开始学习之前,先简单接受下分布式系统是什么。
分布式系统是什么
这里我先以百度百科上搜索分布式系统为依据,结合自己的理解,做个简单的概括。 分布式系统(distributedsystem)是建立在网络之上的软件系统。正是因为软件的特性,所以分布式系统具有高度的内聚性和透明性。因此,网络和分布式系统之间的区别更多的在于高层软件(特别是操作系统),而不是硬件。
以上是百度百科的原话。 若要用形象的比喻的话。分布式系统就是支持 多个能独立运行的计算机(或是模块或是子系统)组成。 划重点:
1.多个,即能把要处理的任务,分化成多个小任务。
2.独立运行,即每个小任务相互间是独立性的。
3.组成,这里的组成,可以抽象的理解为,有种叫共享的机器(LAN),连接着每个计算机。
分布式系统的作用及特点
1.先谈钱, 与集中式系统比较,分布式系统可以通过较低廉的价格来实现相似的性能的。
2.可靠性,因为它“独立运行”,当某个机器或出故障了,并不影响其他机器的运行。从概率上说,10台机器,有一台坏了,也就损失10%的性能。还有90%的性能正常运作。
3.可以无限扩展。一个良好的成长性公司,随着他的成长,他的工作量也会大大的增长。用集中式的话,可能就得更换更大的机器去代替。 用分布式的话。可以锁着工作量的增长,去适当增加工作的机器。
4.分布式是给每个计算机独立的运行,同时,也有个中间站(LAN),把他们联在一起。每台计算都有个他们自己的“特长”,当接受到自己不擅长的任务,可以通过中间站分配给对应的机器。
分布系统也有他自身的缺点
1.目前在这个分布式系统的设计及实现上的经验太少。市场上,用分布式系统开发的软件还是较少。需要时间的验证
2.由于网络可能饱和,造成信息的损失,网络过载。
3.由于数据的共享。对保密数据的安全性问题比较难以解决。
该谈谈怎么实现的问题了,此篇文章,我们先来谈谈他的第一步——数据分片
分布式是解决把一个大任务细分为多个小任务。 大任务我们是知道了的。那,问题来了,我们该怎么分,怎么根据每个独立计算机的特点进行分配,这就是我们要解决的数据分片问题。
1.怎么按数据的特征,以及独立计算机的特点进行匹配划分
2.怎么把属于某个数据,转移到适合他的独立计算机上。
3.增加了新的独立计算机,怎么分配数据
4.独立计算机的管理问题,怎么知道哪类数据是在哪个模块。
目前的分片,有三种方式:hash方式,一致性hash(consistent hash),按照数据范围(range based)。 这里我先标明下:用哪种方式进行分片是要根据具体的业务需求进行权衡选择的。
hash方式:
哈希表,特点:简单。由于他的简单,也就不存在上面提的独立计算机管理的问题(为了方便理解,把每个独立计算机储存数据的特征 当做元数据)。按照数据的某一特征来计算哈希值,并将哈希值与系统中的节点建立映射关系,从而将哈希值不同的数据分布到不同的节点上。缺点是每增加新的独立计算机,需要大量的移动数据。
假设先有3个机器,每个机器对应平均分配一个hash值的区域,按id来计算hash值,再进行分配,得到以下情况。这些n0,n1,n2就是元数据
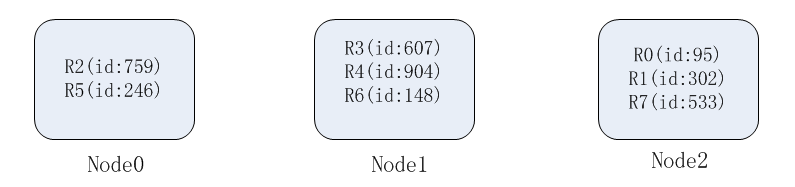
若是再增加一个机器,每个机器对应的一个hash值的区域就发生改变。,原有的id的hash值,可能不在原有的机器中,需要发发生数据转移。
