UDF
概述
- UDF在我们的Sql开发中,是一个必不可少的帮手,通过Sql+UDF能够解决我们90%的问题
- Flink目前提供了大量的内置UDF供我们使用,详细可以参考官方文档
- 不过有些时候,内置的UDF并不满足我们的需求,那就需要自定义UDF
- 下面我们就来看看如何在Zeppelin中使用自定义UDF
使用
- 在Flink中,使用代码注册UDF有两种方式
tEnv.registerFunction("test",new TestScalarFunc());tEnv.sqlUpdate("CREATE FUNCTION IF NOT EXISTS test AS 'udf.TestScalarFunc'");
- 而在Zeppelin中,也有多种方式
- 通过编写Scala代码,然后通过上面两种方式注入
flink.execution.jars加载指定Jar加载进Flink集群中,之后通过上面两种方式注册UDF。使用起来很不爽,首先你得知道有哪些UDF,其次你得挨个注册,而且你还得知道每个UDF的全类名,很麻烦。那么有没有更好的方式呢?flink.udf.jars自动将Jar包中所有UDF注册,相当方便,下面演示一下- 先加一下配置参数
%flink.conf flink.udf.jars /home/data/flink/lib_me/flink-udf-1.0-SNAPSHOT.jar - 输出一下,看看有哪些UDF
%flink.ssql(type=update) show functions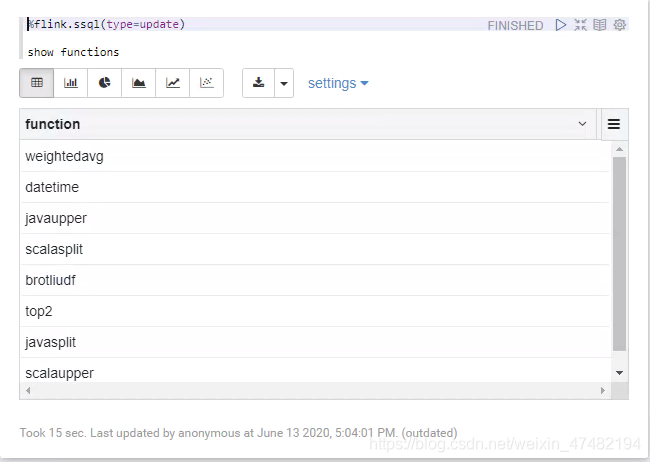
- 很完美,将我们所有的UDF都注册了进来,我们再来验证一下正确性
%flink.ssql(type=update) -- 连from哪个表都没必要写,Zeppelin实在太方便了 select javaupper('a')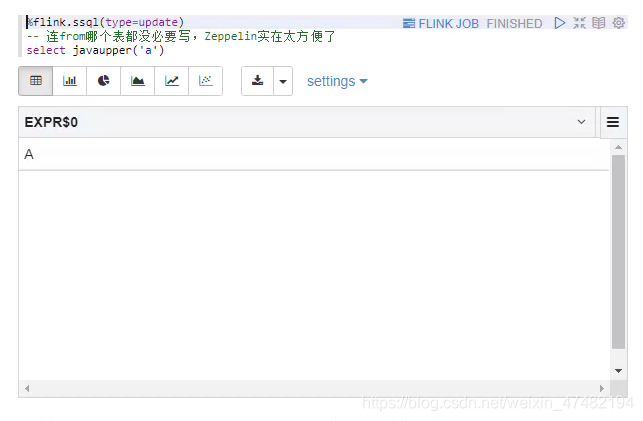
- 和我们预期的一样,将字符
a转换成了A
- 先加一下配置参数
- 那么,UDF的使用介绍就到这里
Redis维表
概述
- 之前在写Flink Sql系列的时候,给大家演示了如何写一个支持DDL方式的Redis维表
- 不过只在idea中使用过,并没有在正式环境中跑过,所以,今天给大家演示一下如何在Zeppelin中使用Redis维表
- 在开始之前,先说一下之前遇到的一个问题。我把我之前的包丢在服务器跑时,总是抛出异常
org.apache.flink.table.api.NoMatchingTableFactoryException: Could not find a suitable table factory for 'org.apache.flink.table.factories.TableSourceFactory'
出现这个异常一般有三种情况,少包或者包冲突或者DDL有问题;而我已经把我Connector的依赖打入了Jar包,并且没有指定<scope>provided</scope>;我也把冲突的包给排除了;我idea是正常能跑的,所以也排除DDL写的有问题。这就很奇怪了,后来想到Flink通过SPI机制来发现具体的实现类。于是我把Jar解压,找到
org.apache.flink.table.factories.TableFactory这个文件。果不其然,Kafka的工厂类不在里面,后来将所有涉及到的工厂类都丢到这个文件里面,就能够正常运行了。不过这种方式太不优雅,于是又找到了一个解决方法,传送门
我已经将修改之后的pom文件push了,大家可以拉一下最新的代码 - 另外,Flink连接Redis部分已经抽出来了,准备搞个新的工程,之后将会支持更多的功能,比如维表关联
HASH类型数据,又比如支持将数据插入Redis中,这些都将通过DDL语句来建表,然后用纯Sql的方式进行关联或者写入 - 好了,下面开始正式的介绍如何在Zeppelin中使用,我们自定义的Redis维表
使用
- 先通过
flink.execution.jars将我们的Jar引入%flink.conf flink.udf.jars /home/data/flink/lib_me/flink-udf-1.0-SNAPSHOT.jar flink.execution.jars /home/data/flink/lib_me/flink-redis-1.0-SNAPSHOT.jar flink.execution.packages org.apache.flink:flink-connector-kafka_2.11:1.10.0,org.apache.flink:flink-connector-kafka-base_2.11:1.10.0,org.apache.flink:flink-json:1.10.0,org.apache.flink:flink-jdbc_2.11:1.10.0 - 再建一下我们的数据源表和数据维表
