最近淘了个新电脑,想在电脑上装上hadoop等配置环境,折磨了许久,在此,总结下小白式配置步骤,希望能帮助广大编程爱好者。
话不多说。
列出需要下载的文件:
VMware(虚拟机)
CentOS 7.0 (可以自行选择版本)
第一步:在电脑上装VMware,并安装CentOS7.0
1.VMware安装就不说了,一直确认确认确认,输入密钥就OK了。
2.安装CentOS7.0
也很简单,看下下面的教程链接就可以了,这里需要提醒大家一个地方


在软件选择的时候,默认选择的是最小安装。最好是用最小安装,占的内存会小很多。 当然,第一次装CentOS的话可以选择装带有桌面的,体感受下这个桌面的风格。
选择最小安装的话,显示会是这样。

教程链接:
https://www.cnblogs.com/monjeo/p/7680737.html
第二步:配置模板机
hadoop框架,实现大数据,肯定要模拟很多太机器,建立一个集群,这里我们要配置还一台机器作为模板机,然后用VMware的克隆功能,复制多台就OK了。
1,挂载镜像,搭建本地yum仓库,及IP网络配置
由于我们选择的是最小安装,有很多命令在终端是敲不出来的,可以在命令行敲:#:yum list 看看
需要挂载下光盘镜像(下载的CentOS文件)
例如:下面这个就是我的

1.1-选择虚拟机右键选择设置,进行配置。
注意两点:1,设备状态的勾选
2,文件的位置不能错。

1.2在命令行敲这两行代码,进行本地yum源搭建
# mkdir /mnt/cdrom
#mount /dev/cdrom /mnt/cdrom
此时挂载光盘ok了
然后建立本地yum源
命令
#cd /etc/yum.repos.d
#rename .repo .repo.bak *
#cp CentOS-Media.repo.bak CentOS-Media.repo
#vi CentOS-Media.repo
修改如下
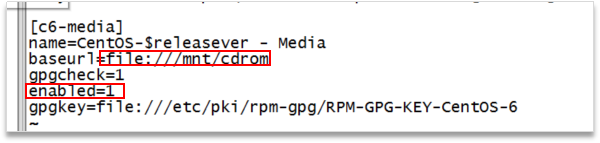
可以再输入# yum list 看看
1.3IP网络配置
这个是细活,别配错了。
首先这里需要点击VMnet上方的编辑,选择虚拟网络编辑器,配置子网和子网掩码。这里需要注意以下几点:1,类型最好是NAT模式,vmnet8的配置不能和vmnet1配置冲突。我配置的就是子网:192.168.9.0 子网掩码:255.255.255.0

设置好子网后再配置ip地址,命令行输入
#vi /etc/sysconfig/network-scripts/ifcfg-eth33(我的网卡是这个ifcfg-eth33,每个人的不一定一样可以自行查看下),然后修改如下。
我得配置如下

注意:这里的IP是在192.168.9.(3-254)都可以 , ONBOOT=yes 一定要配置。
2.设置主机名,配置主机名,映射关系
为了方便集群服务器的管理学习,我们一般会有规律编写主机名。
我的是 主机器名子为:master 其他机器是 slave1,slave2 …
# vi /etc/sysconfig/network
我们目前配置的是主机,先把名字改成master,后面克隆其他机器后,再相应把主机名改了。
配好主机名后,配置映射关系,可添加别名。
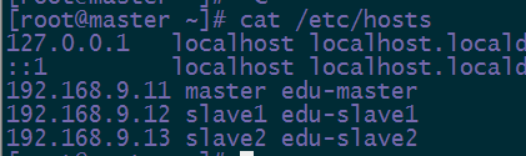
以下是我得配置
192.168.9.11 , 192.168.9.12 , 192.168.9.13 是我给我的三个机器预配的ip地址
master slave1 slave2 是我预配置的主机名 后面是别名。
vi /etc/hosts
3.关闭防火墙
这个简单,敲以下的命令
防火墙的命令:
启动: systemctl start firewalld
关闭: systemctl stop firewalld
查看状态: systemctl status firewalld
开机禁用 : systemctl disable firewalld
开机启用 : systemctl enable firewalld
我们设置
systemctl stop firewalld
systemctl disable firewalld
这两行就可以了。可以查看下状态是否关闭了。
至此 我们的模板机就配置好了。
若不是新建的虚拟机,还需要
直接删除映射关系配置文件,避免mac地址的冲突。(用其他方式也可以,这里就暴力点)