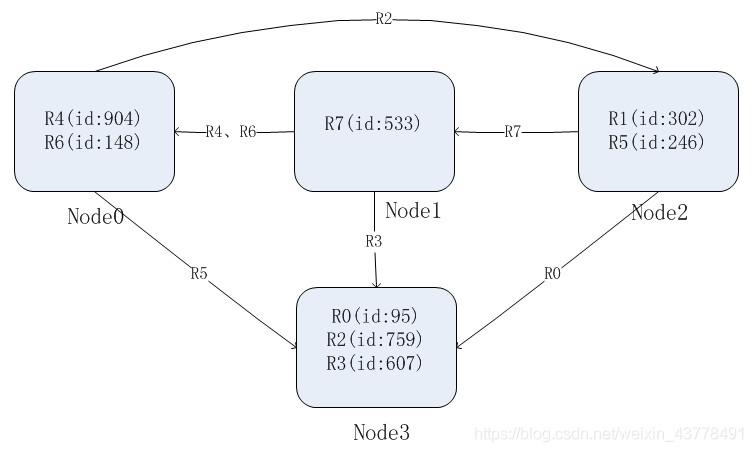
此外,hash方式很难解决数据不均衡问题, 假设这里面是按员工的薪水进行计算hash值,实际人群中,可能处于平均薪水10k 左右的人比较多,高薪水的人比较少这导致某些机器上的数据很大,某些机器上的数据很小。
一致性hash:
一致性hash相当与一个环。所有的数据都在这个环上,每个机器相当于环的一截,所有机器加起来等于一个环。 元数据就每个机器的“范围”以及他们在环上的位置。
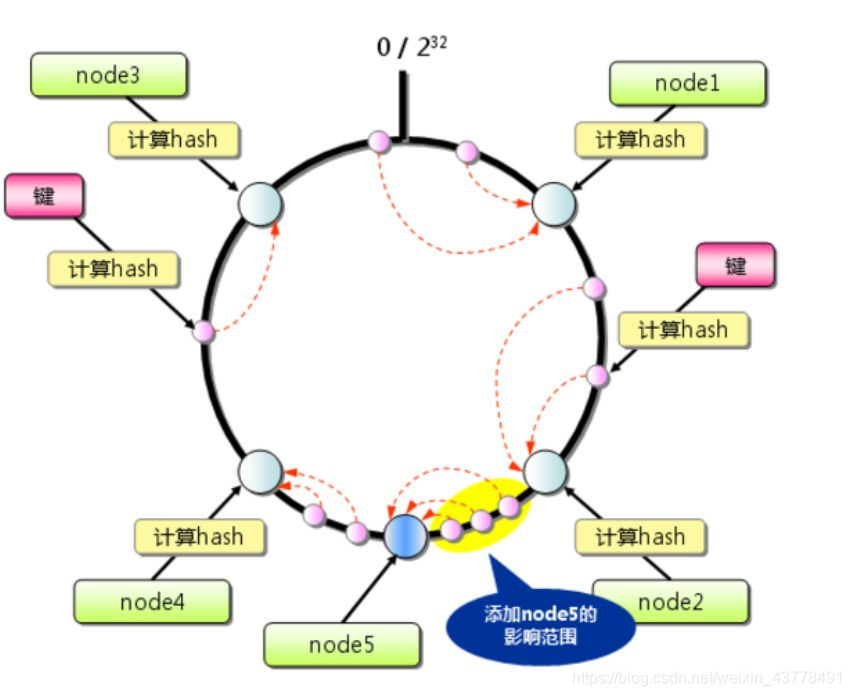
可以发现,一致性hash的同样也比较简单。但是相对于hash来说,一致性hash在增加新的机器后,不需要大量挪动数据。如图:在环上增加个n5的新机器,只是把原来属于n4的3条数据移到n5的机器上。减少了n4的数据压力。
不过,我们可以发现问题,增加了一个n5的机器只减少了n4一台机器的压力,不能减少其他机器的数据压力。 举个例子:假设一个购物网站,在购物节的时段,用户买东西频率增加,负责这一个模块的机器扛不住了,增加一个机器就可以解决这个问题。。。若随着这个网站的发展,他的用户规模增加,不急是买东西的次数增加了,浏览网页的次数也多了,卖家入驻也多了,需要维护的东西也多了,此时,增加一个机器,解决不了这个问题。
此时,就引入了一个叫虚拟结点的概念。(virtual node)。可以理解为每一个节点有了分身的功能,分散在这个环上,所有分身负责的区间和就是这个节点实际负责的区间。 虚拟节点指的就是这些分身。元数据依旧指的是所负责的区间,只不过数据量增大了一些。当增加一个新的机器,在环上会出现多个分身,就能分担多个机器的压力了。
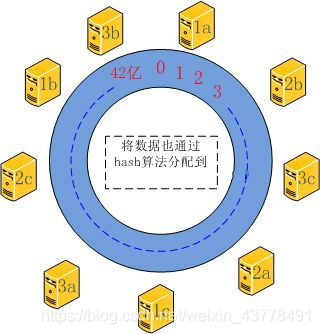
以上图为例。假设 a,b c为实际的节点。 1a,2a,3a对应是a节点在环上的分身,一次类推。c为新增加的机器,增加了C机器,对应在环上会增加1c,2c,3c的节点。
从图上分析:
增加1c节点, 减轻了 2a节点的压力
增加2c节点,减轻了3a节点的压力
增加3c节点,减轻了2b节点的压力
分身节点负责的区间和是实际节点为节点的区间,即 C机器的增加,减少了A,B机器的压力。以此解决了之前的问题。
| 方式 | 映射难度 | 元数组 | 节点增删 |
|---|---|---|---|
| hash | 简单 | 简单,不用修改 | 1.增删时需要迁移大量数据 |
| 一致hash没有虚拟节点 | 简单 | 较简单 | 1.只影响邻近节点的数据2.不能实现所有节点数据迁移 |
| 一致hash有虚拟节点 | 普通 | 较复杂 | 1.增删时数据迁移少2.增加时可分担所有节点的数据 |
| range based | 复杂 | 复杂 | 1.增删时数据迁移少2.增加时可分担所有节点的数据 |
怎么选择特征
可以看到,切片的方法都有个基础,及按某一个特征得出hash值,那么,这个特征怎么选择,这里选择的方式根据不同的系统,及业务要求,不同,但是,可以肯定的是,选出来的特征值必须满足以下要求:
1.能满足分布式系统的特征,分任务后,任务能独立运行,可扩展性高。
2.能提高系统的性能,和可用性。
学习参考地址:http://www.cnblogs.com/xybaby/p/6930977.html 在此谢谢该作者。