Persistent Queue 为Logstash管道增加了基于磁盘的弹性。 在 Logstash 5.4中,它已正式升级为通用可用性,以替代内存队列的生产就绪型替代方案。 本博客文章旨在说明其性能和风险特征与默认的内存队列之间的区别。 文档中提供了有关 PQ 的其他信息。
设计
PQ 是什么?
PQ,也即永久队列。默认情况下,Logstash 在输入和 filter + output 管道阶段之间使用内存中排队。 这使它可以吸收负载中的小峰值,而无需保持将事件推入 Logstash 的连接,但是缓冲区仅限于内存容量。 如果 Logstash 发生故障,则正在处理的运行中和内存中数据将丢失。
为了提供不限于内存容量的缓冲区,并防止异常终止期间的数据丢失,Logstash 引入了持久队列功能。 它将输入数据作为自适应缓冲区存储在磁盘上,并在处理完成后将流水线确认送回到持久队列。 重新启动 Logstash 时,将重播任何未确认的数据(未完全处理和输出)。
总而言之,启用持久队列的好处如下:
- 无需大量的外部缓冲机制(例如Redis或Apache Kafka)即可吸收突发事件。
- 提供一次至少一次传递保证,以防止在正常关闭以及Logstash异常终止时丢失消息。 如果在发生事件时重新启动Logstash,则Logstash将尝试传递存储在持久队列中的消息,直到传递至少成功一次。
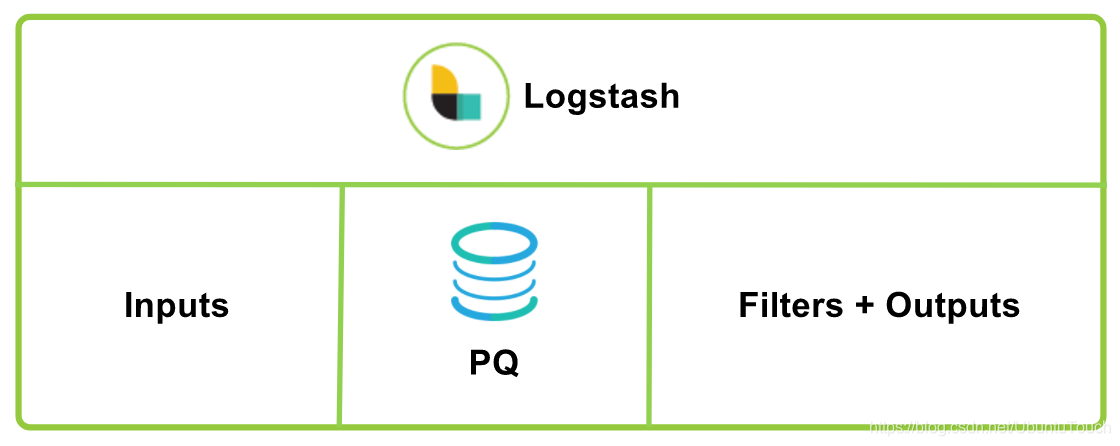
初步设计目标
至少一次交付:PQ设计的主要目标是在出现异常故障时避免数据丢失,并旨在提供至少一次交付的保证。至少一次交付意味着发生故障时,重新启动 Logstash 时将重播所有未确认的数据。根据故障情况,“至少一次” 还意味着可以重播已处理但未确认的数据,并导致重复处理。这是至少一次的权衡;以无故障的情况下避免数据丢失为代价,可能会有重复数据的代价。有关处理重复项的更多信息,请参见 Suyog Rao 的博客文章。
Spooling:PQ 还可在磁盘上增大大小,并在不对输入施加反压的情况下帮助处理数据摄取峰值或输出减慢。在这两种情况下,输入或摄取端的处理速度都比 Logstash 的过滤和输出端更快。使用 PQ,传入的数据将在磁盘上本地缓冲,直到过滤和输出阶段能够赶上。对于使用外部排队层处理吞吐量峰值和减轻背压的现有用户,PQ 现在能够自然满足这些要求。因此,用户可以选择删除此外部排队层,以简化总体摄取架构。下面是使用 Logstash 和 PQ 的日志记录体系结构的示例;有关其他部署和扩展指南,请查阅文档。

弹性和耐久性
失败场景
有3种类型的故障会影响Logstash:
- 应用程序/进程级别崩溃/中断的关机。这是 PQ 帮助解决潜在数据丢失的最常见原因。当 Logstash 异常崩溃或在进程级别被杀死或通常以防止安全关闭的方式被中断时,会发生这种情况。使用内存队列时,这通常会导致数据丢失。使用 PQ,无论持久性设置如何(请参阅 queue.checkpoint.writes 设置),都不会丢失任何数据,并且在重新启动 Logstash 时将重播任何未确认的数据。
- 操作系统级崩溃:内核崩溃或计算机重新启动。使用 PQ 默认设置,可能会丢失在上一次 fsync 和 OS 级崩溃之间没有安全地写入磁盘(fsync)的数据。可以更改此行为并将 PQ 配置为具有最大持久性,其中每个传入事件都将被强制写入磁盘(fsync)。请参阅 “Durability” 部分和queue.checkpoint.writes设置。