# rm –rf /etc/udev/rules.d/70-persistent-net.rules
建好模板机后,可以设置下快照,当以后的骚操作把系统玩boom了,可以恢复到当前配置。接下来就是克隆了。

4.安装JDK
在wins下远程连接工具,进行控制就行了,
文件在上面的地址中有。

步骤:
1.下载linux jdk 压缩包,上传至/root/apps 下
2.然后 tar -zxvf 包名 解压
3.配置环境变量
命令行
vi /etc/profile
文件末尾加上
export JAVA_HOME=/root/apps/jdk1.8.0_60
export PATH=$PATH:$JAVA_HOME/bin
保存后
source /etc/profile使配置生效 运行java -version 看是否成功执行
第三步:克隆多个机器

跟着指引来,需要注意的:

克隆好后,启动各个虚拟机,,
按之前的配置好主机名和IP地址!
配置好后重启虚拟机,相互之间ping 下看是否能ping的通。 ping不同则配置有问题,需要检查。
能ping后,配置主机免密登录其他机器。
在master机器上执行以下语句
1.#ssh-keygen –t rsa 生成公钥和私钥(需要按三次enter)
2.#ssh-copy-id root@slave1 将公钥拷贝到slave1的root用户上
ssh-copy-id root@slave2 将公钥拷贝到slave2的root用户上
即完成的免密登录
可以ssh slave1 ssh slave2 看看能否登录上 (exit退出)
第四步:安装hdfs集群
1.下载hadoop安装包(hadoop-2.8.5.tar.gz)到master主机的root/apps下
然后执行解压 tar -zxvf hadoop-2.8.5.tar.gz (解压好后可以把share的doc文件夹删了,帮助文档,占空间太多)。
2.修改配置文件(具体各个值的含义,这里就不解释了,太长)
vi hadoop-env.sh
后面加上 export JAVA_HOME=/root/apps/jdk1.8.0_60
再配置
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
再配置
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/root/hdpdata/name/</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/root/hdpdata/data</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>slave1:50090</value>
</property>
</configuration>
再配置
vi /etc/profile
在之前的jdk的路径上修改为以下
export JAVA_HOME=/root/apps/jdk1.8.0_60
export HADOOP_HOME=/root/apps/hadoop-2.8.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
3.拷贝到其他机器上
scp -r /root/apps/hadoop-2.8.5 slave1:/root/apps/
scp -r /root/apps/hadoop-2.8.5 slave2:/root/apps/
scp -r /etc/profile slave1:/etc/profile
scp -r /etc/profile slave2:/etc/profile
4.配置批量启动\关闭namenode
1.在主机master上配置免密登录其他机器(之前已经配置)
2.vi /root/apps/hadoop-2.8.5/etc/hadoop/slaves
在下面加上
master
slave1
slave2
- 启动整个机器
命令行直接输入:
start-dfs.sh(如果要停止,则用脚本:stop-dfs.sh)
4.在每个机器上运行jps 看是否有启动,正常会有以下的东西。
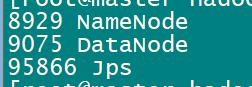
为了在wins上可以识别master主机名,可以配置C:\Windows\System32\drivers\etc、hosts
文件,在后面加上
192.168.9.11 master
192.168.9.12 slave1
192.168.9.13 slave2
在wins下的浏览器输入:hdfs://master:9000 可以看到hadoop网页客户端界面。
当你走到这里的时候,你的hadoop的hdfs配置已经完成了。
hdfs客户端的常用操作命令
1、上传文件到hdfs中
hadoop fs -put /本地文件 /aaa
2、下载文件到客户端本地磁盘
hadoop fs -get /hdfs中的路径 /本地磁盘目录
3、在hdfs中创建文件夹
hadoop fs -mkdir -p /aaa/xxx
4、移动hdfs中的文件(更名)
hadoop fs -mv /hdfs的路径1 /hdfs的另一个路径2
复制hdfs中的文件到hdfs的另一个目录
hadoop fs -cp /hdfs路径_1 /hdfs路径_2
5、删除hdfs中的文件或文件夹
hadoop fs -rm -r /aaa
6、查看hdfs中的文本文件内容
hadoop fs -cat /demo.txt
hadoop fs -tail -f /demo.txt
7.在文件后面追加
Hadoop fs -appendToFile filename 目标文件位置
拓展:
若要在wins下用java远程操作hdfs,需要把hadoop配置文件复制到wins下,并配置HADOOP_HOME变量,
而且,想要下载hdfs的文件到wins下 需要在bin下有这2个文件:
winutils.exe和hadoop.dll .
有需要的留言,以上传至网盘

如果以上对你有帮助,欢迎点个赞,点个关注。