%flink.ssql -- Kafka Source DDL DROP TABLE IF EXISTS t3; CREATE TABLE t3( user_id BIGINT, item_id BIGINT, category_id BIGINT, behavior STRING, ts BIGINT, r_t AS TO_TIMESTAMP(FROM_UNIXTIME(ts,'yyyy-MM-dd HH:mm:ss'),'yyyy-MM-dd HH:mm:ss'), WATERMARK FOR r_t AS r_t - INTERVAL '5' SECOND, p AS proctime() )WITH ( 'update-mode' = 'append', 'connector.type' = 'kafka', 'connector.version' = 'universal', 'connector.topic' = 'zeppelin_01_test', 'connector.properties.zookeeper.connect' = '127.0.0.1:2181', 'connector.properties.bootstrap.servers' = '127.0.0.1:9092', 'connector.properties.group.id' = 'zeppelin_01_test', 'connector.startup-mode' = 'earliest-offset', 'format.type'='json' )%flink.ssql -- Redis Dim DDl DROP TABLE IF EXISTS redis_dim; CREATE TABLE redis_dim ( first String, name String ) WITH ( 'connector.type' = 'redis', 'connector.ip' = '127.0.0.1', 'connector.port' = '6379', 'connector.lookup.cache.max-rows' = '10', 'connector.lookup.cache.ttl' = '10000000', 'connector.version' = '2.6' ) - 再执行我们的Sql,并且用UDF将查出来的维表值转成大写
%flink.ssql(type=update) select a.*,javaupper(b.name) from t3 a left join redis_dim FOR SYSTEM_TIME AS OF a.p AS b on a.behavior = b.first where b.name is not null and b.name <> '' - 看一下结果
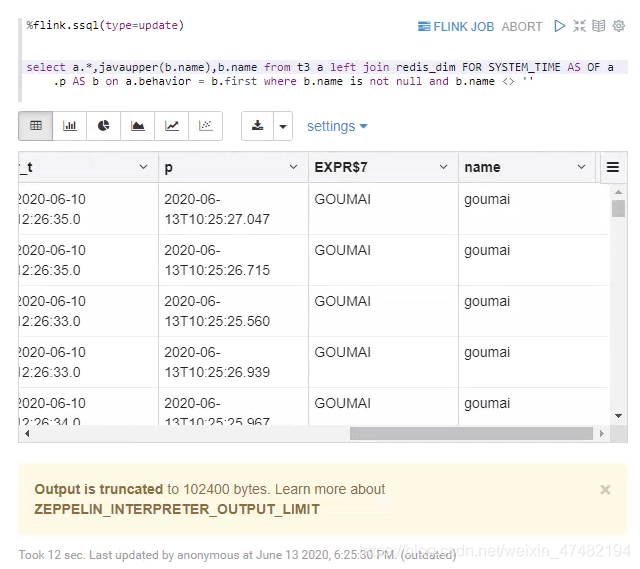
- 可以看出,我们成功关联上了Redis维表,并且成功用我们自己注册UDF,将值转为了大写,很成功!
- 那么,Redis维表就说到这里
写在最后
-
今天这一章和之前的一张可以说把Zeppelin三种引入Jar的方式都介绍了一下,下面给大家总结一下
- 通过Zeppelin管理
flink.execution.packages适合放我们在仓库中有的Jar包,会自动把Jar的依赖也下载下来,如flink-connect-kafkaflink.execution.jars适合放我们尚未部署到仓库中的包,比如一些Flink提供的example包flink.udf.jars适合放我们的UDF,Zeppelin会自动注册
- 放在
$FLINK_HOME/lib中,不推荐,会影响整个Flink环境,很有可能因为你的Jar包导致Flink无法使用
- 通过Zeppelin管理
-
在测试Redis Dim的时候,发现个bug,每次任务关闭的时候,远端的Redis都会自动shutdown。后来观察redis的日志发现这么一句话
2005:M 13 Jun 14:19:39.459 # User requested shutdown...,看到这里明白了,应该是客户端代码有个地方错误的关闭了服务端。于是翻看自己的代码,发现asyncClient.shutdown(true);这个代码的注释写着Synchronously save the dataset to disk and then shut down the server.。后来把这行去掉就一切正常了,之前之所以没发现这个问题,是因为在idea中执行的代码,每次停止任务的时候,根本走不到关闭连接的语句。还是因为自己偷懒没有写单元测试和去集群测试,牢记教训!
最后,向大家宣传一下Flink on Zeppelin 的钉钉群,大家有问题可以在里面讨论,简锋大佬也在里面,有问题直接提问就好
