验证方式任意选取一种即可-------------------------*/
//获取显卡简单信息
cuda::printShortCudaDeviceInfo(cuda::getDevice()); //有显卡信息表示GPU模块配置成功
//获取显卡详细信息
cuda::printCudaDeviceInfo(cuda::getDevice()); //有显卡信息表示GPU模块配置成功
//获取显卡设备数量
int Device_Num = cuda::getCudaEnabledDeviceCount();
cout << Device_Num << endl; //返回值大于0表示GPU模块配置成功
//获取显卡设备状态
cuda::DeviceInfo Device_State;
bool Device_OK = Device_State.isCompatible();
cout << "Device_State: " << Device_OK << endl; //返回值大于0表示GPU模块配置成功
system("pause");
return 0;
}
(2)测试扩展模块
如果第1步中的GPU模块运行正常,现在就可以进行第2步了,测试GPU版本的扩展模块是否能够正常运行。
仍然在刚才的解决方案中,在源文件中添加surf_test.cpp,输入以下代码进行验证。测试发现使用OpenCV3.3.0版本能够成功运行,使用OpenCV3.4.0以后的版本运行会出错,应该是模块中有调整导致部分功能缺失的原因。
测试代码来自以下文章:
https://blog.csdn.net/qq_15947787/article/details/78534272
#include <iostream>
#include "opencv2/opencv_modules.hpp"
#include "opencv2/core.hpp"
#include "opencv2/features2d.hpp"
#include "opencv2/highgui.hpp"
#include "opencv2/cudafeatures2d.hpp"
#include "opencv2/xfeatures2d/cuda.hpp"
using namespace std;
using namespace cv;
using namespace cv::cuda;
int main()
{
cuda::printShortCudaDeviceInfo(cuda::getDevice());
GpuMat img1, img2;
img1.upload(imread("1.jpg", IMREAD_GRAYSCALE));
img2.upload(imread("2.jpg", IMREAD_GRAYSCALE));
SURF_CUDA surf;
// detecting keypoints & computing descriptors
GpuMat keypoints1GPU, keypoints2GPU;
GpuMat descriptors1GPU, descriptors2GPU;
surf(img1, GpuMat(), keypoints1GPU, descriptors1GPU);
surf(img2, GpuMat(), keypoints2GPU, descriptors2GPU);
cout << "FOUND " << keypoints1GPU.cols << " keypoints on first image" << endl;
cout << "FOUND " << keypoints2GPU.cols << " keypoints on second image" << endl;
// matching descriptors
Ptr<cuda::DescriptorMatcher> matcher = cuda::DescriptorMatcher::createBFMatcher(surf.defaultNorm());
vector<DMatch> matches;
matcher->match(descriptors1GPU, descriptors2GPU, matches);
// downloading results
vector<KeyPoint> keypoints1, keypoints2;
vector<float> descriptors1, descriptors2;
surf.downloadKeypoints(keypoints1GPU, keypoints1);
surf.downloadKeypoints(keypoints2GPU, keypoints2);
surf.downloadDescriptors(descriptors1GPU, descriptors1);
surf.downloadDescriptors(descriptors2GPU, descriptors2);
// drawing the results
Mat img_matches;
drawMatches(Mat(img1), keypoints1, Mat(img2), keypoints2, matches, img_matches);
namedWindow("matches", 0);
imshow("matches", img_matches);
waitKey(0);
return 0;
}
运行效果:
OpenCV3.3.0运行成功,可以看到成功找到匹配的特征点,诊断工具中CPU的利用率很低,并且在任务管理器中可以查看GPU的利用率。

OpenCV3.4.0以后可以使用下面这个代码进行测试。
在源文件中添加orb_test.cpp,输入以下代码进行验证。
测试代码来自以下文章:
https://blog.csdn.net/m0_37857300/article/details/79039214
#include <iostream>
#include <signal.h>
#include <vector>
#include <opencv2/opencv.hpp>
using namespace cv;
using namespace std;
bool stop = false;
void sigIntHandler(int signal)
{
stop = true;
cout<<"Honestly, you are out!"<<endl;
}
int main()
{
Mat img_1 = imread("model.jpg");
Mat img_2 = imread("ORB_test.jpg");
if (!img_1.data || !img_2.data)
{
cout << "error reading images " << endl;
return -1;
}
int times = 0;
double startime = cv::getTickCount();
signal(SIGINT, sigIntHandler);
int64 start, end;
double time;
vector<Point2f> recognized;
vector<Point2f> scene;
for(times = 0;!stop; times++)
{
start = getTickCount();
recognized.resize(500);
scene.resize(500);
Mat d_srcL, d_srcR;
Mat img_matches, des_L, des_R;
cvtColor(img_1, d_srcL, COLOR_BGR2GRAY);
cvtColor(img_2, d_srcR, COLOR_BGR2GRAY);
Ptr<ORB> d_orb = ORB::create(500,1.2f,6,31,0,2);
Mat d_descriptorsL, d_descriptorsR, d_descriptorsL_32F, d_descriptorsR_32F;
vector<KeyPoint> keyPoints_1, keyPoints_2;
Ptr<DescriptorMatcher> d_matcher = DescriptorMatcher::create(NORM_L2);
std::vector<DMatch> matches;
std::vector<DMatch> good_matches;
d_orb -> detectAndCompute(d_srcL, Mat(), keyPoints_1, d_descriptorsL);
d_orb -> detectAndCompute(d_srcR, Mat(), keyPoints_2, d_descriptorsR);
d_matcher -> match(d_descriptorsL, d_descriptorsR, matches);
int sz = matches.size();
double max_dist = 0; double min_dist = 100;
for (int i = 0; i < sz; i++)
{
double dist = matches[i].distance;
if (dist < min_dist) min_dist = dist;
if (dist > max_dist) max_dist = dist;
}
cout << "\n-- Max dist : " << max_dist << endl;
cout << "\n-- Min dist : " << min_dist << endl;
for (int i = 0; i < sz; i++)
{
if (matches[i].distance < 0.6*max_dist)
{
good_matches.push_back(matches[i]);
}
}
for (size_t i = 0; i < good_matches.size(); ++i)
{
scene.push_back(keyPoints_2[ good_matches[i].trainIdx ].pt);
}
for(unsigned int j = 0; j < scene.size(); j++)
cv::circle(img_2, scene[j], 2, cv::Scalar(0, 255, 0), 2);
imshow("img_2", img_2);
waitKey(1);
end = getTickCount();
time = (double)(end - start) * 1000 / getTickFrequency();
cout << "Total time : " << time << " ms"<<endl;
if (times == 1000)
{
double maxvalue = (cv::getTickCount() - startime)/cv::getTickFrequency();
cout <<"zhenshu " << times/maxvalue <<" zhen"<<endl;
}
cout <<"The number of frame is : " <<times<<endl;
}
return 0;
}
运行效果:
OpenCV3.4.3运行成功,可以看到成功找到特征点,诊断工具中CPU的利用率不算特别高。

上面的例子都不算是特别复杂的处理过程,仅供测试使用。
总结
GPU加速用在非常简单的处理过程中基本上没有任何优势,有时候反而比CPU处理更慢,因为CPU和GPU之间传输数据也是非常耗时的过程。建议在计算量非常大的时候使用GPU加速。
Juliet 于 2018.11