- 存储硬件故障。 PQ 不提供复制来帮助解决存储硬件故障。防止磁盘故障时数据丢失的唯一方法是在云环境中使用 RAID 等外部复制技术或等效的冗余磁盘选件。
耐用性
PQ 使用大小为 queue.page_capacity(默认为250mb)的页面文件来写入输入数据。 最新页面称为首页,是仅以追加方式写入数据的页面。 当首页到达 queue.page_capacity 时,它变成不可变的尾页,并创建一个新的首页以写入新数据。首页的持久性特征是使用 queue.checkpoint.writes 设置控制的。 默认情况下,PQ 将在每 1024 个收到的输入事件时强制将数据写入磁盘,以减少 OS 级崩溃时潜在的数据丢失。 请注意,无论 queue.checkpoint.writes 设置如何,应用程序和进程级别的崩溃或中断的关闭都绝不会导致数据丢失。 如果要防止操作系统级别崩溃的潜在数据丢失,可以使用 queue.checkpoint.writes:1 设置将 PQ 设置为最大持久性,但是请注意,这将导致 IO 性能显着降低。
性能
因为 PQ 将所有事件都写入磁盘,并使用检查点使磁盘上的文件保持更新数据,所以需要注意的是,性能配置文件与内存队列的配置文件完全不同;请注意。一些管道配置的性能影响可以忽略不计,而其他管道配置的影响则微乎其微,因此在启用生产中的 PQ 之前,请务必使用你的特定数据验证折衷方案。
这些基准测试的主要目标是使用默认设置来显示 PQ 对在服务器级高性能硬件上运行的 Logstash 性能的影响,我们认为默认设置对于大多数用户而言应该是合理的默认设置。显然,Logstash 中有许多调整旋钮可以直接影响其性能,因此这些基准测试会根据你的特定配置,设置和运行的硬件而有所不同。
使用自定义脚本来衡量持久队列性能的影响,该脚本每秒轮询并收集 Logstash 统计 API。以下测试是使用典型的 Apache 访问日志处理配置和足够大的示例日志文件在 AWS EC2 c3.4xlarge 实例上的 Logstash 5.4.1 上执行的。总运行时间为5分钟,每次测试的前30秒都被忽略,以解决 JVM 预热的问题。
可以在 Github 上找到统计信息收集脚本,配置和日志文件,因此您可以在硬件以及配置和数据上运行基准测试。
Apache 配置
input {
stdin {
codec => line
}
}
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}"}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
geoip {
source => "clientip"
}
useragent {
source => "agent"
target => "ua"
}
}
output {
stdout { codec => dots }
} 基准测试结果显示,在此配置中使用持久队列时,性能下降约10%。 使用内存队列可以平均每秒产生约10600个事件,而使用持久队列则每秒可以产生约9500个事件。

使用方法
配置
在 Logstash 的安装目录中,有一个叫做 pipelines.yml 的配置文件:
$ pwd
/Users/liuxg/elastic/logstash-7.8.0
liuxg:logstash-7.8.0 liuxg$ ls config/pipelines.yml
config/pipelines.yml我们可以在 pipelines.yml 里做如下的配置:

一旦我们配置好,我们就可以不用接任何的参数直接运行 Logstash:
./bin/logstash如果我们没有上面的这个配置,那么不接参数直接运行 Logstash 就会退出,除非我们启动 “Logstash: 启动监控及集中管理”。
以下的配置项都来自于这个文件的配置。
queue.type:指定 “peristed” 以启用持久队列。默认情况下,禁用持久队列(默认:queue.type:内存)。
path.queue:将存储数据文件的目录路径。默认情况下,文件存储在 path.data/queue 中。
queue.page_capacity:队列页面的最大大小(以字节为单位)。队列数据由称为“pages”的仅附加文件组成。默认大小为 250mb。
queue.max_events:队列中允许的最大事件数。默认值为0(无限制)。
queue.max_bytes:队列的总容量,以字节数为单位。默认值为1024mb(1gb)。确保磁盘驱动器的容量大于您在此处指定的值。
如果同时指定 queue.max_events 和 queue.max_bytes,则 Logstash 使用首先达到的条件。
检查点
还有其他两个与检查点相关的设置。对于后台,每个数据页文件都有一个关联的检查点文件。检查点文件包含有关其关联数据页的元信息。
与不可变且只读的尾页关联的检查点文件将根据确认从该页面完全读取和处理的事件的操作进行更新。
与接收写入的首页相关联的检查点文件将根据写入新事件的动作进行更新。当首页还是正在读取的页面时,其检查点也将根据确认完全读取和处理的事件的操作进行更新。更新首页的检查点通常会强制安全地将数据写入磁盘(fsync)。
queue.checkpoint.acks:在确认许多事件后,Logstash 将更新检查点。默认值为1024,0为无限制
queue.checkpoint.writes:在多次写入队列后,Logstash将更新首页检查点。默认值为1024,0为无限制
更改这两个设置将影响性能。默认值提供了良好的可靠性与性能的折衷。
更改 queue.checkpoint.acks 将增加或减少在异常故障后重新启动时可能重复播放的重复事件的数量。
在操作系统级别崩溃的情况下,更改 queue.checkpoint.writes 将增加或减少丢失事件的潜在数量:内核崩溃或计算机重新启动。请参阅失败方案部分。
停止及启动 Logstash
当 Logstash 运行时,如果收到 SIGINT(例如正在运行的终端中的 Control-C)或 SIGTERM 信号,它将进入正常的关机顺序。 当Logstash 在启用持久队列的情况下正常关闭时,输入将被关闭,只有当前的运行中数据将完成其处理(filter + output阶段)。 所有累积的和未处理的数据将保留在磁盘上的持久队列中,Logstash 将退出。 重新启动 Logstash 时,在正常关闭过程中,不会丢失任何数据,也不会发生任何数据重复。
例如,如果 Logstash 因崩溃而异常终止,或者被 SIGKILL 终止,那么重新启动 Logstash 时,将重播所有持久和未确认的运行中数据。 由于随时可能发生异常终止,因此在 Logstash 重新启动时,将重播并重新处理任何未处理但尚未确认的数据,可能会生成重复数据。
结论
希望你发现持久队列功能有用并开始使用它。 与往常一样,你的反馈对我们非常重要。 您可以在 GitHub 上向我们提供反馈或在我们的论坛上打开讨论线程。
参考: